溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關ES集群故障的問題追蹤與解決方案是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
1、很久前的歷史問題了,來記錄下。問題原因是某2個索引發生了寫故障,開始是懷疑某臺機器硬盤導致的。這種情況的影響是集群狀態變red,部分記錄無法被搜索到。詭異的是其中一個索引出現故障后自動恢復了,而另外一個索引卻無法自動回復。
2、話不多說,日志是反映問題的第一現場。

以上日志可以看出該索引的副本3出現了故障,且是write bulk的寫故障。由于ES的寫操作會先寫主分片,然后主分片再將操作同步到副本分片,再等待副本并發操作完再返回客戶端。故查看ES副本執行操作時的源碼,發現日志返回的報錯信息恰好就在副本操作發生異常時回調的onFailure方法中,里邊再調用了failShardIfNeeded方法,failShardIfNeeded方法又調用了decPendingAndFinishIfNeeded onPrimaryDemoted這兩個方法,通過查找資料對比源碼發現:
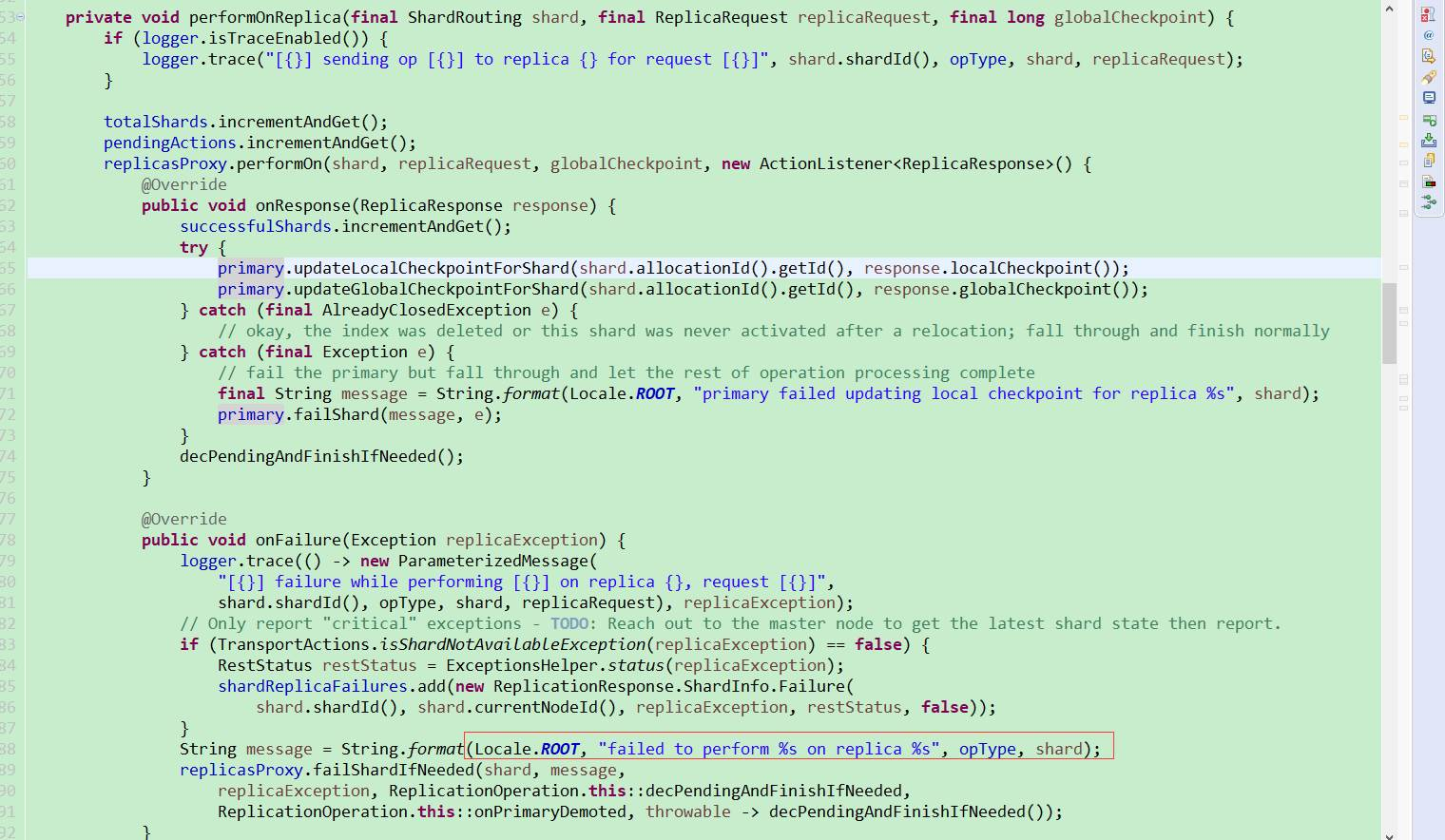
decPendingAndFinishIfNeeded 是當所有的分片都處理完這個請求后,不管是查詢失敗還是成功、超時,每執行一次,都會總查詢的總分片數減1,直到所有分片都返回了,再調用finish()方法響應客戶端:

onPrimaryDemoted是寫操作首先在主分片執行成功,然后同步到副本,但是副本發現它的主分片 的 primary term 比它知道的該索引的primary term 還小,term因為是寫的請求總是分發到主分片,所以每次更新主分片,term都會加1,在主向副發送同步數據的請求時候會帶上這個term值(感覺應該是為了保證數據一致性)。當主帶過來的term值對比之前帶過來的還要小,那證明這個主分片處于一種不正常的狀態。于是副本就認為這個主分片是一個已經過時了的主分片,因此就回調onFailure方法拒絕執行,并執行onPrimaryDemoted通知master節點,master節點會檢測該主分片是否真的異常,真的過時會在索引Meta信息中更新配置,將該副本分片移除(集群中經常體現的就是unsigned了)。

查看異常日志,發現確實出現了方法中打印的異常日志,且對比term值確實發現主分片異常:

3、開篇提到了,因為是同時有2個索引發生了故障,所以懷疑是機器本身的原因。但是按理說,剔除了副本就好了,但是為什么一個索引的主分片故障后自動分配,并從translog恢復數據變為健康狀態了,另一個索引的主分片卻無法自動恢復分配呢?原因是ES移除shard后有一個故障恢復時間,當故障超過一定時間,ES會分配一個新的shard到新node上,此時需要全量同步數據。但是如果之前故障的shard回來了,就可以只回補故障之后的數據,追平后加回來即可,實現快速故障恢復。聯合之前的經驗,確實有這種故障后恢復是需要從重新從主分片拷貝一份,完了后再刪除原來那個副本的情況。且日志里面也有體現timeout了:

4、解決方案綜合以上分析,此時不能直接恢復,執行命令讓ES重試分配,從原來的shard中恢復,如果是手動分配自動復制的話,會有擠爆硬盤的風險:POST /_cluster/reroute?retry_failed=true
5、總結至此看到了這次故障的大概原因,但是為什么會引發這樣的故障還是沒有頭緒,更深層次的原理還是需要努力一層一層往深了挖,閱讀源碼,萬法不離其宗,es也只是一個java應用。
上述就是小編為大家分享的ES集群故障的問題追蹤與解決方案是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





