溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Java中JVM內存布局的GC原理是怎樣的,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。

剛開始時,對象分配在 eden 區,s0(即:from)及 s1(即:to)區,幾乎是空著。

隨著應用的運行,越來越多的對象被分配到 eden 區。
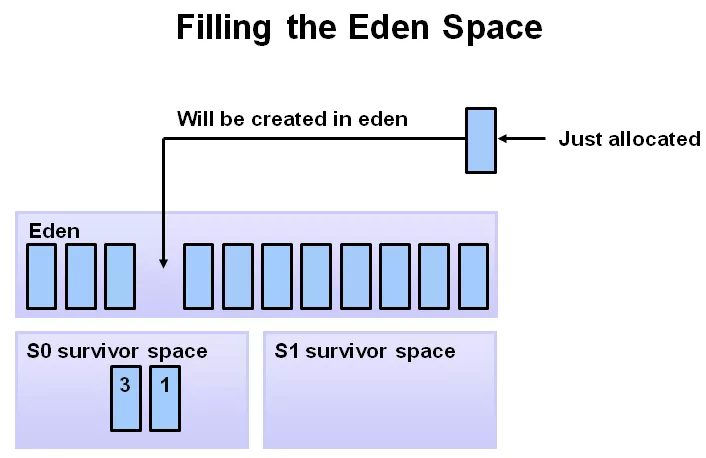
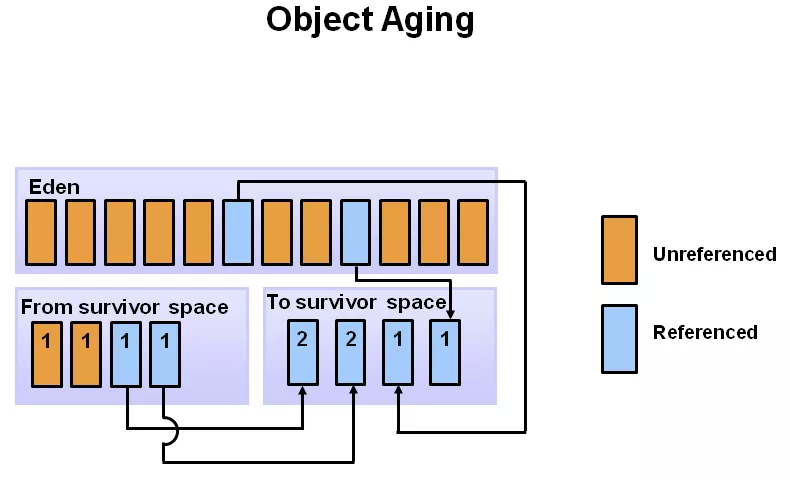
當 Eden 區放不下時,就會發生 minor GC(也被稱為 young GC),第1步當然是要先標識出不可達垃圾對象(即:下圖中的黃色塊),然后將可達對象,移動到 s0 區(即:4 個淡藍色的方塊挪到 s0 區),然后將黃色的垃圾塊清理掉,這一輪過后,eden 區就成空的了。
注:這里其實已經綜合運用了“【標記-清理 eden】 + 【標記-復制 eden->s0】”算法。

繼續,隨著對象的不斷分配,eden 空可能又滿了,這時會重復剛才的 minor GC 過程,不過要注意的是,這時候 s0 是空的,所以 s0 與 s1 的角色其實會互換,即:存活的對象,會從 eden 和 s1 區,向 s0 區移動。然后再把 eden 和 s1 區中的垃圾清除,這一輪完成后,eden 與 s1 區變成空的,如下圖。 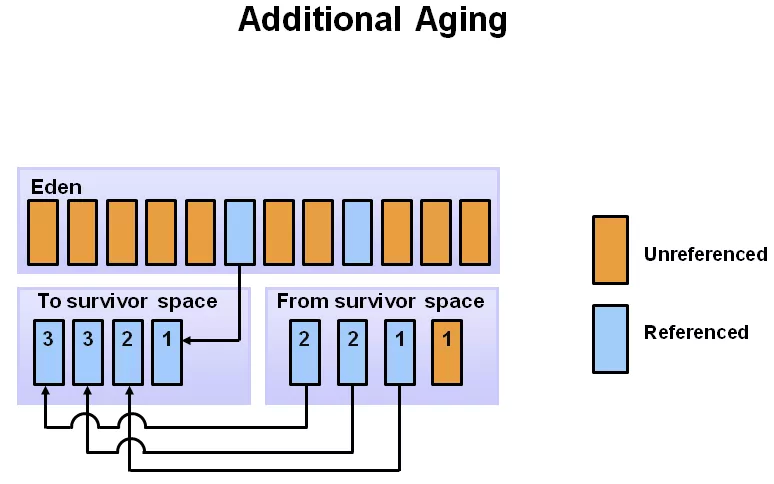
**對于那些比較“長壽”的對象一直在 s0 與 s1 中挪來挪去,一來很占地方,而且也會造成一定開銷,降低 gc 效率,于是有了“代齡(age)”及“晉升”。 ** 對象在新生代的 3 個區(edge,s0,s1)之間,每次從 1 個區移到另 1 區,年齡+1,在 young 區達到一定的年齡閾值后,將晉升到老年代。下圖中是 8,即:挪動 8 次后,如果還活著,下次 minor GC 時,將移動到 Tenured 區。
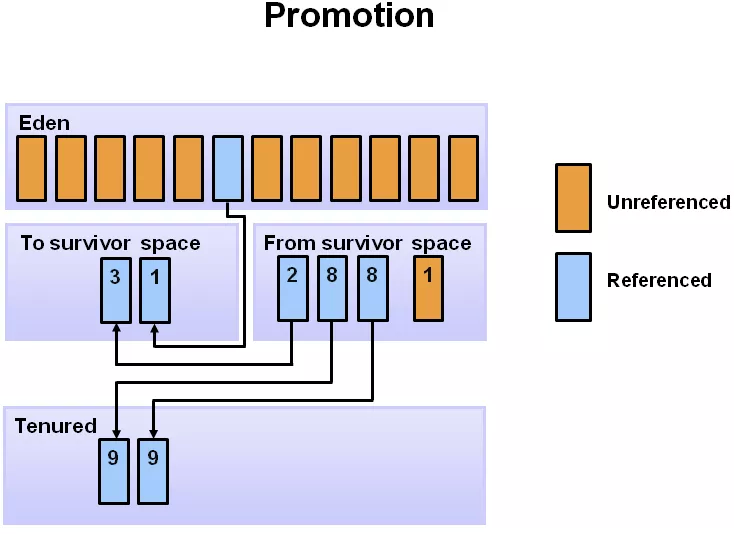
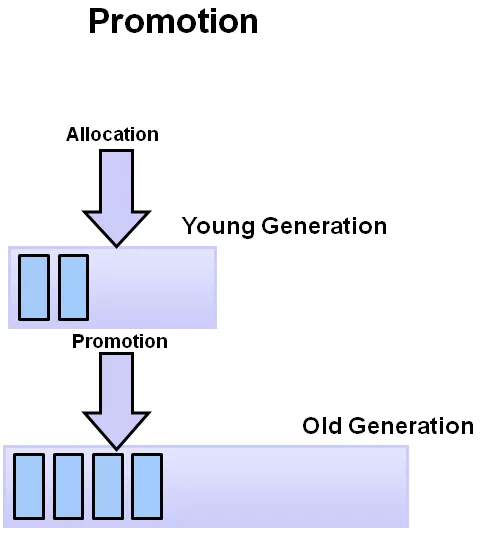
下圖是晉升的主要過程:對象先分配在新生代,經過多次 Young GC 后,如果對象還活著,晉升到老年代。
