溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在關系數據庫中,表中數據普遍以無序的狀態存儲在磁盤上,在沒有相應索引時,若要對表中數據進行查詢,就只能全表檢索,將所有記錄挨個讀取,然后和查詢條件進行比較,顯然,這種方式會導致大量的磁盤 I/O 操作和 CPU 計算,消耗大量的系統時間,因此,建立索引就成了一個必須考慮的選項。
使用 CREATE INDEX [索引名] on 表名 (列名,……) 語句可以為表中數據建立最常用的鍵值索引,而鍵值索引的實現大都采用 B+ 樹數據結構,它有以下一些性質:
1、 是一棵平衡樹,即從根節點到葉子節點的深度相差不超過 1;
2、 非葉子節點只保存鍵值和指向子節點的指針,不保存數據;
3、 葉子節點保存鍵值、對應記錄的地址及葉子節點的鏈表指針,鏈表中葉子節點是鍵值有序的
但這些性質就一定能保證查詢性能滿足用戶的需求嗎?下面,我們以對銀行賬戶進行時間段查詢為例,探討索引的性能問題。
為了方便說明問題,我們在這里把 B+ 樹簡化為 下圖所示的B+ 樹,以賬號和交易日期作為鍵值,如下圖所示:
?
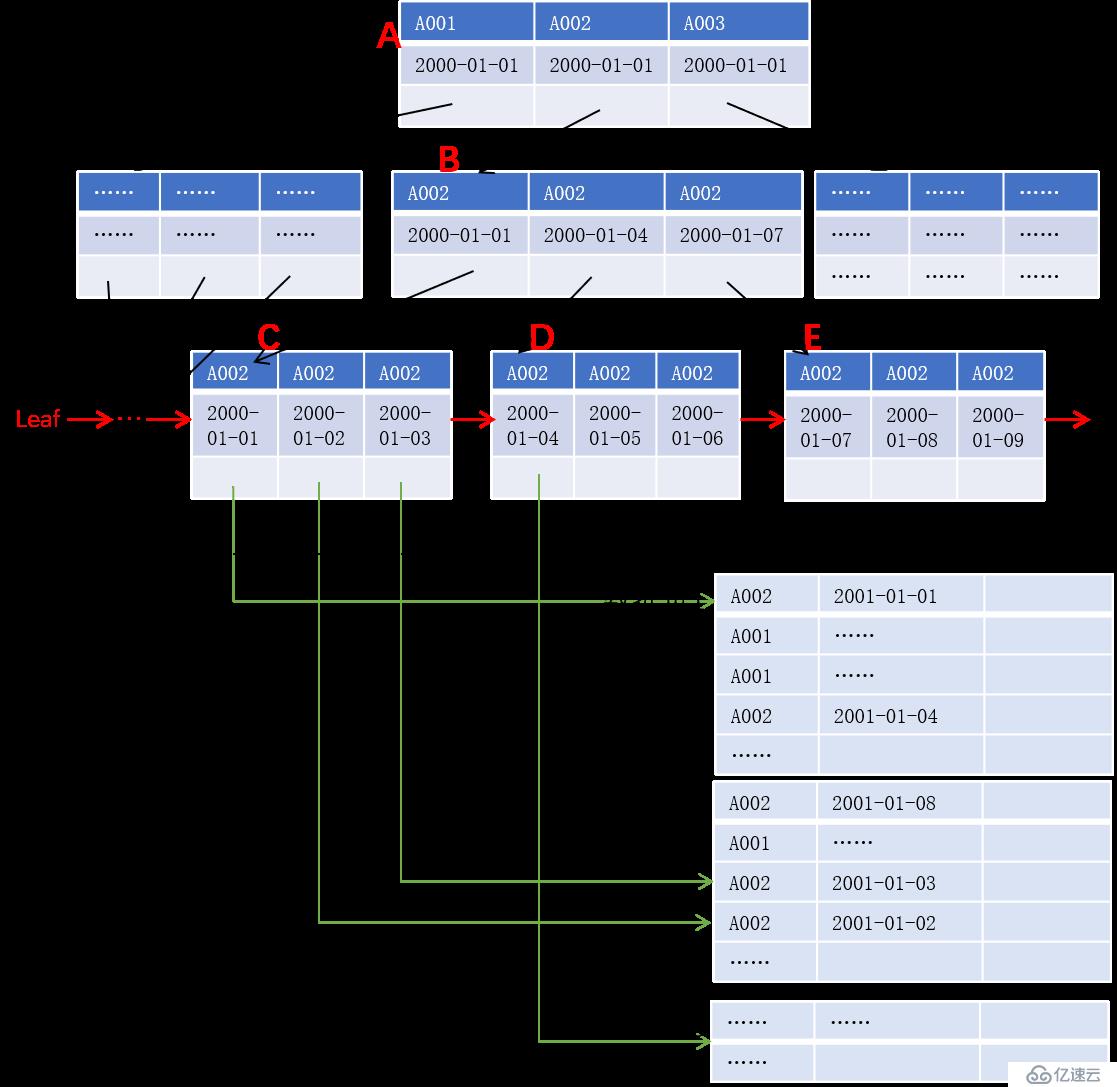
如果我們要查詢賬號 A002 從 2000-01-01 到 2000-01-07 的交易流水,數據庫系統會首先要查找賬號為 A002、日期不早于 2000-01-01 的鍵值所在的葉子節點,結果是依次讀取索引塊 A、B、C,然后找出索引塊 C 中滿足條件的鍵值對應的記錄地址并讀出記錄返回,若索引塊 C 中最后一個日期早于或等于 2001-01-07,則可以根據葉子節點的鏈表直接讀取索引列 D,以此類推,直到某個索引塊的某個日期比 2001-01-07 大為止。
觀察上述過程,我們發現 2000-01-01 對應的記錄在數據頁 1,2000-01-02 和 2000-01-03 對應的記錄在數據頁 2,2000-01-04 對應的記錄則在數據頁 3,4 條記錄需要讀取 3 個數據頁,極端情況下甚至任意一條記錄都在不同的數據頁,而此時如果數據區中記錄已按鍵值序存儲則可以顯著減少磁盤 IO。更進一步,如果記錄數據直接保存在葉子節點,則可以減少查詢過程中索引頁與數據頁之間的跳讀,這對于機械硬盤的性能影響尤甚。
