溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“lucene4.7高亮功能怎么實現”,在日常操作中,相信很多人在lucene4.7高亮功能怎么實現問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”lucene4.7高亮功能怎么實現”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
高亮功能一直都是全文檢索的一項非常優秀的模塊,在一個標準的搜索引擎中,高亮的返回命中結果,幾乎是必不可少的一項需求,因為通過高亮,我們可以在我們的搜索界面上快速標記出用戶的檢索關鍵詞,從而減少了用戶自己尋找想要的結果,在一定程度上大大提高了用戶的體驗性和友好度。
首先還是喜歡老生常談的來補充下高亮需要的熟悉的基本知識,當然如果你只是需要實現效果,而不關注它的底層API,那么可以忽略此部分,不過還是要友好的提示一下,如果使用過程中出了點小問題,不會API,可是不容易解決的,除非你愿意各種google。
要使用高亮,首先就得從索引時開始,因為需要高亮的字段,需要準確的獲取位置信息,以及一些偏移量,如果信息不準確,那么可能在結果中,就會出現一些莫名其妙的錯位,反映到網頁上就是標注了不該標注的字,沒有標注該標的內容,所以這一點還是需要注意一下,在索引的時候,我們需要使用項向量記錄各個token的位置信息,這很簡單,代碼如下:
FieldType type=new FieldType(TextField.TYPE_STORED);
type.setStoreTermVectorOffsets(true);//記錄相對增量
type.setStoreTermVectorPositions(true);//記錄位置信息
type.setStoreTermVectors(true);//存儲向量信息
type.freeze();//阻止改動信息
Field field=new Field("字段名", "值", type);//示例簡單說下,TextField的2個枚舉變量的意思
| 變量名 | 釋義 |
| TYPE_NOT_STORED | 索引,分詞,不存儲 |
| TYPE_STORED | 索引,分詞,存儲 |
由此看來,需要進行高亮的內容,是一定要存儲的,可能有一些比較大的文本,會比較占索引空間,從而影響檢索性能,當然我們也可以使用外部存儲,關系型數據庫,nosql什么的都可以,此時,高亮可能就需要做另一些處理了。
下面我們來看下,高亮的需要用到的一些基本的類
| 類 | 釋義 |
| SimpleHTMLFormatter | 常用的格式化Html標簽器,提供一個構造函數傳入高亮顏色標簽,默認使用黑色 |
| TokenSources | 提供靜態方法,支持從數據源中獲取TokenStream,進行token處理 |
| Highlighter | 負責獲取匹配上的高亮片段 |
| QueryScorer | 對命中結果進行評分操作 |
| Fragmenter | 將原始字符串拆分成獨立的片段 |
| NullFragmenter | 對較短的域進行整體高亮 |
| FastVectorHighlighter | 基于快速高亮 |
| Encoder | 提供一些實現類,對html文本操作,如,去掉一些特殊匹配符號<,> and so on,及一些其他的非ASCII特殊字符。 |
下面我們先來看下散仙的幾條測試數據內容:
id:1 name: 中國是一個偉大的國家,我們中國人都是好樣的哈哈,中國永遠是強大的 content: 你好人民 id:2 name: 我們有一個家它的名字是中國 content: 中國的大地,富饒 id:3 name: 我們的中國,我們的大地都是人民的希望的 content: 如果不在片段中生成一些字段的話 id:4 name: 2014年此時此刻你在做什么的啊 content: 哈哈鋤禾日當午 id:5 name: 當你孤單時你會想起誰,你想不想找個人來陪 content: 我永遠不孤單啊
1,測試普通高亮的核心代碼:
String filed="name";
QueryParser query=new QueryParser(Version.LUCENE_44, filed, new IKAnalyzer(false));
