溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
導讀:數據總線DBus的總體架構中主要包括六大模塊,分別是:日志抓取模塊、增量轉換模塊、全量抽取程序、日志算子處理模塊、心跳監控模塊、Web管理模塊。六大模塊各自的功能相互連接,構成DBus的工作原理:通過讀取RDBMS增量日志的方式來實時獲取增量數據日志(支持全量拉取);基于Logstash,flume,filebeat等抓取工具來實時獲得數據,以可視化的方式對數據進行結構化輸出。本文主要介紹的是DBus中基于可視化配置的日志結構化轉換實現的部分。
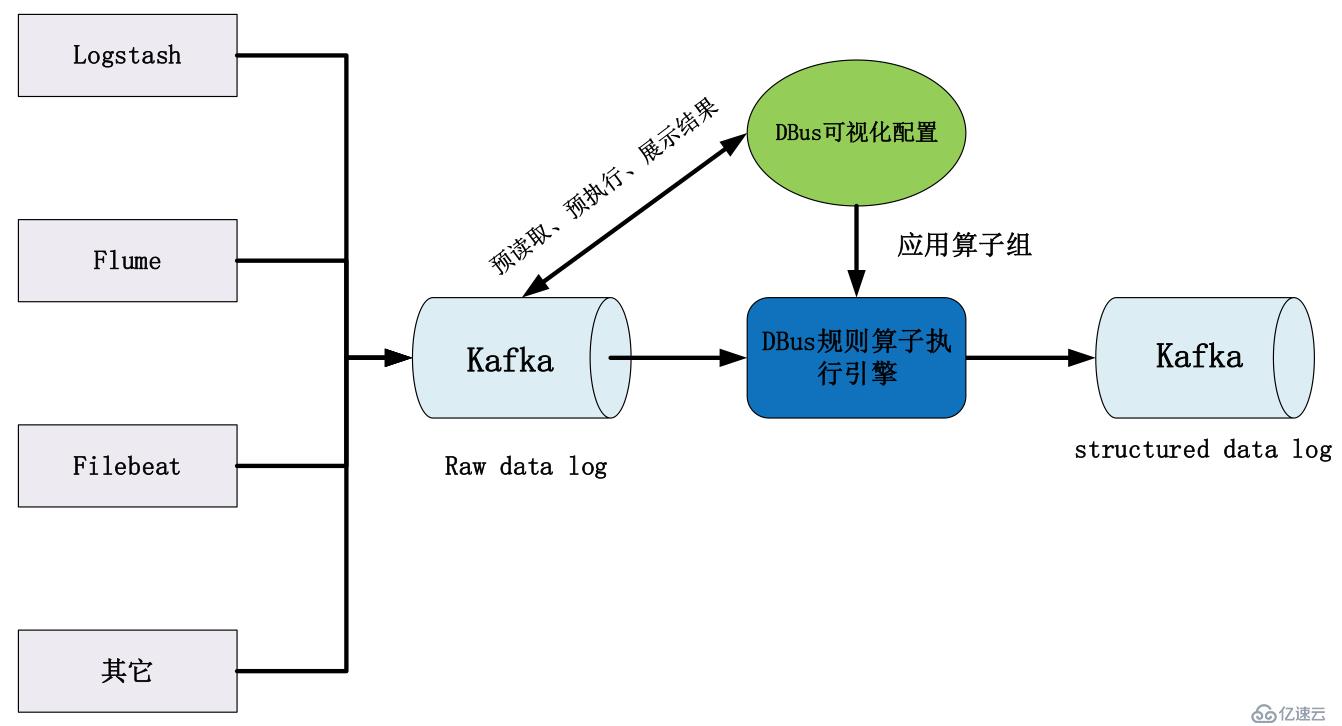
DBus可以對接多種log數據源,例如:Logstash、Flume、Filebeat等。上述組件都是業界比較流行的日志抓取工具,一方面便于用戶和業界統一標準,方便用戶技術方案的整合;另一方面也避免了無謂的重復造輪子。抓取的數據我們稱為原始數據日志(raw data log),由抓取組件將其寫入Kafka中,等待DBus后續處理。
用戶可自定義配置日志源和目標端。同一個日志源的數據可以輸出到多個目標端。每一條“日志源-目標端”線,用戶可以根據自己的需要來配置相應的過濾規則。經過規則算子處理后的日志是結構化的,即:有schema約束,類似于數據庫中的表。
DBus設計了豐富易用的算子,用于對數據進行定制化操作。用戶對數據的處理可分為多個步驟進行,每個步驟的數據處理結果可即時查看、驗證;并且可重復使用不同算子,直到轉換、裁剪出自己需要的數據。
將配置好的規則算子組應用到執行引擎中,對目標日志數據進行預處理,形成結構化數據,輸出到Kafka,供下游數據使用方使用。系統流程圖如下所示:
根據DBus log設計原則,同一條原始日志,可以被提取到一個或多個表中。每個表是結構化的,滿足相同的schema約束。
對于任意一條原始數據日志(raw data log),它應該屬于哪張表呢?
