溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么實現縮小版雪花算法與多線程并發測試”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么實現縮小版雪花算法與多線程并發測試”吧!
我們設計數據表的時候,一般都會有ID字段,ID的生成方法有多種,比如數據庫自增,UUID,雪花算法等。
考慮到以后數據的增長,分庫分表,分布式等要求,我們選擇雪花算法來生成ID。
開發Web系統需要后端跟前端交互,前端JavaScript支持的最大整型是53位,超過53位會丟失精度,原版的雪花算法會超過53位,我們使用縮小版的雪花算法,把位數減小到53位。
原版Snowflake算法的極限是每毫秒的每一個節點生成4059個id值,也就是說每毫秒的極限是生成023*4059=4 152 357個id值 ,縮小后極限是每秒生成15*131071=1 966 065個分布式id,夠我們在開發里面的日常使用了。
package cn.gintone.asso.util;
/**
* @description:縮小版的雪花算法
* @author:Elon He
* @create:2020-10-06
*/
public class SnowflakeMini {
/**
* 開始時間截 (1970-01-01)
*/
private final static long twepoch = 0L;
/**
* 機器id,范圍是1到15
*/
private final static long workerId =1L;
/**
* 機器id所占的位數,占4位
*/
private final static long workerIdBits = 4L;
/**
* 支持的最大機器id,結果是15
*/
private final static long maxWorkerId = ~(-1L << workerIdBits);
/**
* 生成序列占的位數
*/
private final static long sequenceBits = 15L;
/**
* 機器ID向左移15位
*/
private final static long workerIdShift = sequenceBits;
/**
* 生成序列的掩碼,這里為最大是32767 (1111111111111=32767)
*/
private final static long sequenceMask = ~(-1L << sequenceBits);
/**
* 時間截向左移19位(4+15)
*/
private final static long timestampLeftShift = 19L;
/**
* 秒內序列(0~32767)
*/
private static long sequence = 0L;
/**
* 上次生成ID的時間截
*/
private static long lastTimestamp = -1L;
/**
* 獲得下一個ID (該方法是線程安全的)
*
* @return SnowflakeId
*/
public static synchronized long nextId() {
//返回以秒為單位的當前時間
long timestamp = timeGen();
//如果當前時間小于上一次ID生成的時間戳,說明系統時鐘回退過這個時候應當拋出異常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//藍色代碼注釋結束
//紅色代碼注釋開始
//如果是同一時間生成的,則進行秒內序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//秒內序列溢出
if (sequence == 0) {
//阻塞到下一個秒,獲得新的秒值
timestamp = tilNextMillis(lastTimestamp);
}
//時間戳改變,秒內序列重置
}
//紅色代碼注釋結束
//綠色代碼注釋開始
else {
sequence = 0L;
}
//綠色代碼注釋結束
//上次生成ID的時間截
lastTimestamp = timestamp;
//黃色代碼注釋開始
//移位并通過或運算拼到一起組成53 位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (workerId << workerIdShift)
| sequence;
//黃色代碼注釋結束
}
/**
* 阻塞到下一個秒,直到獲得新的時間戳
*
* @param lastTimestamp 上次生成ID的時間截
* @return 當前時間戳
*/
protected static long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以秒為單位的當前時間
*
* @return 當前時間(秒)
*/
protected static long timeGen() {
return System.currentTimeMillis()/1000L;
}
}創建兩個線程,同時測試ID獲取。
測試線程類A
package cn.gintone.asso;
import cn.gintone.asso.util.SnowflakeMini;
/**
* @description:線程A
* @author:Elon He
* @create:2020-10-06
*/
public class ThreadA extends Thread{
@Override
public void run() {
super.run();
for (int i = 0; i < 10; i++) {
long id = SnowflakeMini.nextId();
System.out.println("A:"+id);
}
}
}測試線程類B
package cn.gintone.asso;
import cn.gintone.asso.util.SnowflakeMini;
/**
* @description:線程B
* @author:Elon He
* @create:2020-10-06
*/
public class ThreadB extends Thread{
@Override
public void run() {
super.run();
for (int i = 0; i < 10; i++) {
long id = SnowflakeMini.nextId();
System.out.println("B:"+id);
}
}
}測試類(注釋掉的代碼是修改成靜態方法前的測試方法)
package cn.gintone.asso;
/**
* @description:雪花算法測試類
* @author:Elon He
* @create:2020-10-06
*/
public class TestSnowflake {
public static void main(String[] args) {
//不同線程使用同一個對象,不重復
// SnowflakeMini idWorker = new SnowflakeMini(0);
// ThreadA t1 = new ThreadA(idWorker);
// ThreadB t2 = new ThreadB(idWorker);
// t1.start();
// t2.start();
//不同線程使用不同對象,會重復
// SnowflakeMini idWorker1 = new SnowflakeMini(0);
// SnowflakeMini idWorker2 = new SnowflakeMini(0);
// ThreadA t1 = new ThreadA(idWorker1);
// ThreadB t2 = new ThreadB(idWorker2);
// t1.start();
// t2.start();
//nextId修改成靜態方法后測試,不重復
ThreadA t1 = new ThreadA();
ThreadB t2 = new ThreadB();
t1.start();
t2.start();
}
}測試結果
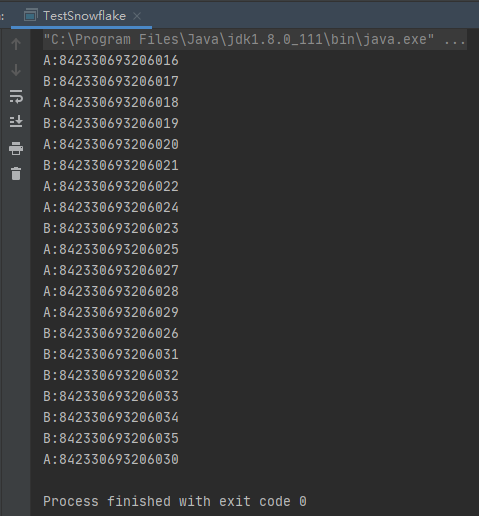
感謝各位的閱讀,以上就是“怎么實現縮小版雪花算法與多線程并發測試”的內容了,經過本文的學習后,相信大家對怎么實現縮小版雪花算法與多線程并發測試這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