Query q=query.parse("偉大的中國");//測試字段
TopDocs top=searcher.search(q, 100);
QueryScorer score=new QueryScorer(q, filed);//傳入評分
SimpleHTMLFormatter fors=new SimpleHTMLFormatter("<span style=\"color:red;\">", "</span>");//定制高亮標簽
Highlighter highlighter=new Highlighter(fors,score);//高亮分析器
// highlighter.setMaxDocCharsToAnalyze(1);//設置高亮處理的字符個數
for(ScoreDoc sd:top.scoreDocs){
Document doc=searcher.doc(sd.doc);
String name=doc.get(filed);
TokenStream token=TokenSources.getAnyTokenStream(searcher.getIndexReader(), sd.doc, filed, new IKAnalyzer(true));//獲取tokenstream
Fragmenter fragment=new SimpleSpanFragmenter(score);
highlighter.setTextFragmenter(fragment);
String str=highlighter.getBestFragment(token, name);//獲取高亮的片段,可以對其數量進行限制
System.out.println("高亮的片段 =====>"+str);
}輸出結果如下
高亮的片段 =====>中國是一個<span >偉大</span><span >的</span>國家,我們中國人都是好樣<span >的</span>哈哈,<span >中國</span>永遠是強大<span >的</span> 高亮的片段 =====>我們<span >的</span><span >中國</span>,我們<span >的</span>大地都是人民<span >的</span>希望<span >的</span> 高亮的片段 =====>我們有一個家它<span >的</span>名字是<span >中國</span>
2,快速高亮,FastVectorHighlighter,這個類可能會消耗更多的存儲空間,來換取更好的性能,當然除了性能上提升外,它還有一個非常炫的功能,支持多種顏色標記,高亮關鍵字,除此之外還支持Ngram的域,以及智能合并相鄰高亮短語.
我們來看下散仙快速高亮的3條測試數據:
id:2 name: 中國(China),位于東亞,是一個以華夏文明為主體、中華文化為基礎,以漢族為主要種族的統一多民族國家,通用漢語。中國疆域內的各個民族統稱為中華民族,龍是中華民族的象征。 content: 中國是世界四大文明古國之一,有著悠久的歷史,距今約5000年前,以中原地區為中心開始出現聚落組織進而成國家和朝代,后歷經多次演變和朝代更迭,持續時間較長的朝代有夏、商、周、漢、晉、唐、宋、元、明、清等 id:1 name: 中國的自古以來就是一個非常偉大的民族 content: 中國是一個世界人口大國,擁有13億多的人口. id:3 name: 沒有根的野草,飄忽的命運 content: 誰像你當我寶,什么也做到,舊愛數足一塊布,在這一刻寫句號,只想跟你終老.
核心代碼如下:
Query q=query.parse("偉大的中華民族");
TopDocs top=searcher.search(q, 100);
//QueryScorer score=new QueryScorer(q, filed);
//SimpleHTMLFormatter fors=new SimpleHTMLFormatter("<span style=\"color:red;\">", "</span>");//定制高亮標簽
//Highlighter highlighter=new Highlighter(fors,score);//高亮分析器
//FastVectorHighlighter fastHighlighter=new FastVectorHighlighter();
