溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL MVCC更新數據時讀到的值是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
如果是可重復讀隔離級別,事務T啟動的時候會創建一個視圖read-view,之后事務T執行期間,即使有其他事務修改了數據,事務T看到的仍然跟在啟動時看到的一樣。也就是說,一個在可重復讀隔離級別下執行的事務,好像與世無爭,不受外界影響。
但是分享行鎖的時候又提到,一個事務要更新一行,如果剛好有另外一個事務擁有這一行的行鎖,它又不能這么超然了,會被鎖住,進入等待狀態。問題是,既然進入了等待狀態,那么等到這個事務自己獲取到行鎖要更新數據的時候,它讀到的值又是什么呢?
我給你舉一個例子吧。下面是一個只有兩行的表的初始化語句。
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `k` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(id, k) values(1,1),(2,2);

這里,我們需要注意的是事務的啟動時機。
begin/start transaction命令并不是一個事務的起點,在執行到它們之后的第一個操作InnoDB表的語句(第一個快照讀語句),事務才真正啟動。如果你想要馬上啟動一個事務,可以使用start transaction with consistent snapshot這個命令。還需要注意的是,我們的例子中如果沒有特別說明,都是默認autocommit=1。
在這個例子中,事務C沒有顯式地使用begin/commit,表示這個update語句本身就是一個事務,語句完成的時候會自動提交。事務B在更新了行之后查詢; 事務A在一個只讀事務中查詢,并且時間順序上是在事務B的查詢之后。
這時,如果我告訴你事務B查到的k的值是3,而事務A查到的k的值是1,你是不是感覺有點暈呢?
所以,今天這篇文章,我其實就是想和你說明白這個問題,希望借由把這個疑惑解開的過程,能夠幫助你對InnoDB的事務和鎖有更進一步的理解。在MySQL里,有兩個視圖的概念:
一個是view。它是一個用查詢語句定義的虛擬表,在調用的時候執行查詢語句并生成結果。創建視圖的語法是create view … ,而它的查詢方法與表一樣。
另一個是InnoDB在實現MVCC時用到的一致性讀視圖,即consistent read view,用于支持RC(Read Committed,讀提交)和RR(Repeatable Read,可重復讀)隔離級別的實現。
它沒有物理結構,作用是事務執行期間用來定義我能看到什么數據。我跟你解釋過一遍 MVCC的實現邏輯。今天為了說明查詢和更新的區別,我換一個方式來說明,把read view拆開。你可以結合這兩篇文章的說明來更深一步地理解MVCC。
在可重復讀隔離級別下,事務在啟動的時候就“拍了個快照”。注意,這個快照是基于整庫的。
這時,你會說這看上去不太現實啊。如果一個庫有100G,那么我啟動一個事務,MySQL就要拷貝100G的數據出來,這個過程得多慢啊。可是,我平時的事務執行起來很快啊。
實際上,我們并不需要拷貝出這100G的數據。我們先來看看這個快照是怎么實現的。
InnoDB里面每個事務有一個唯一的事務ID,叫作transaction id。它是在事務開始的時候向InnoDB的事務系統申請的,是按申請順序嚴格遞增的。
而每行數據也都是有多個版本的。每次事務更新數據的時候,都會生成一個新的數據版本,并且把transaction id賦值給這個數據版本的事務ID,記為row trx_id。同時,舊的數據版本要保留,并且在新的數據版本中,能夠有信息可以直接拿到它。也就是說,數據表中的一行記錄,其實可能有多個版本(row),每個版本有自己的row trx_id。下圖就是一個記錄被多個事務連續更新后的狀態。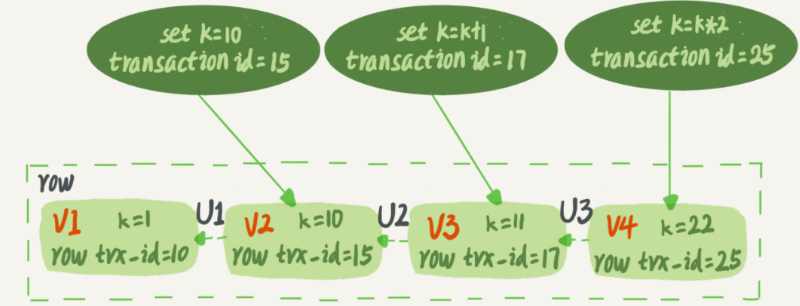
圖中虛線框里是同一行數據的4個版本,當前最新版本是V4,k的值是22,它是被transaction id為25的事務更新的,因此它的row trx_id也是25。
你可能會問,前面的文章不是說,語句更新會生成undo log(回滾日志)嗎?那么,undo log在哪呢?
