溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“pandas的基礎用法”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
import pandas as pd
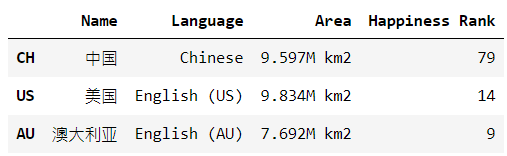
country1 = pd.Series({'Name': '中國',
'Language': 'Chinese',
'Area': '9.597M km2',
'Happiness Rank': 79})
country2 = pd.Series({'Name': '美國',
'Language': 'English (US)',
'Area': '9.834M km2',
'Happiness Rank': 14})
country3 = pd.Series({'Name': '澳大利亞',
'Language': 'English (AU)',
'Area': '7.692M km2',
'Happiness Rank': 9})
df = pd.DataFrame([country1, country2, country3], index=['CH', 'US', 'AU'])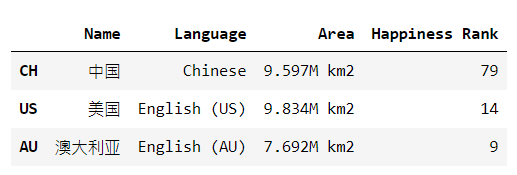
df = pd.DataFrame(columns=["epoch", "train_loss", "train_auc", "test_loss", "test_auc"])
log_dic = {"epoch": 1,
"train_loss": 0.2,
"train_auc": 1.,
"test_loss": 0,
"test_auc": 0
}
df = df.append([log_dic])
log_dic = {"epoch": 2,
"train_loss": 0.2,
"train_auc": 1.,
"test_loss": 0,
"test_auc": 0
}
df = df.append([log_dic])
# 對index進行重新編號
# inplace=True表示在原數據上修改
# drop=True表示丟棄之前的index
df.reset_index(inplace=True, drop=True)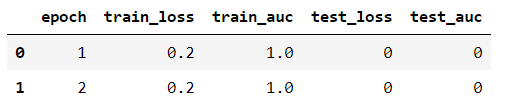
df1 = pd.DataFrame(columns=["epoch", "train_loss", "train_auc", "test_loss", "test_auc"])
log_dic = {"epoch": 1,
"train_loss": 0.2,
"train_auc": 1.,
"test_loss": 0,
"test_auc": 0
}
df1 = df1.append([log_dic])
df2 = pd.DataFrame(columns=["epoch", "train_loss", "train_auc", "test_loss", "test_auc"])
log_dic = {"epoch": 2,
"train_loss": 0.1,
"train_auc": 1.,
"test_loss": 0,
"test_auc": 1
}
df2 = df2.append([log_dic])
# ignore_index=True表示重新對index進行編號
df_new = pd.concat([df1, df2], axis=0, ignore_index=True)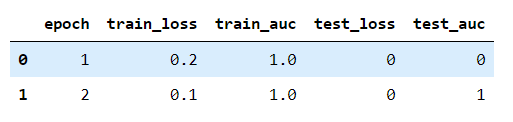
columns = ["epoch", "train_loss", "train_auc", "test_loss", "test_auc"]
df_new[header].to_csv('text.txt', index=False, header=columns, sep='\t')
df_new[header].to_csv('text.txt', index=False, header=None, sep='\t')
df = pd.read_csv('text.txt', sep='\t', header=None, nrows=100)
df.columns = ["epoch", "train_loss", "train_auc", "test_loss", "test_auc"]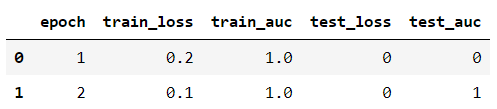
# 需要使用header參數指定columns在第幾行,通常是第0行
df = pd.read_csv('text.txt', sep='\t', header=[0])
#指定特定columns讀取
reprot_2016_df = pd.read_csv('2016.csv',
index_col='Country',
usecols=['Country', 'Happiness Rank', 'Happiness Score', 'Region'])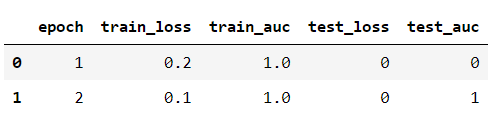
df = pd.DataFrame(columns=["epoch", "train_loss", "train_auc", "test_loss", "test_auc"])
log_dic = {"epoch": 2,
"train_loss": 0.1,
"train_auc": 1.,
"test_loss": 23,
"test_auc": 1
}
df = df.append([log_dic])
df.to_pickle('df_log.pickle')6. 加載pickle文件
df = pd.read_pickle('df_log.pickle')使用下圖的數據為例子
df.loc['CH'] # Series類型

