溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天給大家介紹一下K-means聚類中的Kmeans Clustering該如何理解。文章的內容小編覺得不錯,現在給大家分享一下,覺得有需要的朋友可以了解一下,希望對大家有所幫助,下面跟著小編的思路一起來閱讀吧。
Kmeans算法是將一些雜亂無章的數,分為若干個類的一種聚類方法
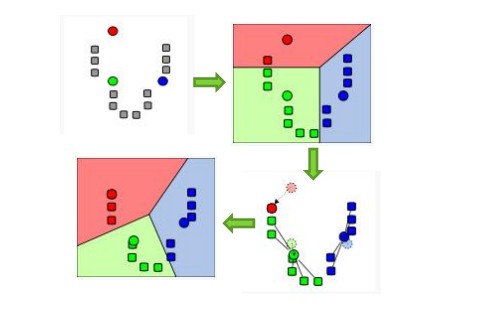
算法步驟:(k表示聚類中心的個數,上圖為3)
(1)隨機選取任意k個對象作為初始聚類中心,初始代表一個簇;
(2)計算點到質心的距離,并把它歸到最近的質心的類;
(3)重新計算已經得到的各個類的質心;
(4)迭代2~3步直至新的質心與原質心相等或小于指定閾值,算法結束。
K-means算法的優缺點:
1.效果好,不易受初始值得影響
2.不能處理非球形的簇
3.不能處理不同尺寸,不同密度的簇
4.容易受孤立點的影響(需要我們人為干預,進行剔除)
常用的距離算法:
1.歐幾里得距離

2.余弦相似度

以上就是K-means聚類中的Kmeans Clustering該如何理解的全部內容了,更多與K-means聚類中的Kmeans Clustering該如何理解相關的內容可以搜索億速云之前的文章或者瀏覽下面的文章進行學習哈!相信小編會給大家增添更多知識,希望大家能夠支持一下億速云!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





