溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何用Python寫一個詞頻統計小項目,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
這里用python做一個小小的英文詞頻的統計。當然了,自己寫的,就沒有停詞、計算詞語權重這些功能了,純粹是寫寫代碼練練手。
首先呢,這里是一篇英文文章,就像下面這樣的185個小段落,數據量還是不大的,哈利波特小說好像有10W行,感興趣可以找到分一下。

雖然我安裝了2、3兩個版本.這里用的是Python2,因為Python2打印好像不用寫括號,比較省事。
廢話不多說,這里主要有兩個腳本,一個是分詞,一個是統計詞頻的:
1
分詞
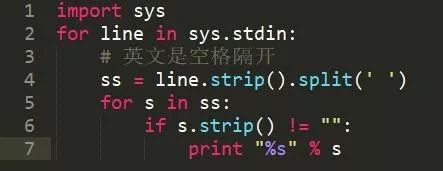
我這里是用的cmd窗口的命令依次讀取一行,形成文件流,每次處理一行,否則就需要弄一個很大的列表(list)。
如上面幾行代碼所示,對英文進行分詞是非常簡單的,只需要根據空格分開就行了。不像中文,還需要詞庫、用一系列算法計算。然后打印到控制臺就行了。這樣打印出來的詞語還是無序的,我們需要將其排序,就是讓相鄰詞語一小段一小段一樣的,需要用sort排序,就像這樣:
cmd窗口輸入命令執行腳本:
type The_Clock_and_the_Key.txt | python2 splitText.py | sort
這里的“type”是打開一個文本文件,“|”是管道:把左邊內容作為參數給右邊的函數。
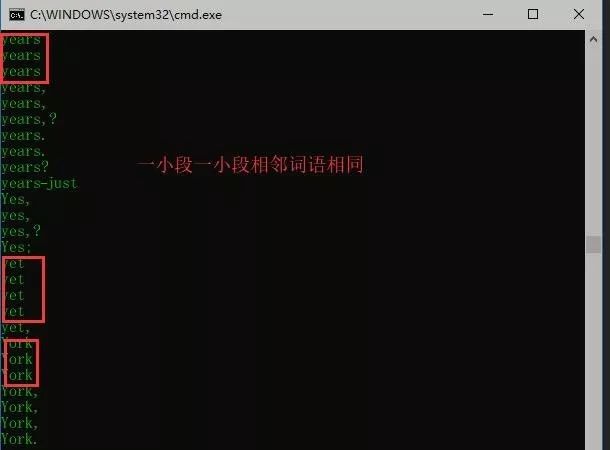
這樣每個詞語就占一行,其實這個就是hadoop的一個基本功能之一:【排序】。
2
統計詞頻
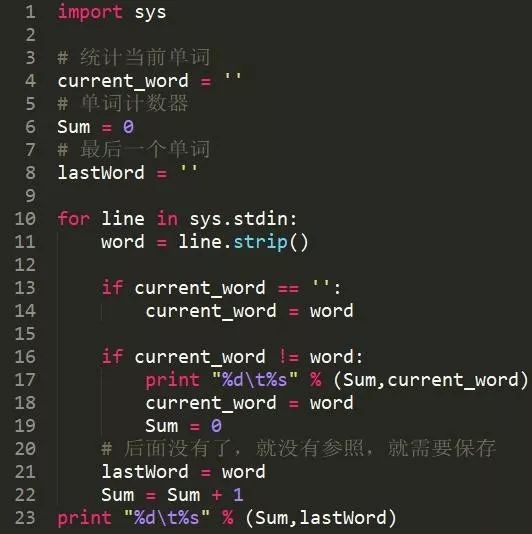
思想是,如果當前讀進來的單詞與保存的單詞不一樣,表明該詞語統計結束。由于,最后一個詞語賦值給current_word后,沒有對比的了(已經到最后一行了,這里打印的時候,需要在循環外面打印一次,第23行代碼)。
將第一個腳本處理后的一個單詞占一行,并且相鄰段單詞一樣的數據流用管道傳入這個腳本進行處理。
cmd窗口輸入命令執行腳本:
type The_Clock_and_the_Key.txt | python2 splitText.py | sort | python2 splitText2.py | sort /R
這里的sort /R表示倒序(reverse),是一個函數。
windows命令行不太會玩,最終排序是這樣的排序:
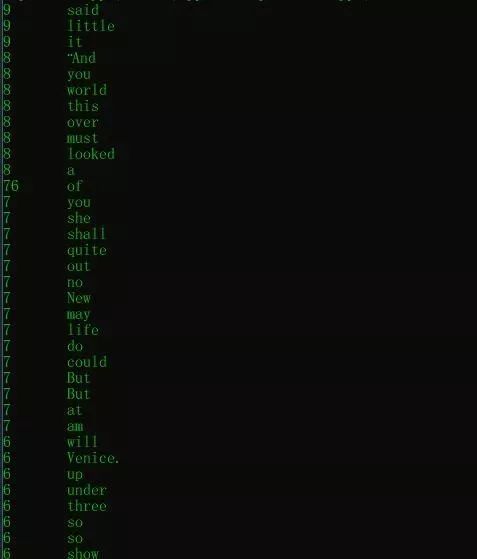
好像是按照字典排序的,哈哈,就這樣吧!有強迫癥的同學可以用列表或者字典,調用Python自帶sort函數排一下序。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





