溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“lucene4.7排序方法怎么使用”,在日常操作中,相信很多人在lucene4.7排序方法怎么使用問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”lucene4.7排序方法怎么使用”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在這之前,我們先來熟悉下lucene中排序的基本知識,在默認情況下,Lucene使用的是以關聯性降序的方式為默認的排序方式,這樣可以使得我們搜索的結果通常是最優的,因為它會盡可能的使得首先出現的幾個結果是與我們搜索的內容最相關,而不需要我們翻頁尋找我們最想要的內容,這一點是與數據庫相比,是全文檢索一個很大的優點。當然,在實際開發中我們也需要根據業務的實際情況來給我們的客戶提供多種不同的排序方式。我們先來看下在Lucene中比較特殊的兩種基本的排序方式
| Sort里的屬性 | SortField里的屬性 | 含義 |
| Sort.INDEXORDER | SortField.FIELD_DOC | 按照索引的順序進行排序 |
| Sort.RELEVANCE | SortField.FIELD_SCORE | 按照關聯性評分進行排序 |
我們再來看幾個檢索時需要用的方法
=========SortField類============ //field是排序字段type是排序類型 public SortField(String field, Type type); //field是排序字段type是排序類型reverse是指定升序還是降序 //reverse 為true是降序 false為升序 public SortField(String field, Type type, boolean reverse) =========Sort類============ public Sort();//Sort對象構造方法默認是按文檔評分排序 public Sort(SortField field);//排序的一個SortField public Sort(SortField... fields)//排序的多個SortField可以傳入一個數組 =========IndexSearche類r======== //query是查詢的Query對象 filter是過濾 n返回的數量 sort是排序 search(Query query, Filter filter, int n, Sort sort) //doDocScores 為true情況下每個命中的結果下都會被評分 //doMaxScore 為true情況下對最大分值的搜索結果進行評分 search(Query query, Filter filter, int n, Sort sort, boolean doDocScores, boolean doMaxScore)
1,在還沒有進行一點排序前我們先來看下索引里的內容,核心代碼如下:
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000);
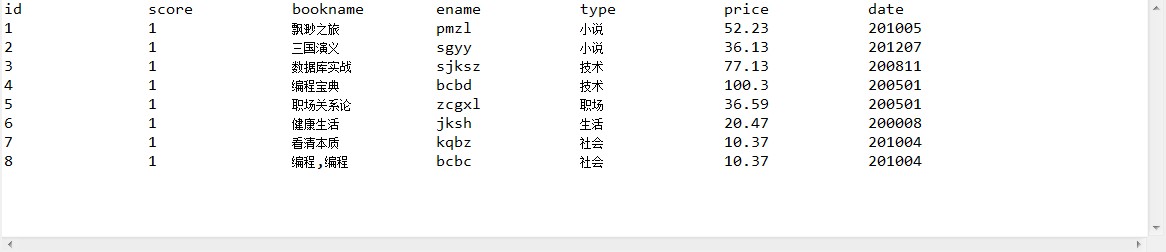
2,使用默認的關聯性評分后,核心代碼和運行效果圖如下:
Sort sort=new Sort();//默認使用關聯性評分 TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);
