溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark SQL 是 Spark 中的一個子模塊,主要用于操作結構化數據。它具有以下特點:

為了支持結構化數據的處理,Spark SQL 提供了新的數據結構 DataFrame。DataFrame 是一個由具名列組成的數據集。它在概念上等同于關系數據庫中的表或 R/Python 語言中的 data frame。 由于 Spark SQL 支持多種語言的開發,所以每種語言都定義了 DataFrame 的抽象,主要如下:
| 語言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的別名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
DataFrame 和 RDDs 最主要的區別在于一個面向的是結構化數據,一個面向的是非結構化數據,它們內部的數據結構如下:

DataFrame 內部的有明確 Scheme 結構,即列名、列字段類型都是已知的,這帶來的好處是可以減少數據讀取以及更好地優化執行計劃,從而保證查詢效率。
DataFrame 和 RDDs 應該如何選擇?
Dataset 也是分布式的數據集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的優點,具備強類型的特點,同時支持 Lambda 函數,但只能在 Scala 和 Java 語言中使用。在 Spark 2.0 后,為了方便開發者,Spark 將 DataFrame 和 Dataset 的 API 融合到一起,提供了結構化的 API(Structured API),即用戶可以通過一套標準的 API 就能完成對兩者的操作。
這里注意一下:DataFrame 被標記為 Untyped API,而 DataSet 被標記為 Typed API,后文會對兩者做出解釋。

靜態類型 (Static-typing) 與運行時類型安全 (runtime type-safety) 主要表現如下:
在實際使用中,如果你用的是 Spark SQL 的查詢語句,則直到運行時你才會發現有語法錯誤,而如果你用的是 DataFrame 和 Dataset,則在編譯時就可以發現錯誤 (這節省了開發時間和整體代價)。DataFrame 和 Dataset 主要區別在于:
在 DataFrame 中,當你調用了 API 之外的函數,編譯器就會報錯,但如果你使用了一個不存在的字段名字,編譯器依然無法發現。而 Dataset 的 API 都是用 Lambda 函數和 JVM 類型對象表示的,所有不匹配的類型參數在編譯時就會被發現。
以上這些最終都被解釋成關于類型安全圖譜,對應開發中的語法和分析錯誤。在圖譜中,Dataset 最嚴格,但對于開發者來說效率最高。
<div align="center"> <img width="600px" src="https://raw.githubusercontent.com/heibaiying/BigData-Notes/master/pictures/spark-運行安全.png"/> </div>
上面的描述可能并沒有那么直觀,下面的給出一個 IDEA 中代碼編譯的示例:

這里一個可能的疑惑是 DataFrame 明明是有確定的 Scheme 結構 (即列名、列字段類型都是已知的),但是為什么還是無法對列名進行推斷和錯誤判斷,這是因為 DataFrame 是 Untyped 的。
在上面我們介紹過 DataFrame API 被標記為 Untyped API,而 DataSet API 被標記為 Typed API。DataFrame 的 Untyped 是相對于語言或 API 層面而言,它確實有明確的 Scheme 結構,即列名,列類型都是確定的,但這些信息完全由 Spark 來維護,Spark 只會在運行時檢查這些類型和指定類型是否一致。這也就是為什么在 Spark 2.0 之后,官方推薦把 DataFrame 看做是 DatSet[Row],Row 是 Spark 中定義的一個 trait,其子類中封裝了列字段的信息。
相對而言,DataSet 是 Typed 的,即強類型。如下面代碼,DataSet 的類型由 Case Class(Scala) 或者 Java Bean(Java) 來明確指定的,在這里即每一行數據代表一個 Person,這些信息由 JVM 來保證正確性,所以字段名錯誤和類型錯誤在編譯的時候就會被 IDE 所發現。
case class Person(name: String, age: Long)
val dataSet: Dataset[Person] = spark.read.json("people.json").as[Person]這里對三者做一下簡單的總結:
<div align="center"> <img width="600px" src="https://raw.githubusercontent.com/heibaiying/BigData-Notes/master/pictures/spark-structure-api.png"/> </div>
DataFrame、DataSet 和 Spark SQL 的實際執行流程都是相同的:
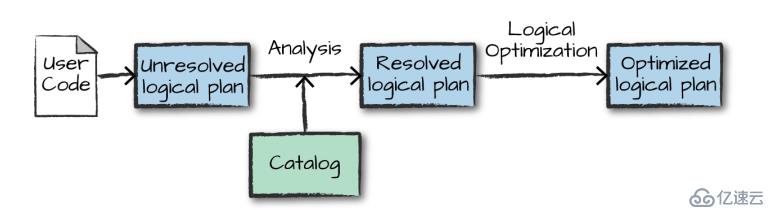
執行的第一個階段是將用戶代碼轉換成一個邏輯計劃。它首先將用戶代碼轉換成 unresolved logical plan(未解決的邏輯計劃),之所以這個計劃是未解決的,是因為盡管您的代碼在語法上是正確的,但是它引用的表或列可能不存在。 Spark 使用 analyzer(分析器) 基于 catalog(存儲的所有表和 DataFrames 的信息) 進行解析。解析失敗則拒絕執行,解析成功則將結果傳給 Catalyst 優化器 (Catalyst Optimizer),優化器是一組規則的集合,用于優化邏輯計劃,通過謂詞下推等方式進行優化,最終輸出優化后的邏輯執行計劃。
得到優化后的邏輯計劃后,Spark 就開始了物理計劃過程。 它通過生成不同的物理執行策略,并通過成本模型來比較它們,從而選擇一個最優的物理計劃在集群上面執行的。物理規劃的輸出結果是一系列的 RDDs 和轉換關系 (transformations)。
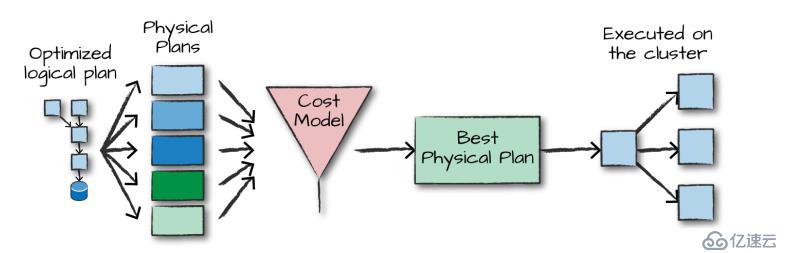
在選擇一個物理計劃后,Spark 運行其 RDDs 代碼,并在運行時執行進一步的優化,生成本地 Java 字節碼,最后將運行結果返回給用戶。
更多大數據系列文章可以參見 GitHub 開源項目: 大數據入門指南
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