實際上,圖2中的三個虛線箭頭,就是undo log;而V1、V2、V3并不是物理上真實存在的,而是每次需要的時候根據當前版本和undo log計算出來的。比如,需要V2的時候,就是通過V4依次執行U3、U2算出來。
明白了多版本和row trx_id的概念后,我們再來想一下,InnoDB是怎么定義那個“100G”的快照的。
按照可重復讀的定義,一個事務啟動的時候,能夠看到所有已經提交的事務結果。但是之后,這個事務執行期間,其他事務的更新對它不可見。
因此,一個事務只需要在啟動的時候聲明說,“以我啟動的時刻為準,如果一個數據版本是在我啟動之前生成的,就認;如果是我啟動以后才生成的,我就不認,我必須要找到它的上一個版本”。
當然,如果“上一個版本”也不可見,那就得繼續往前找。還有,如果是這個事務自己更新的數據,它自己還是要認的。
在實現上, InnoDB為每個事務構造了一個數組,用來保存這個事務啟動瞬間,當前正在“活躍”的所有事務ID。“活躍”指的就是,啟動了但還沒提交。
數組里面事務ID的最小值記為低水位,當前系統里面已經創建過的事務ID的最大值加1記為高水位。
這個視圖數組和高水位,就組成了當前事務的一致性視圖(read-view)。而數據版本的可見性規則,就是基于數據的row trx_id和這個一致性視圖的對比結果得到的。這個視圖數組把所有的row trx_id 分成了幾種不同的情況。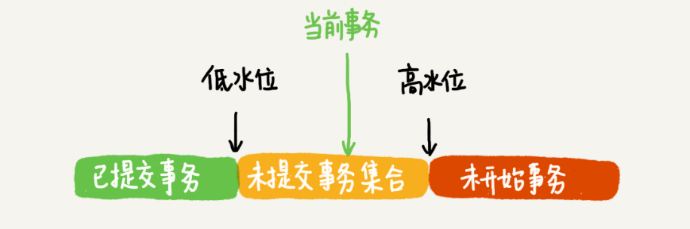
這樣,對于當前事務的啟動瞬間來說,一個數據版本的row trx_id,有以下幾種可能:
1、如果落在
綠色部分,表示這個版本是已提交的事務或者是當前事務自己生成的,這個數據是可見的;
2、如果落在紅色部分,表示這個版本是由將來啟動的事務生成的,是肯定不可見的;
3、如果落在黃色部分,那就包括兩種情況3.1 若 row trx_id在數組中,表示這個版本是由還沒提交的事務生成的,不可見;
3.2 若 row trx_id不在數組中,表示這個版本是已經提交了的事務生成的,可見。
比如,對于圖2中的數據來說,如果有一個事務,它的低水位是18,那么當它訪問這一行數據時,就會從V4通過U3計算出V3,所以在它看來,這一行的值是11。
你看,有了這個聲明后,系統里面隨后發生的更新,是不是就跟這個事務看到的內容無關了呢?因為之后的更新,生成的版本一定屬于上面的2或者3(a)的情況,而對它來說,這些新的數據版本是不存在的,所以這個事務的快照,就是靜態的了。
所以你現在知道了,InnoDB利用了所有數據都有多個版本的這個特性,實現了“秒級創建快照”的能力。
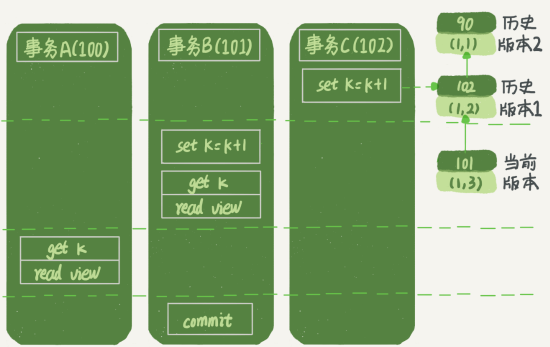
接下來,我們繼續看一下圖1中的三個事務,分析下事務A的語句返回的結果,為什么是k=1。這里,我們不妨做如下假設:
事務A開始前,系統里面只有一個活躍事務ID是99;
事務A、B、C的版本號分別是100、101、102,且當前系統里只有這四個事務;
三個事務開始前,(1,1)這一行數據的row trx_id是90。