假如用戶定義了若干張邏輯表(T1,T2…),用于抽取不同類型的日志,那么,每條日志需要與規則算子組進行匹配:
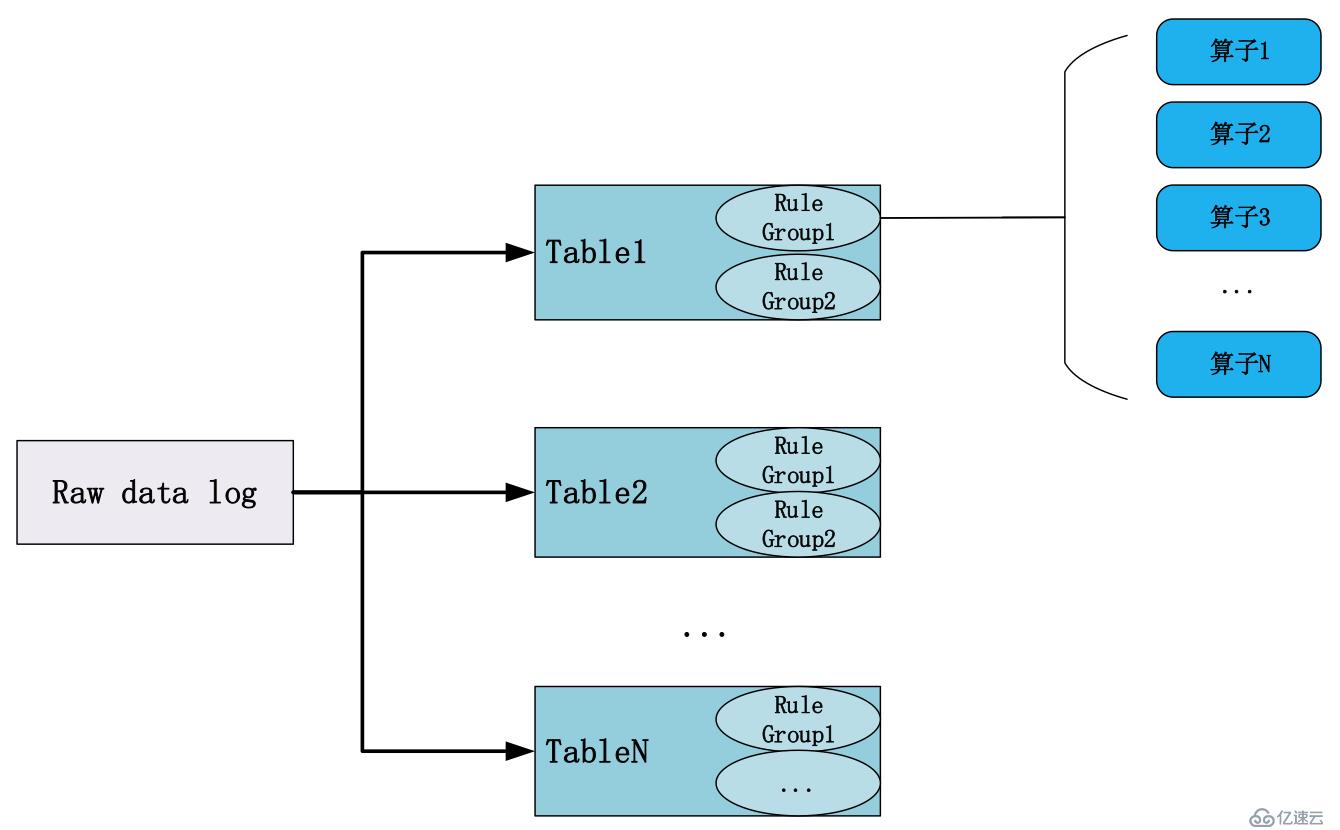
例如,對于同一條應用日志,其可能屬于不止一個規則組或Table,而在我們定義的規則組或Table中,只要其滿足過濾條件,該應用日志就可以被規則組提取,即保證了同一條應用日志可以同屬于不同的規則組或Table。

規則算子是對數據進行過濾、加工、轉換的基本單元。常見的規則算子如上圖所示。
算子之間具有獨立性,算子之間可以任意組合使用,從而可以實現許多復雜的、高級的功能,通過對算子進行迭代使用,最終可以實現對任意數據進行加工的目的。用戶可以開發自定義算子,算子的開發非常容易,用戶只要遵循基本接口原則,就可以開發任意的算子。
以DBus集群環境為例,DBus集群中有兩臺機器(即master-slave)部署了心跳程序,用于監控、統計、預警等,心跳程序會產生一些應用日志,這些應用日志中包含各類事件信息,假如我們想要對這些日志進行分類處理并結構化到數據庫中,我們就可以采用DBus log程序對日志進行處理。
DBus可以接入多種數據源(Logstash、Flume、Filebeat等),此處以Logstash為例來說明如何接入DBus的監控和報警日志數據。
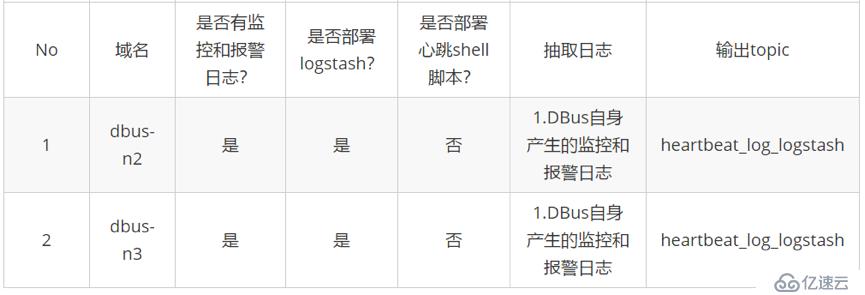