如果老年代,最終也放滿了,就會發生 major GC(即 Full GC),由于老年代的的對象通常會比較多,因為標記-清理-整理(壓縮)的耗時通常會比較長,會讓應用出現卡頓的現象,這也是為什么很多應用要優化,盡量避免或減少 Full GC (STW)的原因。
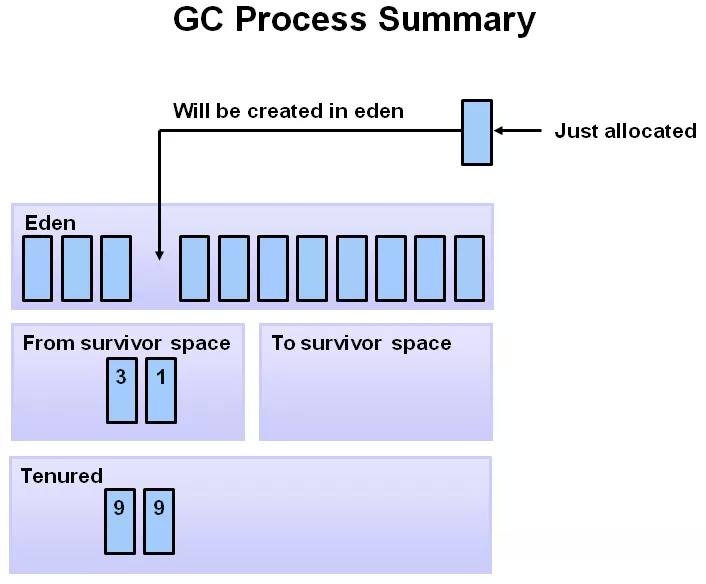
如果分配的新對象比較大,YGC之后,Eden 區放不下,但是 old 區可以放下時,會直接分配到 old 區(即沒有晉升這一過程,直接到老年代了)。
如果分配的新對象比較大,Eden 區放不下,YGC之后發現S(TO)區域放不下,但是 old 區可以放下時,直接會晉升到old區。
如果分配的新對象比較大,Eden 區放不下,YGC之后發現S(TO)區域放得下,但是超過了 pre tenured threshold值 ,直接會晉升到old區。
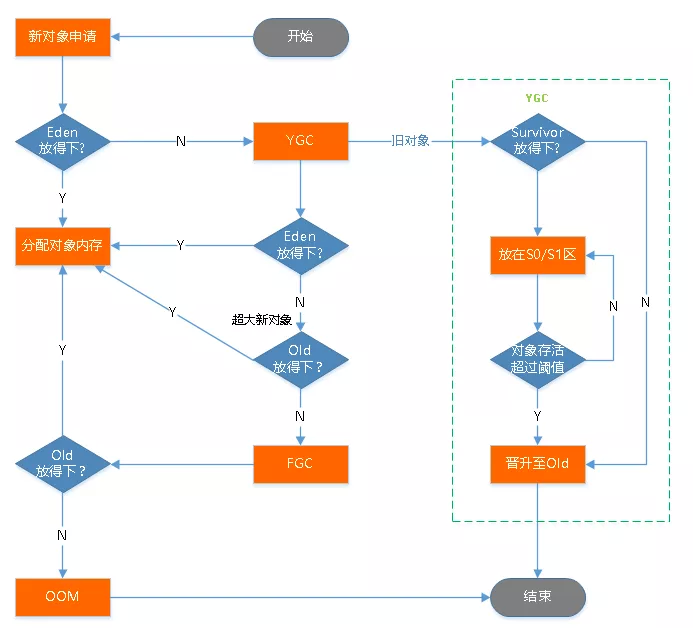
不算最新出現的神器 ZGC,歷史上出現過 7 種經典的垃圾回收器。
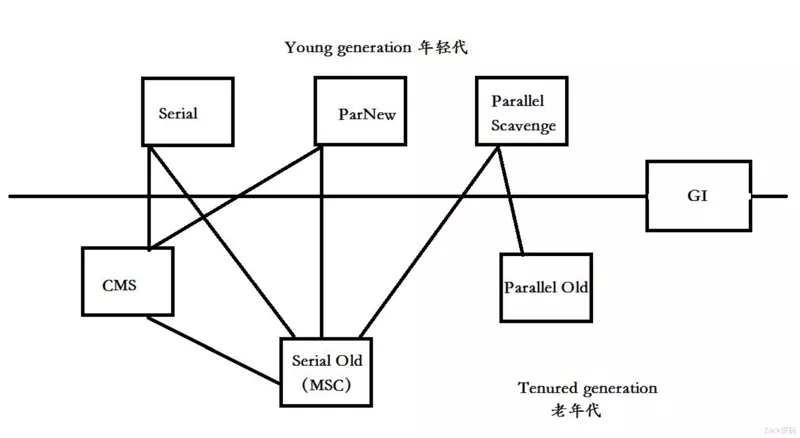
這些回收器都是基于分代的,把 G1 除外,按回收的分代劃分,橫線以上的 3 種:Serial ,ParNew, Parellel Scavenge 都是回收新生代的,橫線以下的 3 種:CMS,Serial Old, Parallel Old 都是回收老年代的。
單線程用標記-復制算法,快刀斬亂麻,單線程的好處避免上下文切換,早期的機器,大多是單核,也比較實用。但執行期間,會發生 STW(Stop The World)。
Serial 的多線程版本,同樣會 STW,在多核機器上會更適用。
ParNew 的升級版本(注重吞吐量),主要區別在于提供了兩個參數: -XX:MaxGCPauseMillis 最大垃圾回收停頓時間(通過犧牲Eden區回收范圍來控制時間); -XX:GCTimeRatio 垃圾回收時間與總時間占比(主要是通過預先計算回收時間的平均值進行預測相關執行時間),通過這2個參數,可以適當控制回收的節奏,更關注于吞吐率,即總時間與垃圾回收時間的比例。充分利用CPU的執行時間,提高吞吐效率。但是回收時間不應當最快和最短
因為老年代的對象通常比較多,占用的空間通常也會更大,如果采用復制算法,得留 50%的空間用于復制,相當不劃算,而且因為對象多,從 1 個區,復制到另 1 個區,耗時也會比較長,所以老年代的收集,通常會采用“標記-整理”法。從名字就可以看出來,這是單線程(串行)的, 依然會有 STW。
