溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關python中怎么模擬感知機算法,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
通過梯度下降模擬感知機算法。數據來源于sklearn.datasets中經典數據集。
import numpy as np
import pandas as pd
# 導入數據集load_iris。
# 其中前四列為花萼長度,花萼寬度,花瓣長度,花瓣寬度等4個用于識別鳶尾花的屬性,
from sklearn.datasets import load_iris
import matplotlib.pyplot as plot
# load data
iris = load_iris()
# 構造函數DataFrame(data,index,columns),data為數據,index為行索引,columns為列索引
# 構造數據結構
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 在df中加入了新的一列:列名label的數據是target,即類型
# 第5列為鳶尾花的類別(包括Setosa,Versicolour,Virginica三類)。
# 也即通過判定花萼長度,花萼寬度,花瓣長度,花瓣寬度的尺寸大小來識別鳶尾花的類別。
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# 打印出label列值對應的數量。以及列名稱、類型
# print(df.label.value_counts())
# 創建數組,
# 第一個參數:100表示取0-99行,即前100行;但100:表示100以后的所有數據。
# 第二個參數,0,1表示第一列和第二列,-1表示最后一列
data = np.array(df.iloc[:100, [0, 1, -1]])
# 數組切割,X切除了最后一列;y僅切最后一列
X, y = data[:, :-1], data[:, -1]
# 數據整理,將y中非1的改為-1
y = np.array([1 if i == 1 else -1 for i in y])
# 數據線性可分,二分類數據
# 此處為一元一次線性方程
class Model:
def __init__(self):
# w初始為自變量個數相同的(1,1)陣
self.w = np.ones(len(data[0]) - 1, dtype=np.float32)
self.b = 0
# 學習率設置為0.1
self.l_rate = 0.1
def sign(self, x, w, b):
# dot函數為點乘,區別于*乘。
# dot對矩陣運算的時候為矩陣乘法,一行乘一列。
# *乘對矩陣運算的時候,是對應元素相乘
y = np.dot(x, w) + b
return y
# 隨機梯度下降法
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
# 記錄當前的分類錯誤的點數,當分類錯誤的點數歸零的時候,即分類結束
wrong_count = 0
# d從0-49遍歷
for d in range(len(X_train)):
# 這里的X為一行兩列數組
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0:
self.w = self.w + self.l_rate * np.dot(y, X)
self.b = self.b + self.l_rate * y
wrong_count += 1
if wrong_count == 0:
is_wrong = True
return 'Perceptron Model!'
def score(self):
pass
perceptron = Model()
# 對perception進行梯度下降
perceptron.fit(X, y)
print(perceptron.w)
x_points = np.linspace(4, 7, 10)
# 最后擬合的函數瑞如下:
# w1*x1 + w2*x2 + b = 0
# 其中x1就是下邊的x_points,x2就是y_
y_ = -(perceptron.w[0] * x_points + perceptron.b) / perceptron.w[1]
plot.plot(x_points, y_)
# scatter兩個屬性分別對應于x,y。
# 先畫出了前50個點的花萼長度寬度,這時的花類型是0;
# 接著畫50-100,這時花類型1
plot.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plot.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
# 橫坐標名稱
plot.xlabel('sepal length')
# 縱坐標名稱
plot.ylabel('sepal width')
plot.legend()
plot.show()結果如圖
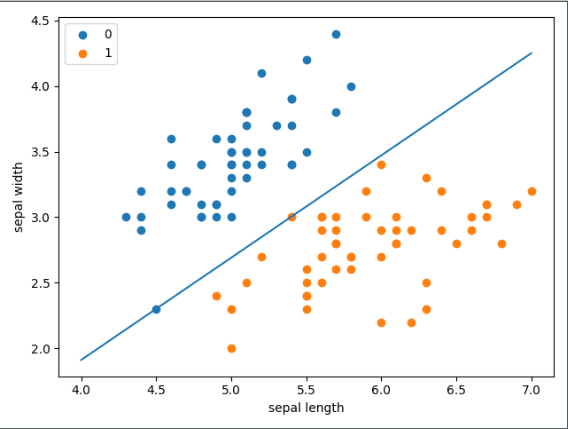
2. sklearn中提供了現成的感知機方法,我們可以直接調用
import sklearn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
# df.columns = [
# 'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
# ]
data = np.array(df.iloc[:100, [0, 1, -1]])
X, y = data[:, :-1], data[:, -1]
y = np.array([1 if i == 1 else -1 for i in y])
clf = Perceptron(fit_intercept=True, # true表示估計截距
max_iter=1000, # 訓練數據的最大次數
shuffle=True, # 每次訓練之后是否重新訓練
tol=None) # 如果不設置none那么迭代將在誤差小于1e-3結束
clf.fit(X, y)
# 輸出粘合之后的w
print(clf.coef_)
# 輸出擬合之后的截距b
print(clf.intercept_)
# 畫布大小
plt.figure(figsize=(10, 10))
# 中文標題
# plt.rcParams['font.sans-serif'] = ['SimHei']
# plt.rcParams['axes.unicode_minus'] = False
# plt.title('鳶尾花線性數據示例')
plt.scatter(data[:50, 0], data[:50, 1], c='b', label='Iris-setosa',)
plt.scatter(data[50:100, 0], data[50:100, 1], c='orange', label='Iris-versicolor')
# 畫感知機的線
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
# 其他部分
plt.legend() # 顯示圖例
plt.grid(False) # 不顯示網格
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()結果如圖
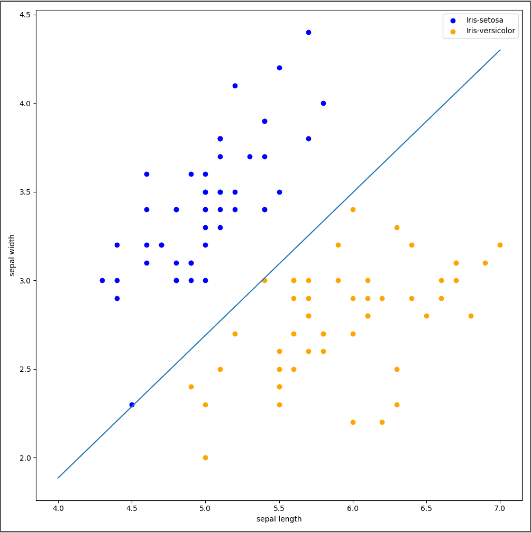
看完上述內容,你們對python中怎么模擬感知機算法有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