由于在dbus-n2和dbus-n3兩臺機器上分別存在監控和預警日志,為此我們分別在兩臺機器上部署了Logstash程序。心跳數據由Logstash自帶的心跳插件產生,其作用是便于DBus對數據進行統計和輸出,以及對源端日志抽取端(此處為Logstash)進行預警(對于Flume和Filebeat來說,因為它們沒有心跳插件,所以需要額外為其定時產生心跳數據)。Logstash程序寫入到Kafka中的數據中既有普通格式的數據,同時也有心跳數據。
這里不只是局限于2臺部署有Logstash程序的機器,DBus對Logstash數量不做限制,比如應用日志分布在幾十上百臺機器上,只需要在每臺機器上部署Logstash程序,并將數據統一抽取到同一個Kafka Topic中,DBus就能夠對所有主機的數據進行數據處理、監控、預警、統計等。
在啟動Logstash程序后,我們就可以從topic : heartbeat_log_logstash中讀取數據,數據樣例如下:
1)心跳數據
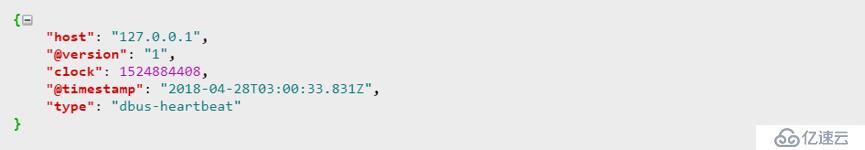
2)普通日志數據

接下來,我們只需要在DBus Web中配置相應的規則就可以對數據進行處理了。
首先新建一個邏輯表sink_info_table,該表用來抽取sink事件的日志信息,然后配置該表的規則組(一個或多個,但所有的規則組過濾后的數據需要滿足相同schema特性),heartbeat_log_logstash作為原始數據topic,我們可以實時的對數據進行可視化操作配置(所見即所得,即席驗證)。

1)讀取原始數據日志