一句話:Serial Old 的多線程版本。
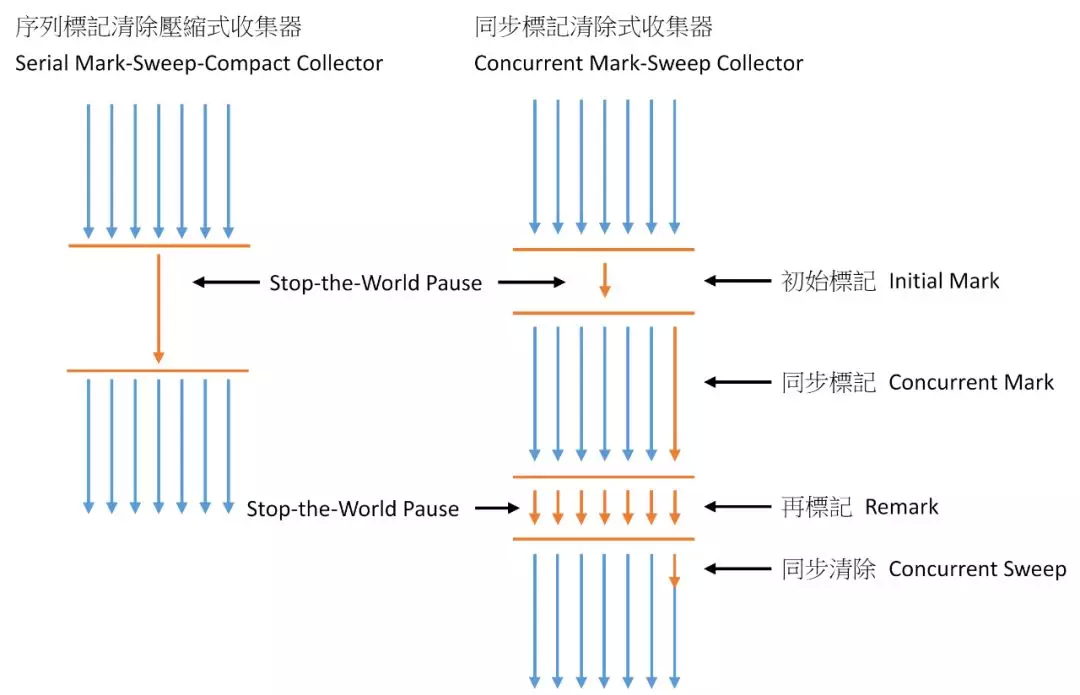
全稱:Concurrent Mark Sweep,從名字上看,就能猜出它是并發多線程的。這是 JDK 7 中廣泛使用的收集器,有必要多說一下,借一張網友的圖說話:
相對 Serial Old 收集器或 Parallel Old 收集器而言,這個明顯要復雜多了,分為 4 個階段:
1)Inital Mark 初始標記:主要是標記 GC Root 開始的下級(注:僅下一級)對象,這個過程會 STW,但是跟 GC Root 直接關聯的下級對象不會很多,因此這個過程其實很快。
2)Concurrent Mark 并發標記:根據上一步的結果,繼續向下標識所有關聯的對象,直到這條鏈上的最盡頭。這個過程是多線程的,雖然耗時理論上會比較長,但是其它工作線程并不會阻塞,沒有 STW。
3)Remark 再標志:為啥還要再標記一次?因為第 2 步并沒有阻塞其它工作線程,其它線程在標識過程中,很有可能會產生新的垃圾。
4)Concurrent Sweep:并行清理,這里使用多線程以“Mark Sweep-標記清理”算法,把垃圾清掉,其它工作線程仍然能繼續支行,不會造成卡頓。
試想下,高鐵上的垃圾清理員,從車廂一頭開始吆喝“有需要扔垃圾的乘客,請把垃圾扔一下”,一邊工作一邊向前走,等走到車廂另一頭時,剛才走過的位置上,可能又有乘客產生了新的空瓶垃圾。所以,要完全把這個車廂清理干凈的話,她應該喊一下:所有乘客不要再扔垃圾了(STW),然后把新產生的垃圾收走。
當然,因為剛才已經把收過一遍垃圾,所以這次收集新產生的垃圾,用不了多長時間(即:STW 時間不會很長)。
等等,剛才我們不是提到過“標記清理”法,會留下很多內存碎片嗎?確實,但是也沒辦法,如果換成“Mark Compact 標記-整理”法,把垃圾清理后,剩下的對象也順便排整理,會導致這些對象的內存地址發生變化,別忘了,此時其它線程還在工作,如果引用的對象地址變了,就天下大亂了。
雖然仍不完美,但是從這 4 步的處理過程來看,以往收集器中最讓人詬病的長時間 STW,通過上述設計,被分解成二次短暫的 STW,所以從總體效果上看,應用在 GC 期間卡頓的情況會大大改善,這也是 CMS 一度十分流行的重要原因。