FragListBuilder fragListBuilder=new SimpleFragListBuilder();
//注意下面的構造函數里,使用的是顏色數組,用來支持多種顏色高亮
FragmentsBuilder fragmentsBuilder= new ScoreOrderFragmentsBuilder(BaseFragmentsBuilder.COLORED_PRE_TAGS,BaseFragmentsBuilder.COLORED_POST_TAGS);
FastVectorHighlighter fastHighlighter2=new FastVectorHighlighter(true, true, fragListBuilder, fragmentsBuilder);
FieldQuery querys=fastHighlighter2.getFieldQuery(q);//reader是傳入的流
// highlighter.setMaxDocCharsToAnalyze(1);//設置高亮處理的字符個數
for(ScoreDoc sd:top.scoreDocs){
String snippt=fastHighlighter2.getBestFragment(querys, reader, sd.doc,filed,300);
if(snippt!=null){
System.out.println("高亮的片段是:"+snippt);
}
}結果如下,注意有多種顏色標識:
高亮的片段是:中國<b >的</b>自古以來就是一個非常<b >偉大</b><b >的</b>民族 高亮的片段是:中國(China),位于東亞,是一個以華夏文明為主體、中華文化為基礎,以漢族為主要種族<b >的</b>統一多民族國家,通用漢語。中國疆域內<b >的</b>各個民族統稱為<b >中華民族</b>,龍是<b >中華民族</b><b >的</b>象征。 高亮的片段是:沒有根<b >的</b>野草,飄忽<b >的</b>命運
3.下面來著重說一下,高亮的第三種方式,前臺高亮,散仙在上文曾提過,基于高亮的字段,必須的存儲,否則無法實現高亮標注,當然這種說法,只是對于后臺高亮而言的,那么對于大文本情況下,存儲到索引里是非常浪費空間的,而且還有可能會影響到檢索速度,所以就提出了,第三種方式。
在前臺進行高亮,然后大文本字段,可以存儲在外部其他的數據源里面,需要標記時,可以直接根據ID,或者某個字段,讀取數據然后通過JS正則在前端替換檢索的關鍵詞即可,在這之前需要做的一步就是,使用ajax把檢索的關鍵詞,傳入后臺進行分詞,然后將結果返回前臺,進行對分詞后的數據,進行匹配替換,再加上顏色標記,就可以在前臺實現高亮了,這也是前臺高亮的實現原理,這種做法,在某些業務場景下,可以大大減少服務器壓力,通過客戶端減壓,以及不用再存儲一些向量信息,從而對系統的性能的提高,也是有很大幫助的。
下面給出一個前臺高亮的截圖,注意用的是快速高亮的索引。
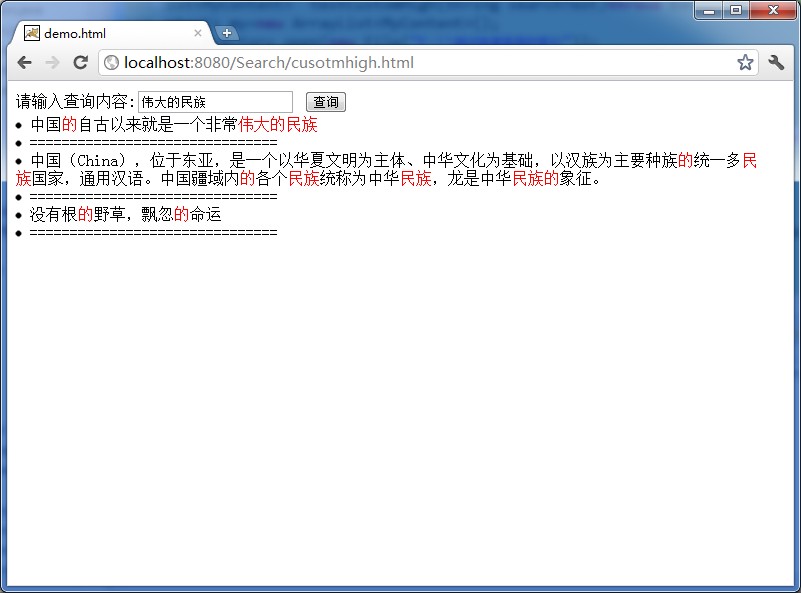
附上前臺高亮的核心代碼
$.ajax({
type :"post",
url: "getContent",
data:"str="+str,
dataType:"json",
async:false,
success:function(msg){
// alert(msg);
$("#div").empty();
$.each(msg, function(i, n) {
var temp="";
for(var i=0;i<shu.length;i++){
if(shu[i]!=""){
n.name=n.name.replace(new RegExp(shu[i],'g'), "<span style=\"color:red;\">"+shu[i]+"</span>");
}
}
$("#div").append("[*]"+n.name+"
");
$("#div").append("[*]===============================
")
});
}
});到此,關于“lucene4.7高亮功能怎么實現”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





