溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python如何爬取指定百度搜索的內容并提取網頁的標題內容,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
hello,大家好。今天為大家帶來的是之前分享過的requests庫與lxml庫的結合使用案例一:指定百度搜索的內容并提取網頁的標題內容。好的,廢話不多說,直接上主菜。
下面我們來完成我們的第一步,分析我們的目標。大家可千萬不要小看這一步哦,因為我們只有思路清晰才能在較短的時間里面寫出漂亮的代碼。
首先,我們想要請求網頁,必須知道我們的url(即網址)是什么。下面,我打開Chrome(谷歌)瀏覽器,并且打開百度頁面,指定搜索“python”,得到下圖結果:
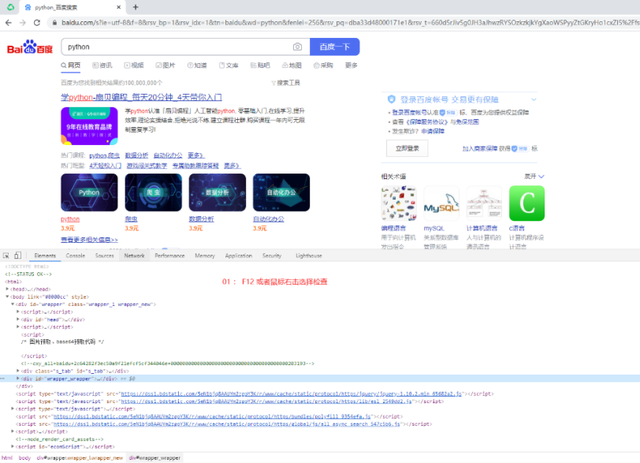
寫python程序,有時候很矛盾,是用面向對象呢?還是面向過程呢?其實都隨意(我比較隨意,因為沒有人要求我必須使用什么寫),這里我采取面向對象的方式來寫這個程序。
#文件一
import requests
class MySpider(object):
def __init__(self):
self.url = 'http://www.baidu.com/s?wd={name}' #這里采用format的格式化輸入
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
def main(self):
#處理url
self.target = input('請輸入你感興趣的內容:')
self.url = self.url.format(name=self.target) #重新構建url,大家測試的時候可以嘗試打印
#請求
text = self.get()
#寫入文件
self.write(text)
def get(self):
'''請求并返回網頁源代碼'''
pass
def write(self,text):
'''將返回的源代碼寫入文件,等待之后解析用'''
pass
if __name__ == '__main__':
spider = MySpider()
spider.main()這里有幾個原因。
1>我們寫代碼,一般來說都不可能一次寫成功,總是需要修改和測試的。平時我們寫代碼,自然可以隨意的測試運行,都可以檢測代碼是否正確,但是爬蟲卻不能這樣。因為如果你在較短時間內訪問了網站次數過多,可能會導致網站對你做出一些限制性舉動,比如:增加驗證碼判斷你是否為人類,嚴重點的短時間內封禁你的ip。因此,我們將網頁源代碼寫入文件,這樣在之后寫解析代碼的時候就不需要重新去訪問網站了。
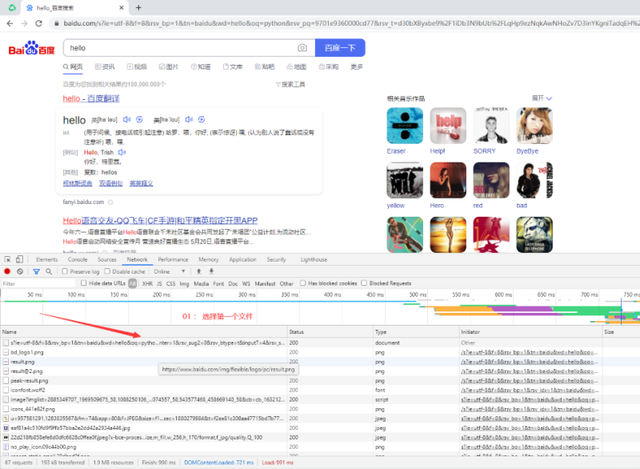
2>我們以html的形式寫入文件,可以用瀏覽器打開這個文件,可以比較清晰的看出這個文件是否為我們需要爬取的文件。如下圖是我爬取后存入的文件以谷歌瀏覽器打開的結果:
下面我們來完成獲取頁面的程序代碼:
def get(self): '''請求并返回網頁源代碼''' response = requests.get(self.url,self.headers) if response.status_code == 200: return response.text
這個沒什么好說的,是最基礎的代碼。
def write(self,text):
with open('%s.html'%self.target,'w',encoding='utf-8') as f: #這里的self.target為輸入搜索的內容
f.write(text)這個也只是文件的基本操作,沒什么好講解的地方,只是注意我們這里存入的為html文件,而不是txt文件。
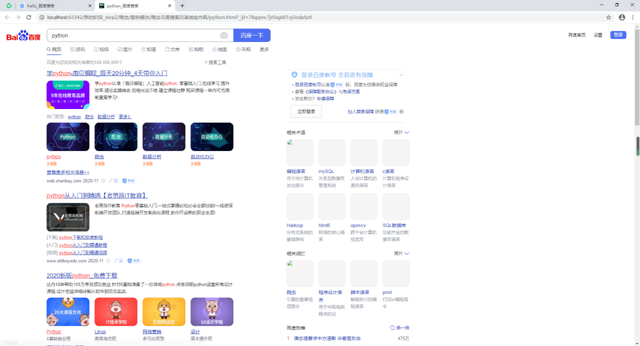
這里檢測的方式我前面已經提及,就是瀏覽器打開相應的頁面即可。如下圖操作:
說明程序正常運行。
from lxml import etree
class Parse(object):