由于CMS并發清理階段用戶線程還在運行著,伴隨程序運行自然會有新垃圾產生,這部分垃圾得標記過程之后,所以CMS無法在當收集中處理掉他們,只好留待下一次GC清理掉,這一部分垃圾稱為浮動垃圾。
在jdk1.5默認設置下,CMS收集器當老年代使用了68%的空間就會被激活,可以通過-XX:CMSInitialOccupancyFraction的值來提高觸發百分比,在jdk1.6中CMS啟動閾值提升到了92%,要是CMS運行期間預留的內存無法滿足程序的需要,就會出現”Concurrent Mode Failure“,然后降級臨時啟用Serial Old收集器進行老年代的垃圾收集,這樣停頓時間就很長了。(當存在并發清除的時候,業務線程還可以產生來及,結果造成CMS回收的時候,無法區存儲過大新生對象內存快,導致出現CMF)
所以-XX:CMSInitialOccupancyFraction設置太高容易導致大量”Concurrent Mode Failure“。
CMS是一款基于“標記-清除”算法實現的,所以會產生空間碎片。為了解決這個問題,CMS提供了-XX:UseCMSCompactAtFullCollection開發參數用于開啟內存碎片的合并整理,由于內存整理是無法并行的,所以停頓時間會變長。還有-XX:CMSFullGCBeforeCompaction,這個參數用于設置多少次不壓縮Full GC后,跟著來一次帶壓縮的(默認為0)。
CMS默認啟動的回收線程數是(cpu數量+3)/4。所以CPU數量少會導致用戶程序執行速度降低較多。這就是它會降低吞吐量的原因之一。
G1 的全稱是 Garbage-First。鑒于 CMS 的一些不足之外,比如: 老年代內存碎片化,STW 時間雖然已經改善了很多,但是仍然有提升空間。G1 就橫空出世了,它對于 heap 區的內存劃思路很新穎,有點算法中分治法“分而治之”的味道。
如下圖,G1 將 heap 內存區,劃分為一個個大小相等(1-32M,2 的 n 次方)、內存連續的 Region 區域,每個 region 都對應 Eden、Survivor 、Old、Humongous 四種角色之一,但是 region 與 region 之間不要求連續。
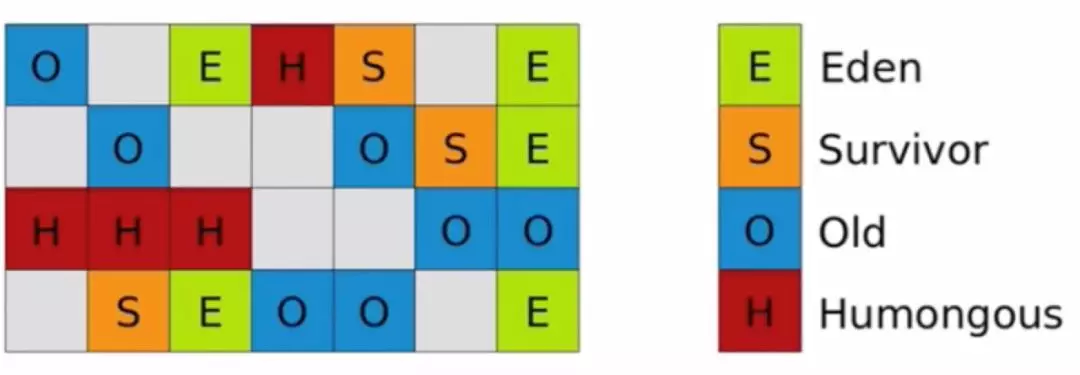
注:Humongous,簡稱 H 區是專用于存放超大對象的區域,通常>= 1/2 Region Size,且只有 Full GC 階段,才會回收 H 區,避免了頻繁掃描、復制/移動大對象。
