溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Hadoop2.2.0集群在RHEL6.2下如何安裝,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
本次集群搭建過程中,主要遇到兩個問題:
(1)第一個是:DataNode啟動了(使用jps可以看到進程),但是在NameNode中看不到(192.168.1.10:50070),花費大約3個小時時間查問題,根據logs目錄的日志“org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.1.10:9000”,到百度搜索,有人遇到說是防火墻沒關的問題,但是我的防火墻都關了。最后多種方式嘗試,原來是/etc/hosts中,對于master除了對應到192.168.1.10之外,我還對應到了127.0.0.1,去掉之后,重新啟動,就都好了。
(2)第二個是:常見問題,多次format namecode造成的DataNode不啟動,刪除/home/hadoop/dfs/data/current/VERSION就好了。
(3)多看日志,總能解決
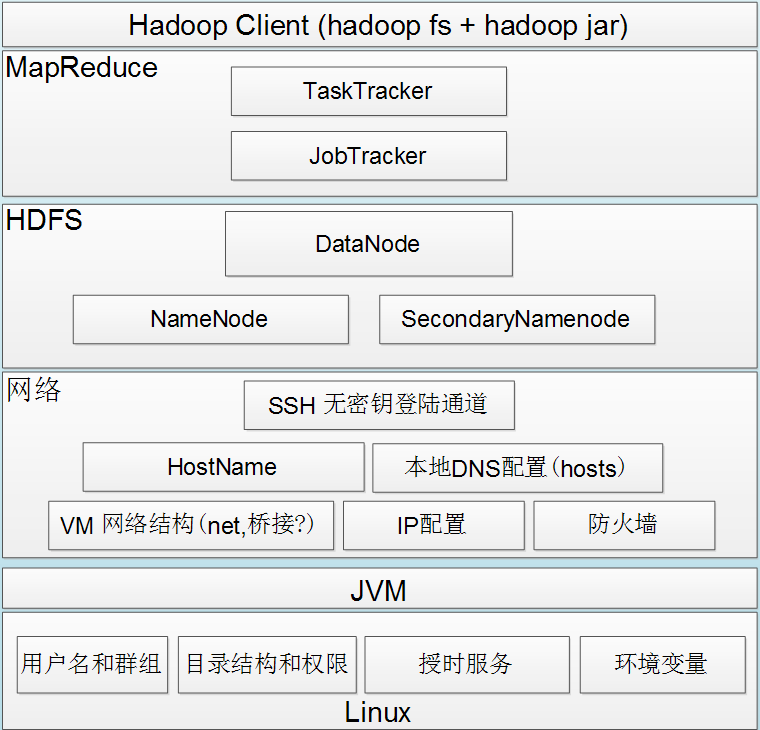
Hadoop是什么
Hadoop是Lucene創始人Doug Cutting,根據Google的相關內容山寨出來的分布式文件系統和對海量數據進行分析計算的基礎框架系統,其中包含MapReduce程序,hdfs系統等。
名詞解釋
(1)Hadoop:Apache開源的分布式框架。
(2)HDSF:Hadoop的分布式文件系統。
(3)NameNode:Hadoop HDFS元數據主節點服務器,負責保存DataNode 文件存儲元數據信息,這個服務器是單點的。
(4)JobTracker:Hadoop的Map/Reduce調度器,負責與TaskTracker通信分配計算任務并跟蹤任務進度,這個服務器也是單點的。
(5)DataNode:Hadoop數據節點,負責存儲數據。
(6)TaskTracker:Hadoop調度程序,負責Map,Reduce任務的啟動和執行。
Hadoop1的集群部署結構圖
20140412225748359.jpg (50.6 KB, 下載次數: 0)
下載附件 保存到相冊
6 天前 上傳
Hadoop2的Yarn架構圖
20140413085324421.jpg (183.81 KB, 下載次數: 0)
下載附件 保存到相冊
6 天前 上傳
安裝RHEL環境
使用VMWare WorkStation安裝虛擬機:
http://blog.csdn.net/puma_dong/article/details/17889593#t0
http://blog.csdn.net/puma_dong/article/details/17889593#t1
安裝Java環境:
http://blog.csdn.net/puma_dong/article/details/17889593#t10
安裝完畢之后,4臺虛擬機IP及機器名稱如下:
192.168.1.10 master
192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3
可以通過vim /etc/hosts查看。注意:在/etc/hosts中,不要把機器名字,同時對應到127.0.0.1這個地址,會導致數據節點連接不上命名節點,報錯如下:
org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.1.10:9000
安裝完畢之后,Java位置如下:/usr/jdk1.6.0_45 ,可以通過echo $JAVA_HOME查看。
配置Hadoop環境
創建Hadoop賬號
(1)創建Hadoop用戶組:groupadd hadoop