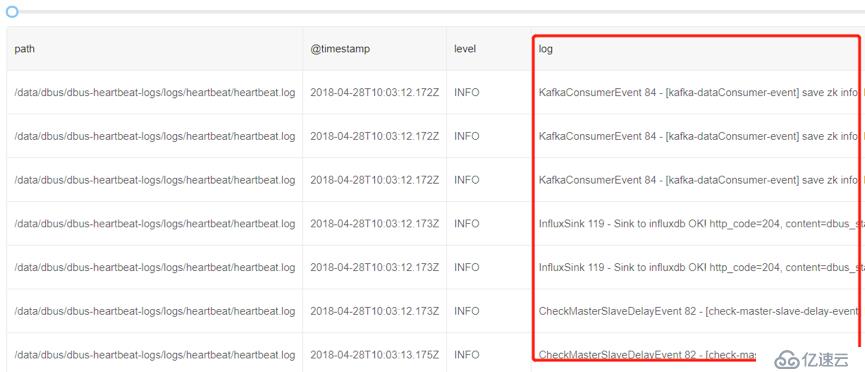
可以看到由Logstash預先提取已經包含了log4j的基本信息,例如path、@timestamp、level等。但是數據日志的詳細信息在字段log中。由于不同的數據日志輸出是不一樣的,因此可以看到log列數據是不同的。
2)提取感興趣的列
假如我們對timestamp、log 等原始信息感興趣,那么可以添加一個toIndex算子,來提取這些字段:
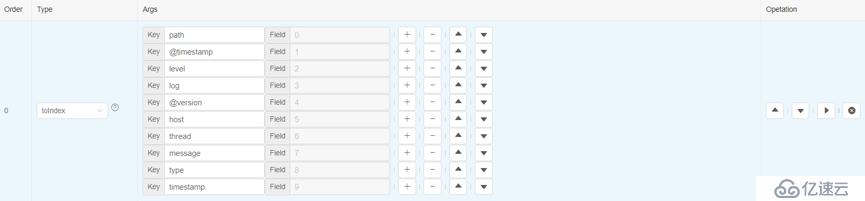
這里需要指出,我們考慮使用數組下標方式,是有原因的:
執行規則,就可以看到被提取后的字段情況:
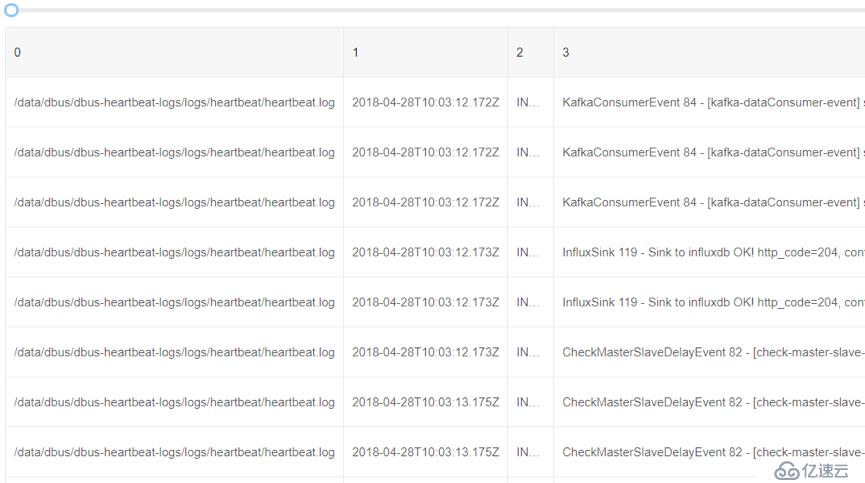
3)過濾需要的數據
在這個例子中,我們只對含有“Sink to influxdb OK!”的數據感興趣。因此添加一個filter算子,提取第7列中包含”Sink to influxdb OK!”內容的行數據:
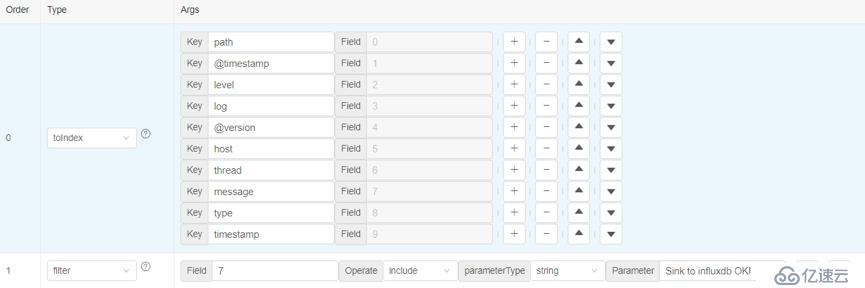
執行后,只有符合條件的日志行數據才會存在。

4)對特定列進行提取
添加一個select算子,我們對第1和3列的內容感興趣,所以對這兩列進行提取。
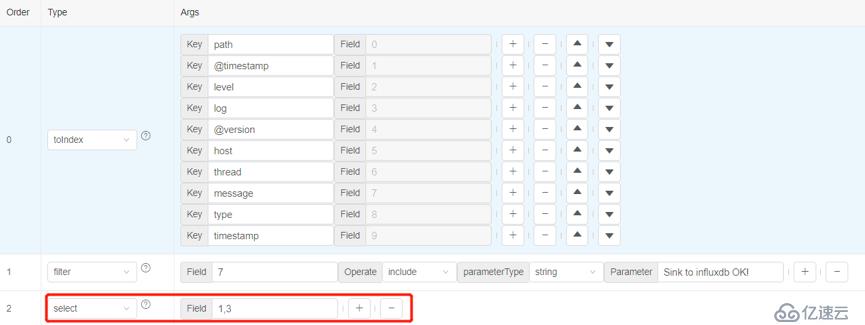
執行select算子,數據中就會只含有第1和3列了。
5)以正則表達式的方式處理數據