所有的垃圾回收,都是基于 1 個個 region 的。JVM 內部知道,哪些 region 的對象最少(即:該區域最空),總是會優先收集這些 region(因為對象少,內存相對較空,肯定快),這也是 Garbage-First 得名的由來,G 即是 Garbage 的縮寫, 1 即 First。
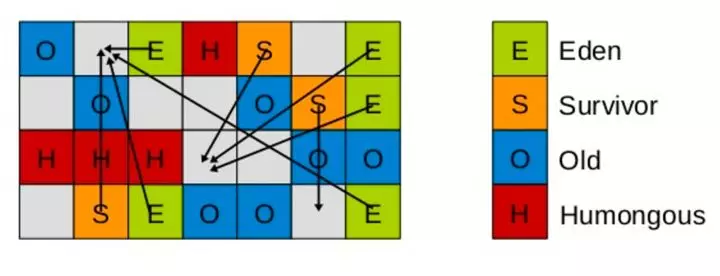

理論上講,只要有一個 Empty Region(空區域),就可以進行垃圾回收。

由于region 與 region 之間并不要求連續,而使用 G1 的場景通常是大內存,比如 64G 甚至更大,為了提高掃描根對象和標記的效率,G1 使用了二個新的輔助存儲結構:
Remembered Sets:簡稱 RSets,用于根據每個 region 里的對象,是從哪指向過來的(即:誰引用了我),每個 Region 都有獨立的 RSets。(Other Region -> Self Region)。
Collection Sets :簡稱 CSets,記錄了等待回收的 Region 集合,GC 時這些 Region 中的對象會被回收(copied or moved)。 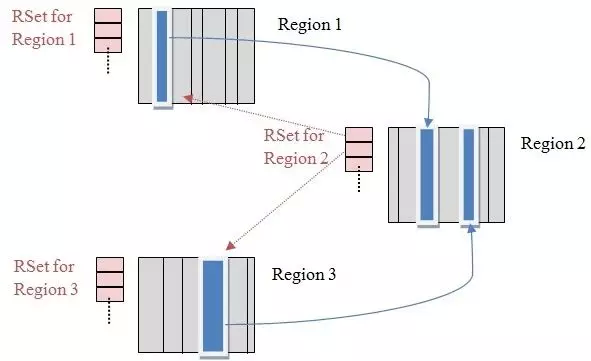
RSets的引入,在YGC時,將新生代 Region 的 RSets 做為根對象,可以避免掃描老年代的 region,能大大減輕 GC 的負擔。注:在老年代收集 Mixed GC 時,RSets 記錄了 Old->Old 的引用,也可以避免掃描所有 Old 區。
也稱為 Old Generation Collection
按 oracle 官網文檔描述分為 5 個階段:Initial Mark(STW) -> Root Region Scan -> Cocurrent Marking -> Remark(STW) -> Copying/Cleanup(STW && Concurrent)

注:也有很多文章會把 Root Region Scan 省略掉,合并到 Initial Mark 里,變成 4 個階段。
存活對象的“初始標記”依賴于 Young GC,GC 日志中會記錄成 young 字樣。
