溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Hive動態分區表的作用是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Hive動態分區表的作用是什么”吧!
1.對于分區數量很多的分區表,可以使用動態分區讓hive幫你自動創建所需的分區表:

以上兩個參數分別表示:
是否開啟動態分區插入方式,默認為false;
是否使用嚴格模式。在嚴格模式下,必須至少指定一個靜態列,以防止用戶不小心一次重寫了所有分區。
如果使用非嚴格模式,則插入的時候需要指定一個額外的數據列來表示虛擬分區列的值,如:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; create table test1(a int); create table test2(a int) partitioned by (parid int); insert into table test2 partition (parid) select *,par_id from test1;
否則會出現類似如下錯誤:
Error: Error while processing statement: FAILED: SemanticException [Error 10044]: Line 1:18 Cannot insert into target table because column number/types are different 'parid': Table insclause-0 has 2 columns, but query has 1 columns. (state=42000,code=10044)
最后執行命令:hdfs dfs -ls /user/hive/warehouse/test2,便可查看到hdfs中自動創建好了分區文件夾。
注意:
使用過程中發現hive的insert及alter語法不夠靈活,如不支持insert into..values..、不支持alter table test add partition(parid int)等等。另外,關于Load data語法的使用,目前是不支持動態分區的。現在對數據類型的支持也在逐漸完善中,如date及timestamp類型都在最近的版本得到支持。
更多關于hive分區表的介紹參見:hive中簡單介紹分區表(partition table),含動態分區(dynamic partition)與靜態分區(static partition)
hive1的連接命令是:su -c hive hdfs
hive2添加了新的client:beeline -u jdbc:hive2://localhost/ -n hive
beeline還提供了一些內置命令,使用“!help”或者“?”可以查看。此外,beeline的交互性也更強,比如錯誤提示和數據展示都更加友好。
2.上面簡單介紹了hive動態分區表的使用,接下來的一個小demo是使用Java連接hive。hive不等同于關系型數據庫,本身不存儲數據也不提供對數據的操作方法,如果要使用jdbc連接hive,必須啟動了hive-server,默認連接端口是10000。代碼如下所示:
private static void hive() throws Exception {
// Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver");
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection con = DriverManager.getConnection("jdbc:hive2://127.0.0.1:10000/default", "hive", "");
PreparedStatement ps = con.prepareStatement("insert into table test select ? from test2 limit 1");
ps.setString(1, new Timestamp(new java.util.Date().getTime()).toString());
ps.executeUpdate();
ps.setString(1, "2011-11-11 11:11:11");
ps.executeUpdate();
// stmt.execute("set hive.support.concurrency=true");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("select * from test");
int columnSize = rs.getMetaData().getColumnCount();
while (rs.next()) {
for (int i = 1; i <= columnSize; i++)
System.out.print(rs.getString(i) + ",");
System.out.println();
}
rs.close();
stmt.close();
con.close();
}注意:
以上代碼中注釋的部分是在hive1中使用的。hive1不支持并發操作,jdbc驅動也不一致。另外,關于所需的jar包分別如下圖所示:
Hiveserver1: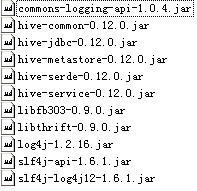
Hiveserver2: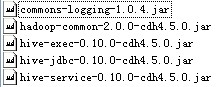 或
或
上面hive2使用的是CDH4的hadoop包,其中的hive-exec-0.10.0-cdh5.5.0.jar是一個整合包,亦可使用最右邊的包替換。hive兩個版本的jdbc驅動包也不一致。如果使用標準hadoop包的話還需要更多依賴包,否則可能會因為hadoop RPC協議不一致而報如下錯誤:
Caused by: org.apache.thrift.protocol.TProtocolException: Required field 'serverProtocolVersion' is unset! Struct:TOpenSessionResp(status:TStatus(statusCode:SUCCESS_STATUS), serverProtocolVersion:null, sessionHandle:TSessionHandle(sessionId:THandleIdentifier(guid:A0 3F 2D 35 DD BD 47 6C 80 B6 36 83 1A DB 60 4C, secret:F6 13 B5 E3 20 65 48 F5 9A F4 0F 04 A2 FC 30 B2)), configuration:{})
若不是使用CDH包報錯:Could not locate executable null\bin\winutils.exe in the Hadoop binaries。則替換hadoop-common為最新的包,參考:https://issues.cloudera.org/browse/DISTRO-544,Win7 Eclipse調試Centos Hadoop2.2-Mapreduce
目前hive提供的jdbc包功能還比較弱,比如:不支持Statement的批量操作相關的方法,包括addBatch()、batchUpdate()以及其子類Preparestatement的setObject()、setNull()等方法,Connection對象不支持事務相關的操作,如setAutoCommit()、rollback()等,ResultSet的滾動相關操作如getRows()、first()等等,雖然hive支持事務,但是在API中只能通過程序控制來實現。此外,測試發現insert操作數據插入的效率極其低下,當然這也與hive本身的工作模式有關。
到此,相信大家對“Hive動態分區表的作用是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