這樣,事務A的視圖數組就是[99,100], 事務B的視圖數組是[99,100,101], 事務C的視圖數組是[99,100,101,102]。
為了簡化分析,我先把其他干擾語句去掉,只畫出跟事務A查詢邏輯有關的操作: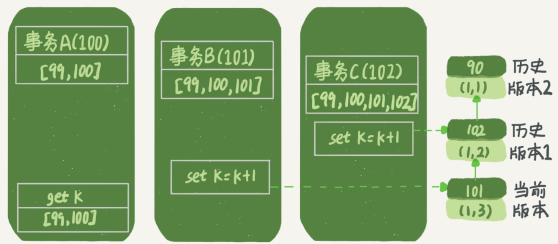
從圖中可以看到,第一個有效更新是事務C,把數據從(1,1)改成了(1,2)。這時候,這個數據的最新版本的row trx_id是102,而90這個版本已經成為了歷史版本。
第二個有效更新是事務B,把數據從(1,2)改成了(1,3)。這時候,這個數據的最新版本(即row trx_id)是101,而102又成為了歷史版本。
你可能注意到了,在事務A查詢的時候,其實事務B還沒有提交,但是它生成的(1,3)這個版本已經變成當前版本了。但這個版本對事務A必須是不可見的,否則就變成臟讀了。
好,現在事務A要來讀數據了,它的視圖數組是[99,100]。當然了,讀數據都是從當前版本讀起的。所以,事務A查詢語句的讀數據流程是這樣的:
找到(1,3)的時候,判斷出row trx_id=101,比高水位大,處于紅色區域,不可見;
接著,找到上一個歷史版本,一看row trx_id=102,比高水位大,處于紅色區域,不可見;
再往前找,終于找到了(1,1),它的row trx_id=90,比低水位小,處于綠色區域,可見。
這樣執行下來,雖然期間這一行數據被修改過,但是事務A不論在什么時候查詢,看到這行數據的結果都是一致的,所以我們稱之為一致性讀。
這個判斷規則是從代碼邏輯直接轉譯過來的,但是正如你所見,用于人肉分析可見性很麻煩。所以,我來給你翻譯一下。一個數據版本,對于一個事務視圖來說,除了自己的更新總是可見以外,有三種情況:
版本未提交,不可見;
版本已提交,但是是在視圖創建后提交的,不可見;
版本已提交,而且是在視圖創建前提交的,可見。
現在,我們用這個規則來判斷圖4中的查詢結果,事務A的查詢語句的視圖數組是在事務A啟動的時候生成的,這時候:
(1,3)還沒提交,屬于情況1,不可見;
(1,2)雖然提交了,但是是在視圖數組創建之后提交的,屬于情況2,不可見;
(1,1)是在視圖數組創建之前提交的,可見。
你看,去掉數字對比后,只用時間先后順序來判斷,分析起來是不是輕松多了。所以,后面我們就都用這個規則來分析。
細心的同學可能有疑問了:事務B的update語句,如果按照一致性讀,好像結果不對哦?你看下圖中,事務B的視圖數組是先生成的,之后事務C才提交,不是應該看不見(1,2)嗎,怎么能算出(1,3)來?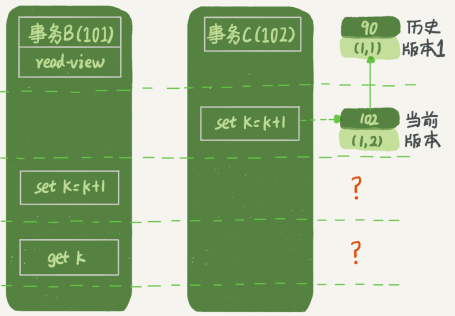
是的,如果事務B在更新之前查詢一次數據,這個查詢返回的k的值確實是1。但是,當它要去更新數據的時候,就不能再在歷史版本上更新了,否則事務C的更新就丟失了。因此,事務B此時的set k=k+1是在(1,2)的基礎上進行的操作。
所以,這里就用到了這樣一條規則:更新數據都是先讀后寫的,而這個讀,只能讀當前的值,稱為“當前讀”(current read)。