我們想從第1列的數據中提取符合特定正則表達式的值,使用regexExtract算子對數據進行過濾。正則表達式如下:http_code=(\d*).*type=(.*),ds=(.*),schema=(.*),table=(.*)\s.*errorCount=(\d*),用戶可以寫自定義的正則表達式。
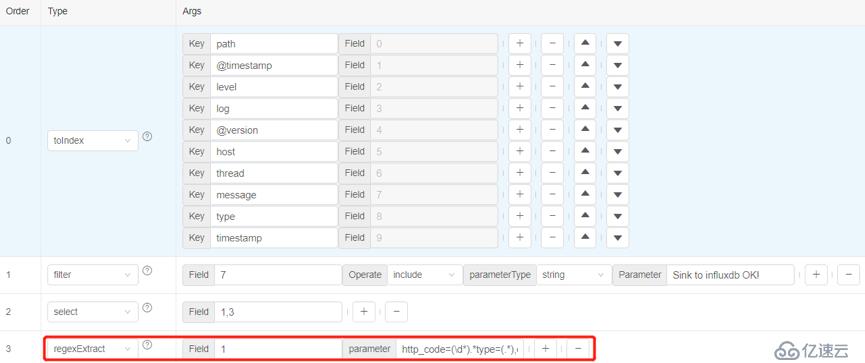
執行后,就會獲取正則表達式執行后的數據。

6)選擇輸出列
最后我們把感興趣的列進行輸出,使用saveAs算子, 指定列名和類型,方便于保存在關系型數據庫中。
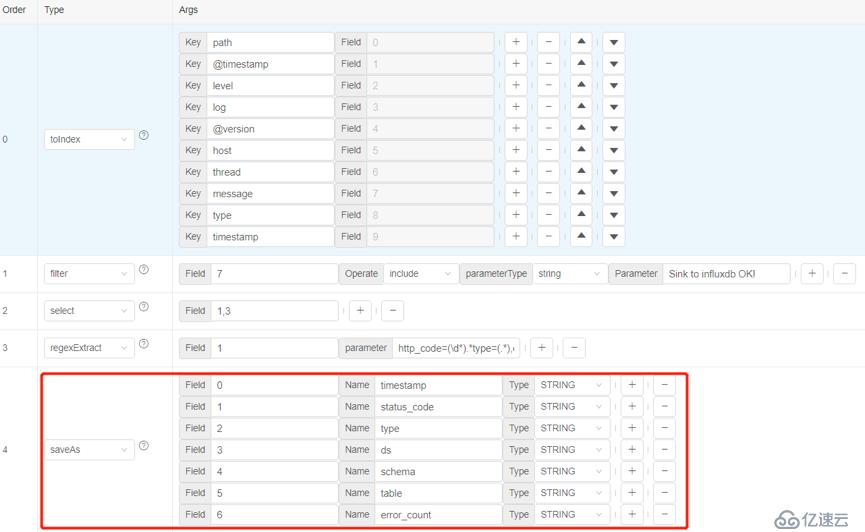
執行saveAs算子后,這就是處理好的最終輸出數據樣本。
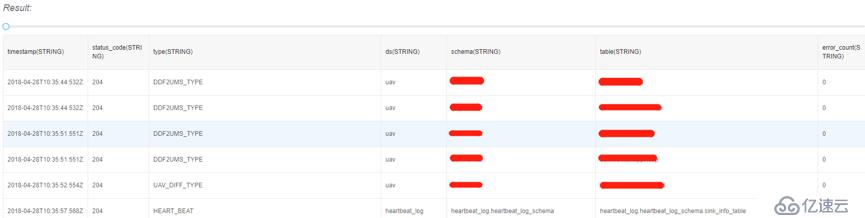
保存上一步配置好的規則組,日志數據經過DBus執行算子引擎,就可以生成相應的結構化數據了。目前根據項目實際,DBus輸出的數據是UMS格式,如果不想使用UMS,可以經過簡單的開發,實現定制化。
注:UMS是DBus定義并使用的、通用的數據交換格式,是標準的JSON。其中同時包含了schema和數據信息。更多UMS介紹請參考DBus開源項目主頁的介紹。開源地址:https://github.com/bridata/dbus
以下是測試案例,輸出的結構化UMS數據的樣例:

為了便于掌握數據抽取、規則匹配、監控預警等情況,我們提供了日志數據抽取的可視化實時監控界面,如下圖所示,可隨時了解以下信息:
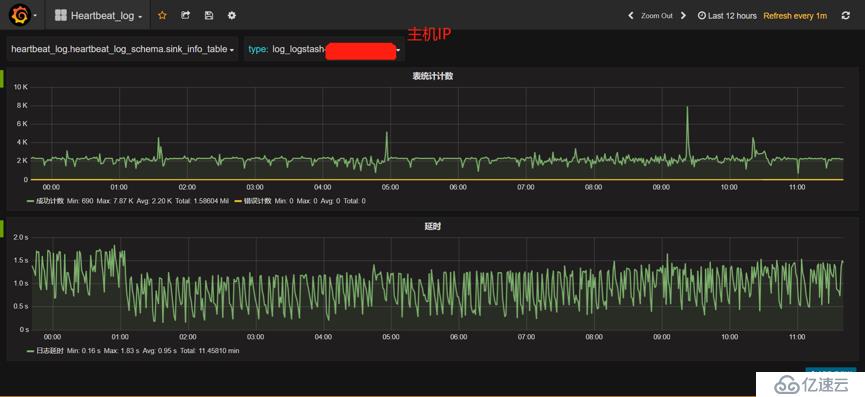
監控信息中包含了來自集群內各臺主機的監控信息,以主機IP(或域名)對數據分別進行監控、統計和預警等。
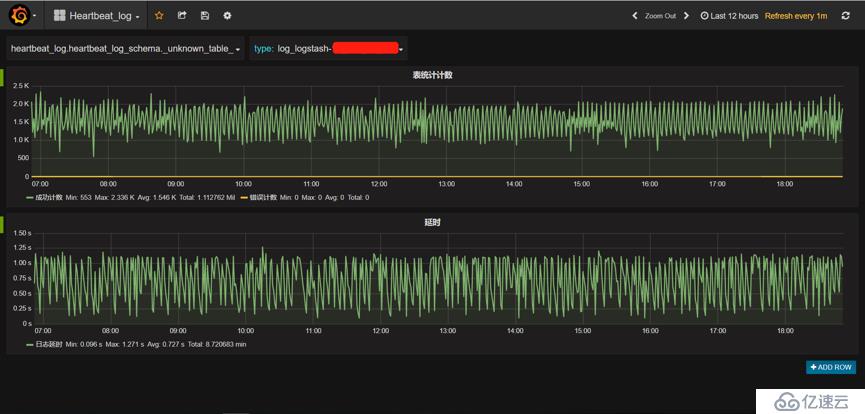
監控中還有一張表叫做_unkown_table_ 表明所有沒有被匹配上的數據條數。例如:Logstash抓取的日志中有5種不同事件的日志數據,我們只捕獲了其中3種事件,其它沒有被匹配上的數據,全部在_unkown_table_計數中。
DBus同樣可以接入Flume、Filebeat、UMS等數據源,只需要稍作配置,就可以實現類似于對Logstash數據源同樣的處理效果,更多關于DBus對log的處理說明,請參考:
https://bridata.github.io/DBus/install-logstash-source.html
https://bridata.github.io/DBus/install-flume-source.html
應用日志經過DBus處理后,將原始數據日志轉換為了結構化數據,輸出到Kafka中提供給下游數據使用方進行使用,比如通過Wormhole將數據落入數據庫等。具體如何將DBus與Wormhole結合起來使用,請參考:如何設計實時數據平臺(技術篇)。
作者:仲振林
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





