溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關怎么用Python爬取學校專業的數據,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
今天各地的2020年高考成績陸續可以查詢了,考生的志愿填報也隨即提上日程。
俗話說,七分考,三分報。想必同學們一定不想因高分低報而浪費分數,也不想低分高報而與大學失之交臂。
如何獲取數據
我們使用Python獲取了中國教育在線網站的高校數據,共2904條。以下展示數據獲取部分代碼:
https://gkcx.eol.cn/school/search
具體思路如下:
分析網頁,通過翻頁可以發現數據是動態加載的,因此通過Chrome瀏覽器進行抓包分析獲取真實的URL請求地址,并確定請求方式(get還是post);
使用requests請求網頁數據;
使用json解析并提取數據;
使用pandas將數據保存到本地
首先打開網址,使用Chrome瀏覽器的檢查功能,切換到Network-XHR,點擊翻頁進行網絡數據抓包,很容易發現數據都是被封裝在json中的,如下圖所示:
切換到Headers處,確定請求的方法為post請求,得到數據請求的URL地址,其中page參數代表頁數,通過遍歷即可獲取所有數據。代碼如下:
# 導入包
import numpy as np
import pandas as pd
import requests
import json
from fake_useragent import UserAgent
import time
# 獲取一頁
def get_one_page(page_num):
# 獲取URL
url = 'https://api.eol.cn/gkcx/api/'
# 構造headers
headers = {
'User-Agent': UserAgent().random,
'Origin': 'https://gkcx.eol.cn',
'Referer': 'https://gkcx.eol.cn/school/search?province=&schoolflag=&recomschprop=',
}
# 構造data
data = {
'access_token': "",
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': page_num,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "apigkcx/api/school/hotlists",
}
# 發起請求
try:
response = requests.post(url=url, data=data, headers=headers)
except Exception as e:
print(e)
time.sleep(3)
response = requests.post(url=url, data=data, headers=headers)
# 解析獲取數據
school_data = json.loads(response.text)['data']['item']
# 學校名
school_name = [i.get('name') for i in school_data]
# 隸屬部門
belong = [i.get('belong') for i in school_data]
# 高校層次
dual_class_name = [i.get('dual_class_name') for i in school_data]
# 是否985
f985 = [i.get('f985') for i in school_data]
# 是否211
f211 = [i.get('f211') for i in school_data]
# 辦學類型
level_name = [i.get('level_name') for i in school_data]
# 院校類型
type_name = [i.get('type_name') for i in school_data]
# 是否公辦
nature_name = [i.get('nature_name') for i in school_data]
# 人氣值
view_total = [i.get('view_total') for i in school_data]
# 省份
province_name = [i.get('province_name') for i in school_data]
# 城市
city_name = [i.get('city_name') for i in school_data]
# 區域
county_name = [i.get('county_name') for i in school_data]
# 保存數據
df_one = pd.DataFrame({
'school_name': school_name,
'belong': belong,
'dual_class_name': dual_class_name,
'f985': f985,
'f211': f211,
'level_name': level_name,
'type_name': type_name,
'nature_name': nature_name,
'view_total': view_total,
'province_name': province_name,
'city_name': city_name,
'county_name': county_name,
})
return df_one
# 獲取多頁
def get_all_page(all_page_num):
# 存儲表
df_all = pd.DataFrame()
# 循環頁數
for i in range(all_page_num):
# 打印進度
print(f'正在獲取第{i + 1}頁的高校信息')
# 調用函數
df_one = get_one_page(page_num=i+1)
# 追加
df_all = df_all.append(df_one, ignore_index=True)
# 隨機休眠
time.sleep(np.random.uniform(2))
return df_all
if __name__ == '__main__':
# 運行函數
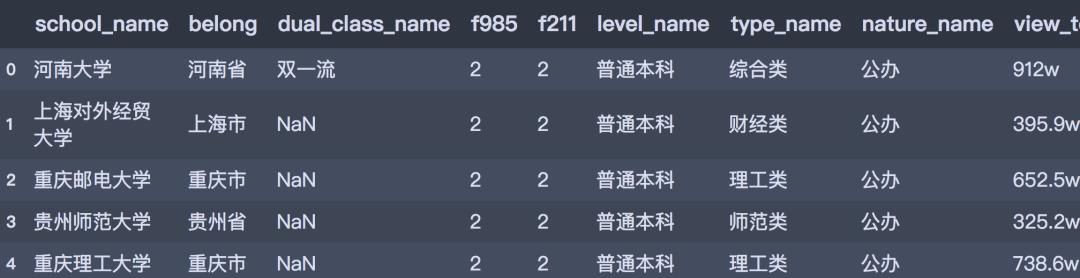
df = get_all_page(all_page_num=148)通過上述程序,共獲取到2904條數據,數據預覽如下:
df.head()
以上就是怎么用Python爬取學校專業的數據,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





