溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么使用Kaggle實現對抗驗證”,在日常操作中,相信很多人在怎么使用Kaggle實現對抗驗證問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么使用Kaggle實現對抗驗證”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
首先,導入一些庫:

對于本教程,我們將使用Kaggle的IEEE-CIS信用卡欺詐檢測數據集。首先,假設您已將訓練和測試數據加載到pandas DataFrames中,并將它們分別命名為df_train和df_test。然后,我們將通過替換缺失值進行一些基本的清理。

對于對抗性驗證,我們想學習一個模型,該模型可以預測訓練數據集中哪些行以及測試集中哪些行。因此,我們創建一個新的目標列,其中測試樣本用1標記,訓練樣本用0標記,如下所示:

這是我們訓練模型進行預測的目標。目前,訓練數據集和測試數據集是分開的,每個數據集只有一個目標值標簽。如果我們在此訓練集上訓練了一個模型,那么它只會知道一切都為0。我們想改組訓練和測試數據集,然后創建新的數據集以擬合和評估對抗性驗證模型。我定義了一個用于合并,改組和重新拆分的函數:

新的數據集adversarial_train和adversarial_test包括原始訓練集和測試集的混合,而目標則指示原始數據集。注意:我已將TransactionDT添加到特征列表中。
對于建模,我將使用Catboost。我通過將DataFrames放入Catboost Pool對象中來完成數據準備。

這部分很簡單:我們只需實例化Catboost分類器并將其擬合到我們的數據中:

讓我們繼續前進,在保留數據集上繪制ROC曲線:

這是一個完美的模型,這意味著有一種明確的方法可以告訴您任何給定的記錄是否在訓練或測試集中。這違反了我們的訓練和測試集分布相同的假設。
為了了解模型如何做到這一點,讓我們看一下最重要的特征:
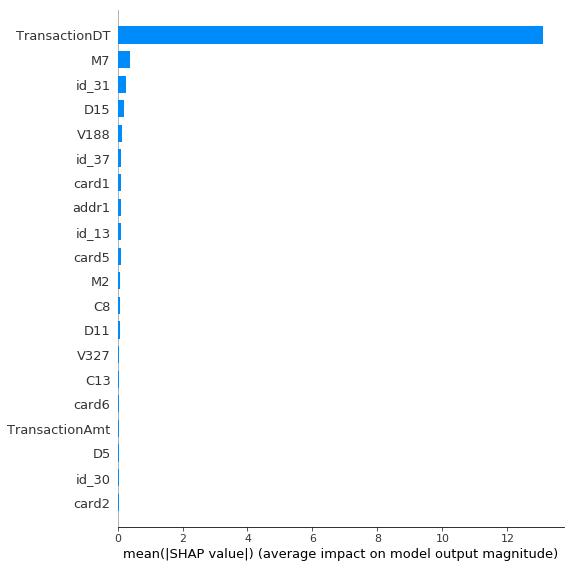
到目前為止,TransactionDT是最重要的特征。鑒于原始的訓練和測試數據集來自不同的時期(測試集出現在訓練集的未來),這完全合情合理。該模型剛剛了解到,如果TransactionDT大于最后一個訓練樣本,則它在測試集中。
我之所以包含TransactionDT只是為了說明這一點–通常不建議將原始日期作為模型特征。但是好消息是這項技術以如此戲劇性的方式被發現。這種分析顯然可以幫助您識別這種錯誤。
讓我們消除TransactionDT,然后再次運行此分析。

現在,ROC曲線如下所示:
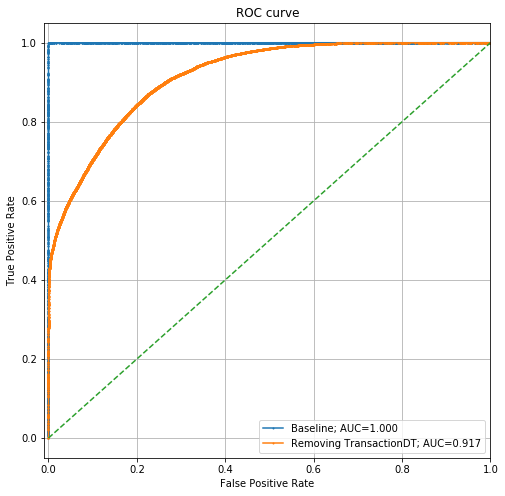
它仍然是一個相當強大的模型,AUC> 0.91,但是比以前弱得多。讓我們看一下此模型的特征重要性:
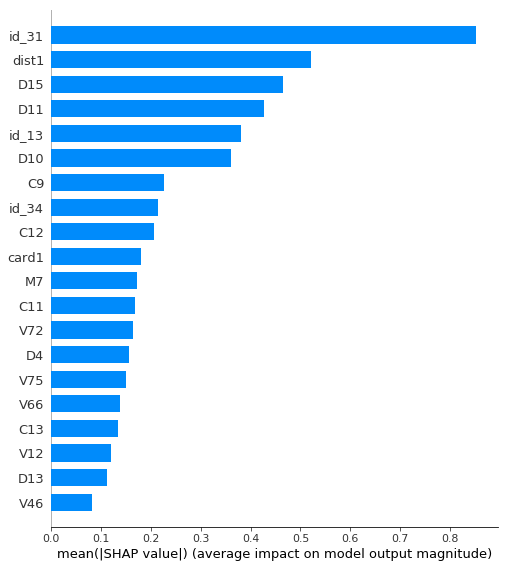
現在,id_31是最重要的功能。讓我們看一些值以了解它是什么。

此列包含軟件版本號。顯然,這在概念上與包含原始日期類似,因為特定軟件版本的首次出現將與其發布日期相對應。
讓我們通過刪除列中所有不是字母的字符來解決此問題:

現在,我們的列的值如下所示:

讓我們使用此清除列來訓練新的對抗驗證模型:
現在,ROC圖如下所示:
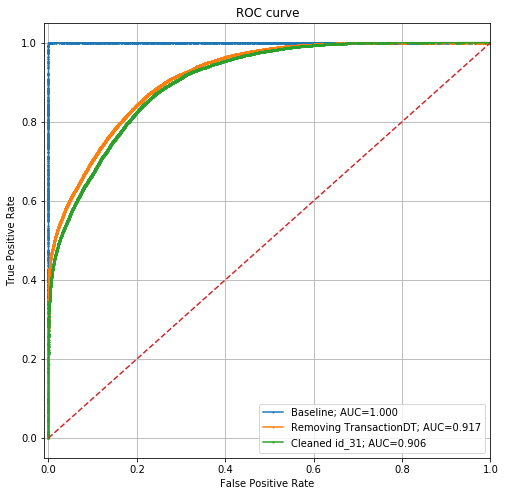
性能已從0.917的AUC下降到0.906。這意味著我們已經很難讓模型區分我們的訓練數據集和測試數據集,但是它仍然很強大。
到此,關于“怎么使用Kaggle實現對抗驗證”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