2019-06-09T15:24:37.086+0800: 500993.392: [GC pause (G1 Evacuation Pause) (young), 0.0493588 secs] [Parallel Time: 41.9 ms, GC Workers: 8] [GC Worker Start (ms): Min: 500993393.7, Avg: 500993393.7, Max: 500993393.7, Diff: 0.1] [Ext Root Scanning (ms): Min: 1.5, Avg: 2.2, Max: 4.4, Diff: 2.8, Sum: 17.2] [Update RS (ms): Min: 15.8, Avg: 18.1, Max: 18.9, Diff: 3.1, Sum: 144.8] [Processed Buffers: Min: 110, Avg: 144.9, Max: 163, Diff: 53, Sum: 1159] [Scan RS (ms): Min: 4.7, Avg: 5.0, Max: 5.1, Diff: 0.4, Sum: 39.7] [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Object Copy (ms): Min: 16.4, Avg: 16.5, Max: 16.6, Diff: 0.2, Sum: 132.0] [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Termination Attempts: Min: 1, Avg: 4.9, Max: 7, Diff: 6, Sum: 39] [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.3] [GC Worker Total (ms): Min: 41.7, Avg: 41.8, Max: 41.8, Diff: 0.1, Sum: 334.1] [GC Worker End (ms): Min: 500993435.5, Avg: 500993435.5, Max: 500993435.5, Diff: 0.0] [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.2 ms] [Other: 7.2 ms] [Choose CSet: 0.0 ms] [Ref Proc: 4.3 ms] [Ref Enq: 0.1 ms] [Redirty Cards: 0.1 ms] [Humongous Register: 0.1 ms] [Humongous