df.loc['CH'].index # Index(['Name', 'Language', 'Area', 'Happiness Rank'], dtype='object') df.loc['CH']['Name'] # '中國' df.loc['CH'].to_numpy() # array(['中國', 'Chinese', '9.597M km2', 79], dtype=object)
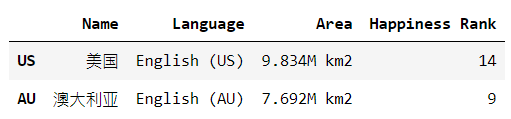
df.iloc[1] # 索引第二行

df.loc[['CH', 'US']] df.iloc[[0, 1]]
df['Area'] # type: Series df[['Name', 'Area']] # type: DataFrame

print('先取出列,再取行:')
print(df['Area']['CH'])
print(df['Area'].loc['CH'])
print(df['Area'].iloc[0])
print('先取出行,再取列:')
print(df.loc['CH']['Area'])
print(df.iloc[0]['Area'])
print(df.at['CH', 'Area'])
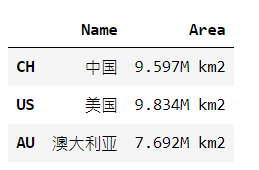
df.drop(['CH'], inplace=True) # 刪除行 inplace=True表示在原數據上修改 df.drop(['Area'], axis=1, inplace=True) # 刪除列,需要指定axis=1
使用下面的數據
import numpy as np
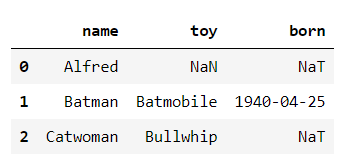
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),pd.NaT]
}) 
""" axis: 0: 行操作(默認) 1: 列操作 how: any: 只要有空值就刪除(默認) all:全部為空值才刪除 inplace: False: 返回新的數據集(默認) True: 在愿數據集上操作 """ df.dropna(axis=0, how='any', inplace=True)

df.dropna(axis=0, how='any', subset=['toy'], inplace=False) # subset指定操作特定列的nan
使用下面的數據
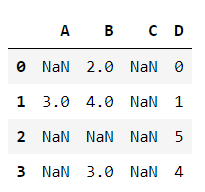
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))df.fillna(0, inplace=True)

# "橫向用缺失值前面的值替換缺失值" df.fillna(axis=1, method='ffill', inplace=False)
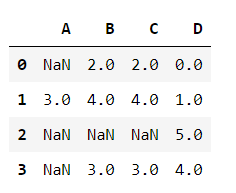
# "縱向用缺失值上面的值替換缺失值" df.fillna(axis=0, method='bfill', inplace=False)
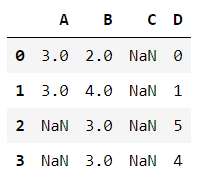
df['A'].fillna(0, inplace=True) # 指定特定列填充
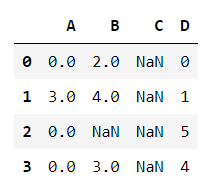
df.isnull() df['A'].isna()


import pandas as pd
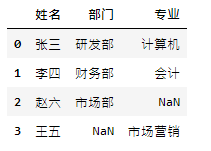
staff_df = pd.DataFrame([{'姓名': '張三', '部門': '研發部'},
{'姓名': '李四', '部門': '財務部'},
{'姓名': '趙六', '部門': '市場部'}])
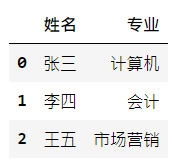
student_df = pd.DataFrame([{'姓名': '張三', '專業': '計算機'},
{'姓名': '李四', '專業': '會計'},
{'姓名': '王五', '專業': '市場營銷'}])
inner(交集) outer(并集) left right
pd.merge(staff_df, student_df, how='inner', on='姓名') pd.merge(staff_df, student_df, how='outer', on='姓名')

