溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關java使用url如何實現爬取網頁中的內容,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
運行效果:
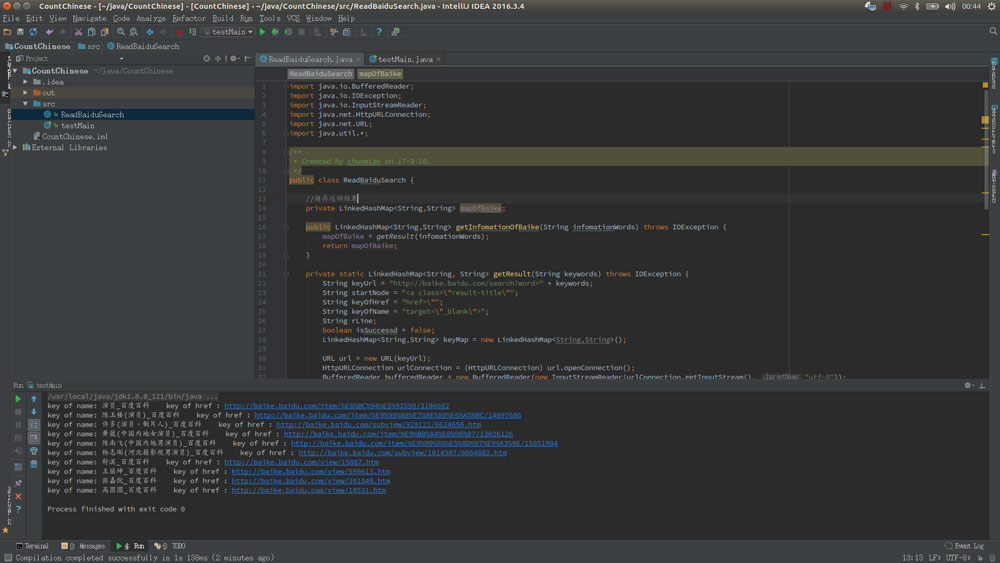
首先打開百度百科,搜索詞條,比如“演員”,再按F12查看源碼
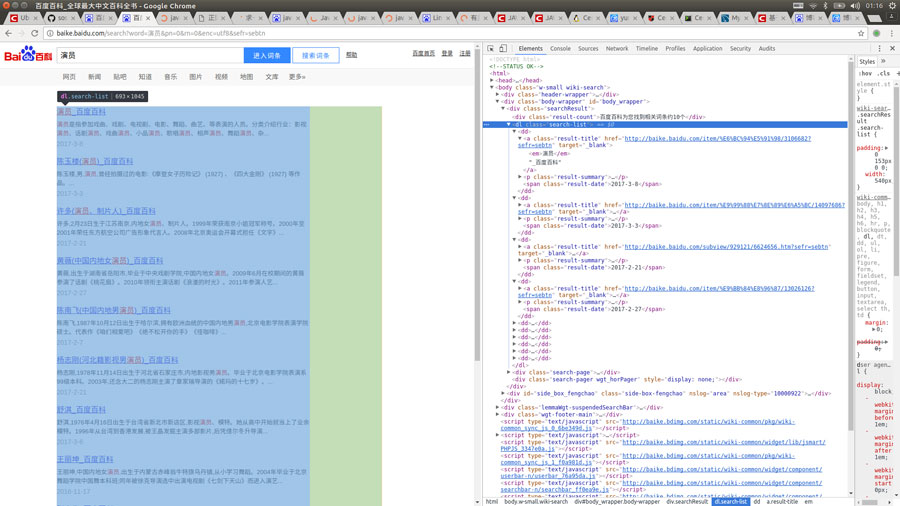
然后抓取你想要的標簽,注入LinkedHashMap里面就ok了,很簡單是吧!看看代碼羅
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//儲存返回結果
private LinkedHashMap<String,String> mapOfBaike;
//獲取搜索信息
public LinkedHashMap<String,String> getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通過網絡鏈接獲取信息
private static LinkedHashMap<String, String> getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索詞條的節點
String startNode = "<dl class=\"search-list\">";
//詞條的鏈接關鍵字
String keyOfHref = "href=\"";
//詞條的標題關鍵字
String keyOfTitle = "target=\"_blank\">";
String endNode = "</dl>";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap<String,String> keyMap = new LinkedHashMap<String,String>();
//開始網絡請求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//讀取網頁內容
while ((rLine = bufferedReader.readLine()) != null){
//判斷目標節點是否出現
if(rLine.contains(startNode)){
isNode = true;
}
//若目標節點出現,則開始抓取數據
if (isNode){
//若目標結束節點出現,則結束讀取,節省讀取時間
if (rLine.contains(endNode)) {
//關閉讀取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值為空則不讀取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//獲取詞條對應的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//獲取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//獲取的url中可能不含baikeUrl,如果沒有則在頭部添加一個
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//獲取詞條對應的名稱
private static String getName(String rLine,String keyOfTitle){
String result = "";
//獲取標題內容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//將標題中的內容含有的標簽去掉
result = result.replaceAll("<em>|</em>|</a>|<a>","");
}
return result;
}
}上述就是小編為大家分享的java使用url如何實現爬取網頁中的內容了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