Reclaim: 0.1 ms] [Free CSet: 0.6 ms] [Eden: 1340.0M(1340.0M)->0.0B(548.0M) Survivors: 40.0M->64.0M Heap: 2868.2M(12.0G)->1499.8M(12.0G)] [Times: user=0.35 sys=0.00, real=0.05 secs]

并發標記過程中,如果發現某些 region 全是空的,會被直接清除。
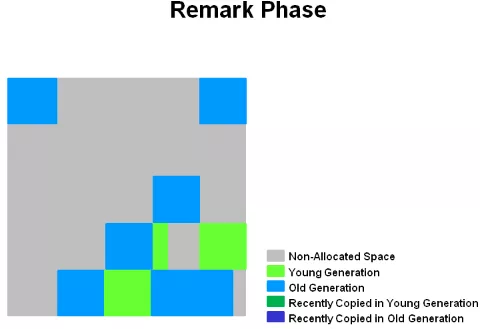
進入重新標記階段。
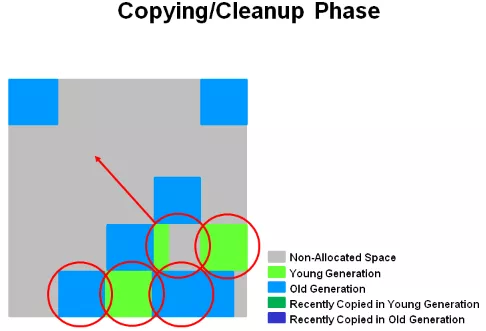
并發復制/清查階段。這個階段,Young 區和 Old 區的對象有可能會被同時清理。GC 日志中,會記錄為 mixed 字段,這也是 G1 的老年代收集,也稱為 Mixed GC 的原因。
2019-06-09T15:24:23.959+0800: 500980.265: [GC pause (G1 Evacuation Pause) (mixed), 0.0885388 secs] [Parallel Time: 74.2 ms, GC Workers: 8] [GC Worker Start (ms): Min: 500980270.6, Avg: 500980270.6, Max: 500980270.6, Diff: 0.1] [Ext Root Scanning (ms): Min: 1.7, Avg: 2.2, Max: 4.1, Diff: 2.4, Sum: 17.3] [Update RS (ms): Min: 11.7, Avg: 13.7, Max: 14.3, Diff: 2.6, Sum: 109.8] [Processed Buffers: Min: 136, Avg: 141.5, Max: 152, Diff: 16, Sum: 1132] [Scan RS (ms): Min: 42.5, Avg: 42.9, Max: 43.1, Diff: 0.5, Sum: 343.1] [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] [Object Copy (ms): Min: 14.9, Avg: 15.2, Max: 15.4, Diff: 0.5, Sum: 