這些問題對于集算器的組表來說,可以非常輕松地得到解決。
我們還是以股票交易數據為例講解組表的使用。
| A | |
| 1 | =file("d:/test/stktrade.ctx") |
| 2 | =A1.create@r(#sid,#tdate,open,close,volume) |
| 3 | =connect("mysql") |
| 4 | =A3.cursor("select ? * from stktrade order by sid,tdate") |
| 5 | =A2.append(A4) |
| 6 | =A3.close() |
| 7 | =A2.index(idx1;sid,tdate) |
A2: 創建數據結構為 (sid,tdate,open,close,volume) 的組表,且指定 sid 和 tdate 為鍵,@r 指定數據按行存儲
A5: 將按 sid 和 tdate 有序的數據追加到組表中
A6: 以 sid 和 tdate 為鍵值建立索引 idx1
| A | |
| 1 | =file("d:/test/stktrade.ctx").create() |
| 2 | =A1.icursor(sid=="600036" ? && tdate>=date("2018-01-01") && ? tdate<=date("2018-01-10"),idx1) |
| 3 | =A2.fetch() |
A1: 讀取組表
A2: 定義根據索引 idx1 查詢數據的游標
A3: 取出游標中的數據
?? 在建立索引 idx1 時,也可以將所需的數據都儲存在索引里,譬如要將 open、close、volume 這 3 列也儲存在索引 idx1 里,只需將前面表格里的A2.index(idx1;sid,tdate)改為A1.index(idx1; sid,tdate; open,close,volume)即可,這樣查詢時就可以不讀數據文件、只讀取索引文件,使查詢速度更快。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





