溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Hive中Join的原理和機制是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
籠統的說,Hive中的Join可分為Common Join(Reduce階段完成join)和Map Join(Map階段完成join)。本文簡單介紹一下兩種join的原理和機制。
如果不指定MapJoin或者不符合MapJoin的條件,那么Hive解析器會將Join操作轉換成Common Join,即:在Reduce階段完成join.
整個過程包含Map、Shuffle、Reduce階段。
Map階段
讀取源表的數據,Map輸出時候以Join on條件中的列為key,如果Join有多個關聯鍵,則以這些關聯鍵的組合作為key;
Map輸出的value為join之后所關心的(select或者where中需要用到的)列;同時在value中還會包含表的Tag信息,用于標明此value對應哪個表;
按照key進行排序
Shuffle階段
根據key的值進行hash,并將key/value按照hash值推送至不同的reduce中,這樣確保兩個表中相同的key位于同一個reduce中
Reduce階段
根據key的值完成join操作,期間通過Tag來識別不同表中的數據。
以下面的HQL為例,圖解其過程:
SELECT
a.id,a.dept,b.age
FROM a join b
ON (a.id = b.id);
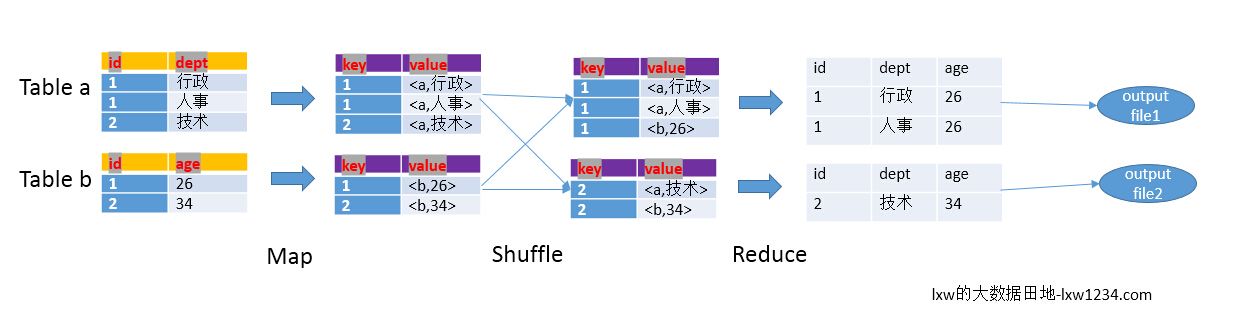
看了這個圖,應該知道如何使用MapReduce進行join操作了吧。
MapJoin通常用于一個很小的表和一個大表進行join的場景,具體小表有多小,由參數hive.mapjoin.smalltable.filesize來決定,該參數表示小表的總大小,默認值為25000000字節,即25M。
Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才會執行MapJoin,否則執行Common Join,但在0.7版本之后,默認自動會轉換Map Join,由參數hive.auto.convert.join來控制,默認為true.
仍然以9.1中的HQL來說吧,假設a表為一張大表,b為小表,并且hive.auto.convert.join=true,那么Hive在執行時候會自動轉化為MapJoin。
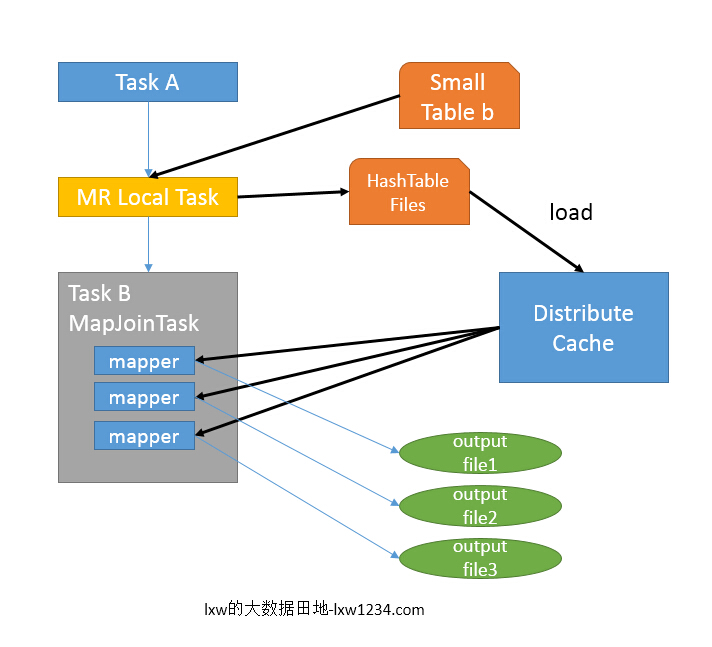
如圖中的流程,首先是Task A,它是一個Local Task(在客戶端本地執行的Task),負責掃描小表b的數據,將其轉換成一個HashTable的數據結構,并寫入本地的文件中,之后將該文件加載到DistributeCache中,該HashTable的數據結構可以抽象為:
| key | value |
| 1 | 26 |
| 2 | 34 |

圖中紅框圈出了執行Local Task的信息。
接下來是Task B,該任務是一個沒有Reduce的MR,啟動MapTasks掃描大表a,在Map階段,根據a的每一條記錄去和DistributeCache中b表對應的HashTable關聯,并直接輸出結果。
由于MapJoin沒有Reduce,所以由Map直接輸出結果文件,有多少個Map Task,就有多少個結果文件。
“Hive中Join的原理和機制是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