def __init__(self):
#讀取內容并且初始化
with open('python.html','r',encoding='utf-8') as f:
self.html = etree.HTML(f.read())
#解析頁面
def parse(self):
pass
if __name__ == '__main__':
parser = Parse()
parser.parse()下面我們來完成最后一步,解析函數的敲寫。
首先我們需要分析下,我們想要獲取的內容在什么標簽里面。分析過程如圖(個人認為這部分比較重要,因為我初學的時候主要困惑于兩點:如何處理失敗的請求,解析的思路是什么)
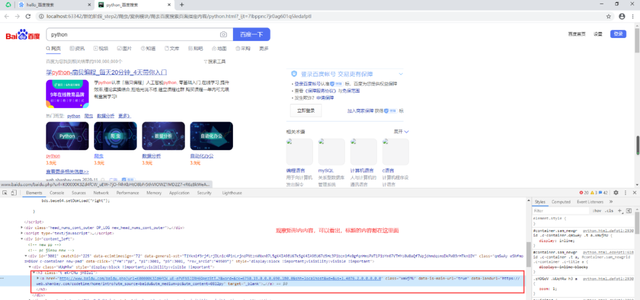
好的,分析清楚了我們需要的內容在哪里之后,可以使用lxml來寫代碼了,如下:
def parse(self):
#獲取url
h4_tags = self.html.xpath('//h4[contains(@class,"t")]//text()')
h4_tags = [i.strip() for i in h4_tags]
print(h4_tags)下面要做的工作就是處理這些字符串,但是這個并不是我們的重點,并且這些數據并不重要,所以就不處理了。
# -*- coding:utf-8 -*-
#獲取網頁內容文件
import requests
class MySpider(object):
def __init__(self):
self.url = 'http://www.baidu.com/s?wd={name}'
#寫清楚獲取headers途徑
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
def main(self):
#處理url
self.target = input('請輸入你感興趣的內容:')
self.url = self.url.format(name=self.target)
#請求
text = self.get()
#寫入文件
# self.write(text)
def get(self):
'''請求并返回網頁源代碼'''
response = requests.get(self.url,self.headers)
if response.status_code == 200:
return response.text
def write(self,text):
with open('%s.html'%self.target,'w',encoding='utf-8') as f:
f.write(text)
if __name__ == '__main__':
spider = MySpider()
spider.main()# -*- coding:utf-8 -*-
#解析頁面文件
from lxml import etree
class Parse(object):
def __init__(self):
with open('python.html','r',encoding='utf-8') as f:
self.html = etree.HTML(f.read())
def parse(self):
#獲取標題
h4_tags = self.html.xpath('//h4[contains(@class,"t")]//text()')
h4_tags = [i.strip() for i in h4_tags]
print(h4_tags)
if __name__ == '__main__':
parser = Parse()
parser.parse()好的,今天的分享就到此為止了。這是最基礎的案例,主要目的是讓大家先熟悉下,如何使用requests和lxml寫一個爬蟲程序,其次就是讓大家熟悉下分析網站的思路。
關于Python如何爬取指定百度搜索的內容并提取網頁的標題內容問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





