溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Lucene索引過程是怎樣的”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Lucene索引過程是怎樣的”吧!
Lucene 總的來說是:
一個高效的,可擴展的,全文檢索庫。
全部用 Java 實現,無須配置。
僅支持純文本文件的索引(Indexing)和搜索(Search)。
不負責由其他格式的文件抽取純文本文件,或從網絡中抓取文件的過程。
在 Lucene in action 中,Lucene 的構架和過程如下圖,
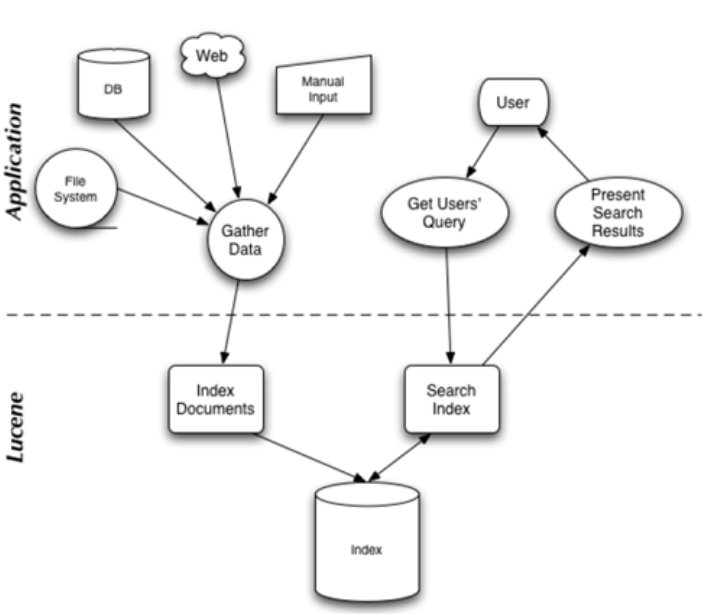
說明 Lucene 是有索引和搜索的兩個過程,包含索引創建,索引,搜索三個要點。
讓我們更細一些看 Lucene 的各組件:
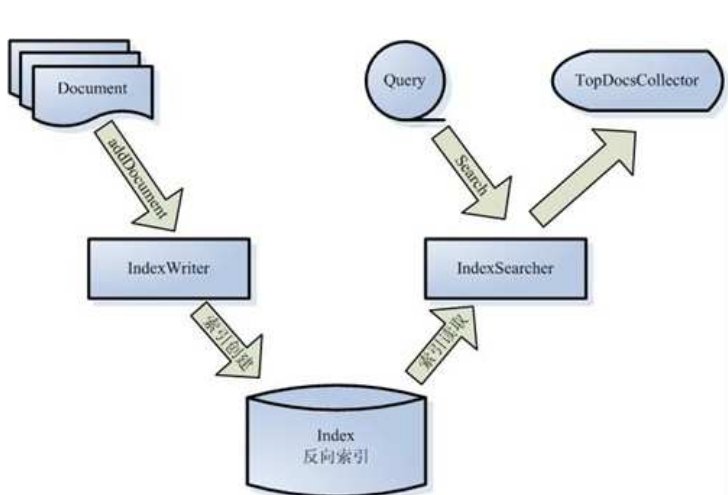
被索引的文檔用 Document 對象表示。
IndexWriter 通過函數 addDocument 將文檔添加到索引中,實現創建索引的過程。
將文檔添加到索引中,實現創建索引的過程。
Lucene 的索引是應用反向索引。
當用戶有請求時,Query 代表用戶的查詢語句。
IndexSearcher 通過函數 search 搜索 Lucene Index。
IndexSearcher 計算 term weight 和 score 并且將結果返回給用戶。
返回給用戶的文檔集合用 TopDocsCollector 表示。
那么如何應用這些組件呢?
讓我們再詳細到對 Lucene API 的調用實現索引和搜索過程。
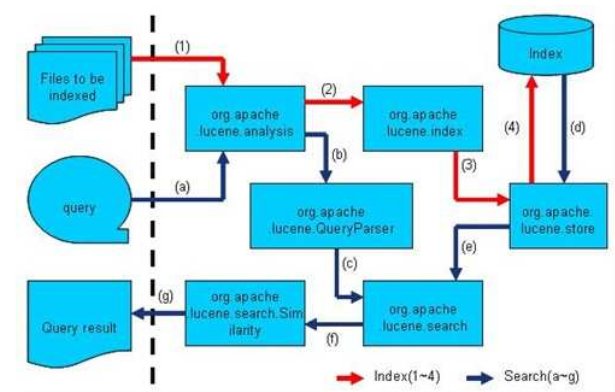
Lucene 的 analysis 模塊主要負責詞法分析及語言處理而形成 Term。。
Lucene 的 index 模塊主要負責索引的創建,里面有 IndexWriter。
Lucene 的 store 模塊主要負責索引的讀寫。
Lucene 的 QueryParser 主要負責語法分析。
Lucene 的 search 模塊主要負責對索引的搜索。
Lucene 的 similarity 模塊主要負責對相關性打分的實現。
到此,相信大家對“Lucene索引過程是怎樣的”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