# 設置姓名為索引
staff_df.set_index('姓名', inplace=True)
student_df.set_index('姓名', inplace=True)
pd.merge(staff_df, student_df, how='left', left_index=True, right_index=True)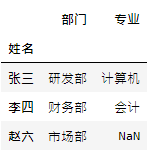
# 重置index為range()
staff_df.reset_index(inplace=True)
student_df.reset_index(inplace=True)
staff_df.rename(columns={'姓名': '員工姓名'}, inplace=True)
student_df.rename(columns={'姓名': '學生姓名'}, inplace=True)
pd.merge(staff_df, student_df, how='left', left_on='員工姓名', right_on='學生姓名')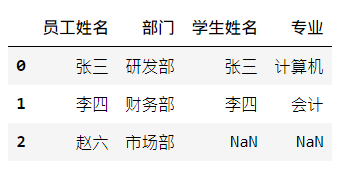
pd.merge(staff_df, student_df, how='inner', left_on=['員工姓名', '地址'], right_on=['學生姓名', '地址'])
report_data = pd.read_csv('./2015.csv')
report_data.head()
data.head() data.info() data.describe() data.columns data.index
df.rename(columns={'Region': '地區', 'Happiness Rank': '排名', 'Happiness Score': '幸福指數'}, inplace=True)# null替換成0 df.fillna(0, inplace=False) # 丟棄null df.dropna() # 前向填充 df.ffill() # 后向填充 df.bfill(inplace=True)
# apply使用 # 獲取姓 staff_df['員工姓名'].apply(lambda x: x[0]) # 獲取名 staff_df['員工姓名'].apply(lambda x: x[1:]) # 結果合并 staff_df.loc[:, '姓'] = staff_df['員工姓名'].apply(lambda x: x[0]) staff_df.loc[:, '名'] = staff_df['員工姓名'].apply(lambda x: x[1:])
依據columns分組
grouped = report_data.groupby('Region')
grouped['Happiness Score'].mean()
grouped.size()
# 迭代groupby對象
for group, frame in grouped:
mean_score = frame['Happiness Score'].mean()
max_score = frame['Happiness Score'].max()
min_score = frame['Happiness Score'].min()
print('{}地區的平均幸福指數:{},最高幸福指數:{},最低幸福指數{}'.format(group, mean_score, max_score, min_score))定義函數分組
report_data2 = report_data.set_index('Happiness Rank')
def get_rank_group(rank):
rank_group = ''
if rank <= 10:
rank_group = '0 -- 10'
elif rank <= 20:
rank_group = '10 -- 20'
else:
rank_group = '> 20'
return rank_group
grouped = report_data2.groupby(get_rank_group)
for group, frame in grouped:
print('{}分組的數據個數:{}'.format(group, len(frame)))# 實際項目中,通常可以先人為構造出一個分組列,然后再進行groupby
# 按照score的整數部分進行分組
# 按照幸福指數排名進行劃分,1-10, 10-20, >20
# 如果自定義函數,操作針對的是index
report_data['score group'] = report_data['Happiness Score'].apply(lambda score: int(score))
grouped = report_data.groupby('score group')
for group, frame in grouped:
print('幸福指數整數部分為{}的分組數據個數:{}'.format(group, len(frame)))使用bar類型的柱狀圖統計每個label的個數。
train_df.label.value_counts().plot(kind='bar')
“pandas的基礎用法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