(2)創建Hadoop用戶:useradd hadoop -g hadoop
(3)設置Hadoop用戶密碼:passwd 密碼hadoop
(4)給hadoop賬戶增加sudo權限: vim /etc/sudoers ,增加內容:hduser ALL=(ALL) ALL
注意:以上對于每一臺機器都要執行
創建master到slave的無密碼登錄
(1)切換到Hadoop 用戶下:su hadoop cd /home/hadoop/
(2)生成公鑰和私鑰:ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsa
(3)查看密鑰內容:cd /home/hadoop/.ssh cat id_rsa.pub
(4)復制id_rsa.pub公鑰到 authorized_keys 文件:cat id_rsa.pub > authorized_keys
(5)修改master公鑰權限:chmod 644 /home/hadoop/.ssh/authorized_keys
(6)把 master 機器上的 authorized_keys 文件 copy 到 node1 節點上:
scp /home/hadoop/.ssh/authorized_keys node1:/home/hadoop/.ssh/
如果node1/node2/node3機器上沒有.ssh目錄,則創建,并chmod 700 /home/hadoop/.ssh
安裝Hadoop
安裝目錄
Hadoop安裝目錄:/home/hadoop/hadoop-2.2.0
文件目錄:/home/hadoop/dfs/name ,/home/hadoop/dfs/data ,/home/hadoop/tmp
安裝步驟
注意:以下步驟使用hadoop賬號操作。
(1)轉到 home/hadoop目錄:cd /home/hadoop
(2)下載hadoop:wget http://mirror.esocc.com/apache/h ... hadoop-2.2.0.tar.gz
(3)解壓hadoop并放到計劃安裝位置:tar zxvf hadoop-2.2.0.tar.gz
(4)創建文件目錄:mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp
(5)修改7個配置文件,文件位置:/home/hadoop/hadoop-2.2.0/etc/hadoop/,文件名稱:hadoop-env.sh、yarn-evn.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
配置文件hadoop-env.sh
如果系統環境變量有設置$JAVA_HOME,則這個文件不用修改,否則要修改${JAVA_HOME}為:/usr/jdk1.6.0_45
配置文件yarn-env.sh
如果系統環境變量有設置$JAVA_HOME,則這個文件不用修改,否則要修改${JAVA_HOME}為:/usr/jdk1.6.0_45
配置文件slaves
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/slaves,修改內容為所有的DataNode的機器名字,每個機器一行,這篇文章的配置如下:
node1
node2
node3
配置文件core-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/core-site.xml,修改configuration內容如下:
fs.defaultFShdfs://master:9000io.file.buffer.size131072hadoop.tmp.dirfile:/home/hadoop/tmpAbase for other temporary directories.
