溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“hadoop2.4源碼分析”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
ZKFailoverController是整個HA的協調者。下面我們將分析幾個實際的問題。
1.怎么協調選舉的?怎么選舉出來active的?
2.active宕機后,做了什么事情,如何切換的?
下面,我們來分析第一個問題 怎么協調選舉的?怎么選舉出來active的?
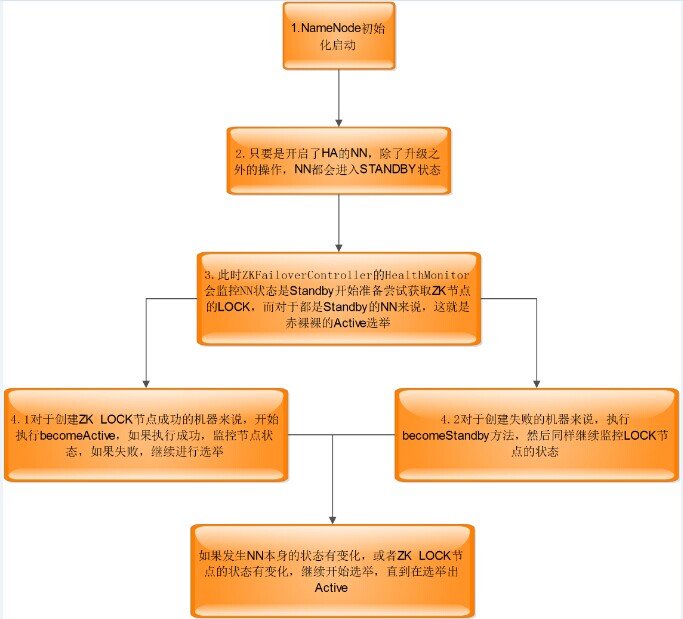
步驟1:參看NameNode源碼,可以看出,對于使用HA的NN來說,進入Standby是必須的。 升級除外
protected HAState createHAState(StartupOption startOpt) {
if (!haEnabled || startOpt == StartupOption.UPGRADE) {
return ACTIVE_STATE;
} else {
return STANDBY_STATE; //standby狀態
}
}步驟2:此時的HealthMonitor監控NN,發現是HEALTH的狀態,會執行:
if (healthy) {
//設置狀態,用于通知回調函數
enterState(State.SERVICE_HEALTHY);
}enterState會通知回調函數,進行處理。對于HEALTH狀態的開始執行選舉方法。
elector.joinElection(targetToData(localTarget));
通過創建零時節點,來搶占節點,獲取Active
createLockNodeAsync();
對于創建節點,會觸發ZK的EVENT時間。
對于事件的處理,見源碼部分:
public synchronized void processResult(int rc, String path, Object ctx,
String name) {
if (isStaleClient(ctx)) return;
LOG.debug("CreateNode result: " + rc + " for path: " + path
+ " connectionState: " + zkConnectionState +
" for " + this);
Code code = Code.get(rc);//為了方便使用,這里自定義了一組狀態
if (isSuccess(code)) {//成功返回,成功創建zklocakpath節點
// we successfully created the znode. we are the leader. start monitoring
if (becomeActive()) {//要將本節點上的NN變成active
monitorActiveStatus();//繼續監控節點狀態
} else {
reJoinElectionAfterFailureToBecomeActive();//失敗,繼續選舉嘗試
}
return;
}
if (isNodeExists(code)) {//節點存在,說明已經有active,wait即可
if (createRetryCount == 0) {
// znode exists and we did not retry the operation. so a different
// instance has created it. become standby and monitor lock.
becomeStandby();
}
// if we had retried then the znode could have been created by our first
// attempt to the server (that we lost) and this node exists response is
// for the second attempt. verify this case via ephemeral node owner. this
// will happen on the callback for monitoring the lock.
monitorActiveStatus();//不過努力成為active的動作不能停
return;
}
String errorMessage = "Received create error from Zookeeper. code:"
+ code.toString() + " for path " + path;
LOG.debug(errorMessage);
if (shouldRetry(code)) {
if (createRetryCount < maxRetryNum) {
LOG.debug("Retrying createNode createRetryCount: " + createRetryCount);
++createRetryCount;
createLockNodeAsync();
return;
}
errorMessage = errorMessage
+ ". Not retrying further znode create connection errors.";
} else if (isSessionExpired(code)) {
// This isn't fatal - the client Watcher will re-join the election
LOG.warn("Lock acquisition failed because session was lost");
return;
}
fatalError(errorMessage);
}對于獲取Active的機器,調用becomeActive()方法
private synchronized void becomeActive() throws ServiceFailedException {
LOG.info("Trying to make " + localTarget + " active...");
try {
HAServiceProtocolHelper.transitionToActive(localTarget.getProxy(
conf, FailoverController.getRpcTimeoutToNewActive(conf)),
createReqInfo());
String msg = "Successfully transitioned " + localTarget +
" to active state";
LOG.info(msg);
serviceState = HAServiceState.ACTIVE;
recordActiveAttempt(new ActiveAttemptRecord(true, msg));
} catch (Throwable t) {
String msg = "Couldn't make " + localTarget + " active";
LOG.fatal(msg, t);
recordActiveAttempt(new ActiveAttemptRecord(false, msg + "\n" +
StringUtils.stringifyException(t)));
if (t instanceof ServiceFailedException) {
throw (ServiceFailedException)t;
} else {
throw new ServiceFailedException("Couldn't transition to active",
t);
}通過對RPC進過一系列的調用,最終執行NameNode的
synchronized void transitionToActive()
throws ServiceFailedException, AccessControlException {
namesystem.checkSuperuserPrivilege();
if (!haEnabled) {
throw new ServiceFailedException("HA for namenode is not enabled");
}
state.setState(haContext, ACTIVE_STATE);
}OVER
2.active宕機后,做了什么事情,如何切換的?
active宕機后或者異常會導致ZK節點的消失或監控狀態的UNHEALTH,這些都會導致新一輪的選舉,原理同上。
“hadoop2.4源碼分析”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