121.7] [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] [Termination Attempts: Min: 1, Avg: 8.2, Max: 11, Diff: 10, Sum: 66] [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2] [GC Worker Total (ms): Min: 74.0, Avg: 74.0, Max: 74.1, Diff: 0.1, Sum: 592.3] [GC Worker End (ms): Min: 500980344.6, Avg: 500980344.6, Max: 500980344.6, Diff: 0.0] [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.5 ms] [Other: 13.9 ms] [Choose CSet: 4.1 ms] [Ref Proc: 1.8 ms] [Ref Enq: 0.1 ms] [Redirty Cards: 0.2 ms] [Humongous Register: 0.1 ms] [Humongous Reclaim: 0.1 ms] [Free CSet: 5.6 ms] [Eden: 584.0M(584.0M)->0.0B(576.0M) Survivors: 28.0M->36.0M Heap: 4749.3M(12.0G)->2930.0M(12.0G)] [Times: user=0.61 sys=0.00, real=0.09 secs]

通過這幾個階段的分析,雖然看上去很多階段仍然會發生 STW,但是 G1 提供了一個預測模型,通過統計方法,根據歷史數據來預測本次收集,需要選擇多少個 Region 來回收,盡量滿足用戶的預期停頓值(-XX:MaxGCPauseMillis 參數可指定預期停頓值)。
注:如果 Mixed GC 仍然效果不理想,跟不上新對象分配內存的需求,會使用 Serial Old GC(Full GC)強制收集整個 Heap。
小結:與 CMS 相比,G1 有內存整理過程(標記-壓縮),避免了內存碎片;STW 時間可控(能預測 GC 停頓時間)。
上述內容就是Java中JVM內存布局的GC原理是怎樣的,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。