配置文件hdfs-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/hdfs-site.xml,修改configuration內容如下:
dfs.namenode.secondary.http-addressmaster:9001dfs.namenode.name.dirfile:/home/hadoop/dfs/namedfs.datanode.data.dirfile:/home/hadoop/dfs/datadfs.replication3dfs.webhdfs.enabledtrue
配置文件mapred-site.xml
mv /home/hadoop/hadoop-2.2.0/etc/hadoop/mapred-site.xml.template /home/hadoop/hadoop-2.2.0/etc/hadoop/mapred-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/mapred-site.xml,修改configuration內容如下:
mapreduce.framework.nameyarnmapreduce.jobhistory.addressmaster:10020mapreduce.jobhistory.webapp.addressmaster:19888
配置節點yarn-site.xml
vim /home/hadoop/hadoop-2.2.0/etc/hadoop/yarn-site.xml,修改configuration內容如下:
yarn.nodemanager.aux-servicesmapreduce_shuffleyarn.nodemanager.aux-services.mapreduce.shuffle.classorg.apache.hadoop.mapred.ShuffleHandleryarn.resourcemanager.addressmaster:8032yarn.resourcemanager.scheduler.addressmaster:8030yarn.resourcemanager.resource-tracker.addressmaster:8031yarn.resourcemanager.admin.addressmaster:8033yarn.resourcemanager.webapp.addressmaster:8088
復制Hadoop到其他節點
(1)scp -r /home/hadoop/hadoop-2.2.0 hadoop@node1:~/
(2)scp -r /home/hadoop/hadoop-2.2.0 hadoop@node2:~/
(3)scp -r /home/hadoop/hadoop-2.2.0 hadoop@node3:~/
啟動Hadoop
(1)切換到hadoop用戶:su hadoop
(2)進入安裝目錄: cd ~/hadoop-2.2.0/
(3)格式化namenode:./bin/hdfs namenode –format
(4)啟動hdfs: ./sbin/start-dfs.sh
(5)jps查看,此時master有進程:NameNoce SecondaryNameNode,node1/node2/node3上有進程:DataNode
(6)啟動yarn: ./sbin/start-yarn.sh
(7)jps查看,此時master有進程:NameNoce SecondaryNameNode ResourceManager,node1/node2/node3上有進程:DataNode NodeManager
(8)查看集群狀態:./bin/hdfs dfsadmin -report
(9)查看文件塊組成: ./bin/hdfs fsck / -files -blocks
(10)Web查看HDFS: http://192.168.1.10:50070
(11)Web查看RM: http://192.168.1.10:8088
HADOOP_HOME環境變量
在運行方便,我們設置一個HADOOP_HOME環境變量,并加入PATH目錄,步驟如下:
(1)vim /etc/profile.d/java.sh #因為hadoop必用java,所有我們把使用這個文件即可。
(2)增加內容:
export HADOOP_HOME=/home/hadoop/hadoop-2.2.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
運行Hadoop計算任務
WordCount
(1)/home/hadoop目錄下有兩個文本文件file01.txt和file02.txt,文件內容分別為:
file01.txt:
kongxianghe
kong
yctc
Hello World
file02.txt:
11
2222
kong
Hello
yctc
(2)將這兩個文件放入hadoop的HDFS中:
hadoop fs -ls //查看hdfs目錄情況
hadoop fs -mkdir -p input
hadoop fs -put /home/hadoop/file*.txt input
hadoop fs -cat input/file01.txt //查看命令
(3)計算并查看結果:
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount input output
hadoop fs -ls output
hadoop fs -cat output/part-r-00000
可以看到數據都已經被統計出來了。
運行排序計算
如下的這個程序,會現在每個節點生成10個G的隨機數字,然后排序出結果:
(1)./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar randomwriter rand
(2)./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar sort rand sort-rand
第一個命令會在rand 目錄的生成沒有排序的數據。第二個命令會讀數據,排序,然后寫入rand-sort 目錄。
常見錯誤
(1)Name node is in safe mode
運行hadoop程序時, 異常終止了,然后再向hdfs加文件或刪除文件時,出現Name node is in safe mode錯誤:
rmr: org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode
解決的命令:
hadoop dfsadmin -safemode leave #關閉safe mode
(2)DataNode 無法啟動
我遇到過兩種情況的DataNode無法啟動:第一種是/etc/hosts里面機器名字除了和IP對應之外,還和127.0.0.1對應,導致DataNode連接NameNode的9000端口一直連接不上;第二種是多次format namenode 造成namenode 和datanode的clusterID不一致,通過查看NameNode和DataNode的/home/hadoop/dfs/data/current/VERSION,發現確實不一致。
以上是“Hadoop2.2.0集群在RHEL6.2下如何安裝”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