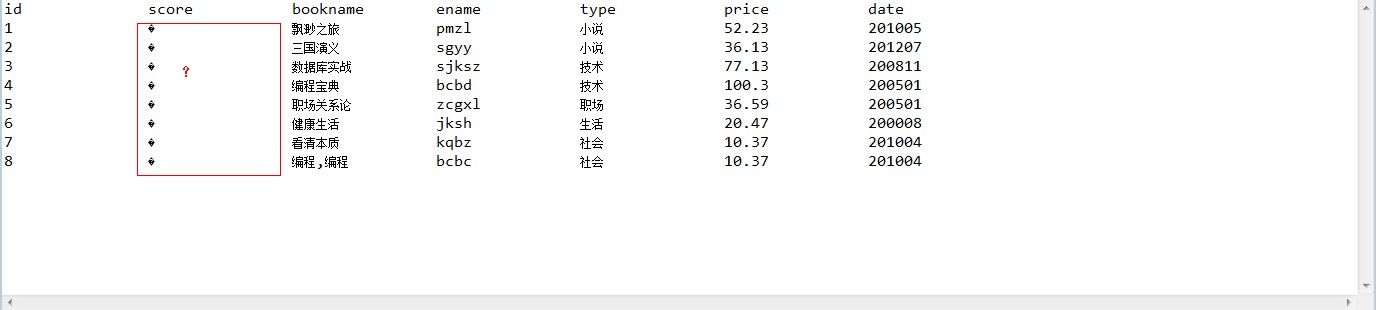
關于上圖中亂碼字符原因是因為默認排序情況下lucene是不會對搜索結果進行評分操作的,因為評分操作會降低性能,所以關于score的那一列返回的是NAN的字符串,出于格式的需要,散仙在用DecimalFormat類給其評分結果保留2位小數時,因為是一個特殊字符,所以就出現了上圖情況。
3,按照日期降序排序,,核心代碼和運行效果圖如下:
Sort sort=new Sort(new SortField("date", Type.INT,true));//true為降序排列
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);
4,按照價格升序排序,,核心代碼和運行效果圖如下:
Sort sort=new Sort(new SortField("price", Type.DOUBLE,false));//false為降序排列
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);
5,多字段排序,按照日期降序的情況下,因為id為7和8的日期相同,所以我們就新增一個排序字段按ename升序排列,,核心代碼和運行效果圖如下:
// Sort sort=new Sort(new SortField("date", Type.INT, true),new SortField("ename", Type.STRING, false));
//這兩段代碼效果一樣
Sort sort=new Sort(new SortField[]{new SortField("date", Type.INT, true),new SortField("ename", Type.STRING, false)});
TopDocs topDocs=searcher.search(new MatchAllDocsQuery(),10000,sort);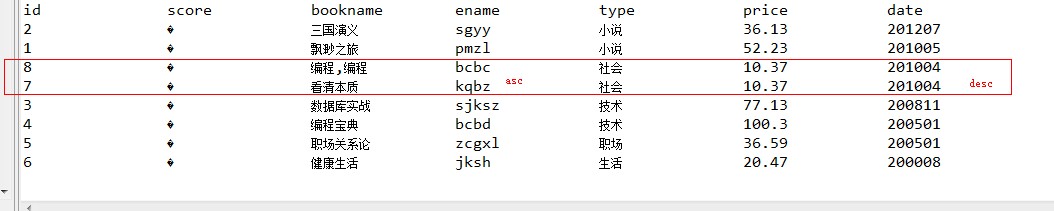
6,帶評分的排序,注意后面兩個布爾類型的變量可以控制是否評分,特別是在沒有要求需要打分時,建議別開啟,大數量時對性能影響較大,檢索“編程”得到的結果,默認按評分降序排序,核心代碼和運行效果圖如下:
Sort sort=Sort.RELEVANCE;
TopDocs topDocs=searcher.search(new TermQuery(new Term("bookname", "編程")),null,100,sort,true,true);
上面的編程,編程因為在切分時編程的tf出現了2次,所以在查詢時有較高的得分,所以排在首位。
7,注意幾點
(1)排序對一個文檔里什么域都沒存儲,使用字符串排序會排在首位
(2)排序對一個文檔里什么域都沒存儲,使用數字類型排序會默認給其賦值為0進行排序
(3)我們可以對數字類型的null值的文檔進行代碼控制,可以將其設置為最大,所以將會排在最后面,代碼如下
SortField sortField = new SortField("value", SortField.Type.INT);
sortField.setMissingValue(Integer.MAX_VALUE);到此,關于“lucene4.7排序方法怎么使用”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