因此,在更新的時候,當前讀拿到的數據是(1,2),更新后生成了新版本的數據(1,3),這個新版本的row trx_id是101。所以,在執行事務B查詢語句的時候,一看自己的版本號是101,最新數據的版本號也是101,是自己的更新,可以直接使用,所以查詢得到的k的值是3。
這里我們提到了一個概念,叫作當前讀。其實,除了update語句外,select語句如果加鎖,也是當前讀。所以,如果把事務A的查詢語句select * from t where id=1修改一下,加上lock in share mode 或 for update,也都可以讀到版本號是101的數據,返回的k的值是3。下面這兩個select語句,就是分別加了讀鎖(S鎖,共享鎖)和寫鎖(X鎖,排他鎖)。
mysql> select k from t where id=1 lock in share mode;mysql> select k from t where id=1 for update;
假設事務C不是馬上提交的,而是變成了下面的事務C’,會怎么樣呢?

事務C’的不同是,更新后并沒有馬上提交,在它提交前,事務B的更新語句先發起了。前面說過了,雖然事務C’還沒提交,但是(1,2)這個版本也已經生成了,并且是當前的最新版本。那么,事務B的更新語句會怎么處理呢?
這時候牢記(在InnoDB事務中,行鎖是在需要的時候才加上的,但并不是不需要了就立刻釋放,而是要等到事務結束時才釋放。這個就是兩階段鎖協議)。事務C’沒提交,也就是說(1,2)這個版本上的寫鎖還沒釋放。而事務B是當前讀,必須要讀最新版本,而且必須加鎖,因此就被鎖住了,必須等到事務C’釋放這個鎖,才能繼續它的當前讀。
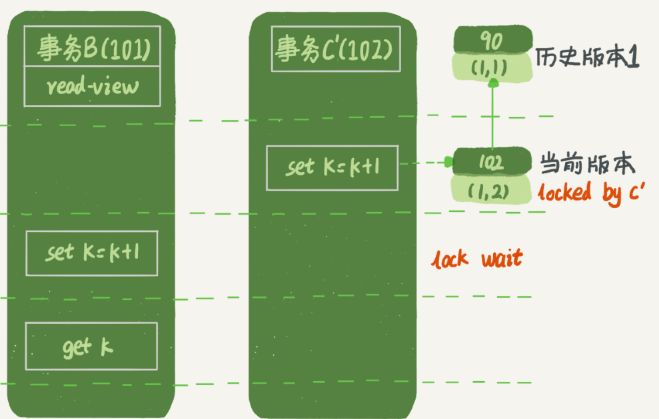
到這里,我們把一致性讀、當前讀和行鎖就串起來了。現在,我們再回到文章開頭的問題:事務的可重復讀的能力是怎么實現的?
可重復讀的核心就是一致性讀(consistent read);而事務更新數據的時候,只能用當前讀。如果當前的記錄的行鎖被其他事務占用的話,就需要進入鎖等待。
而讀提交的邏輯和可重復讀的邏輯類似,它們最主要的區別是:
在可重復讀隔離級別下,只需要在事務開始的時候創建一致性視圖,之后事務里的其他查詢都共用這個一致性視圖;
在讀提交隔離級別下,每一個語句執行前都會重新算出一個新的視圖。
那么,我們再看一下,在讀提交隔離級別下,事務A和事務B的查詢語句查到的k,分別應該是多少呢?
這里需要說明一下,start transaction with consistent snapshot;的意思是從這個語句開始,創建一個持續整個事務的一致性快照。所以,在讀提交隔離級別下,這個用法就沒意義了,等效于普通的start transaction。
下面是讀提交時的狀態圖,可以看到這兩個查詢語句的創建視圖數組的時機發生了變化,就是圖中的read view框。(注意:這里,我們用的還是事務C的邏輯直接提交,而不是事務C’)
這時,事務A的查詢語句的視圖數組是在執行這個語句的時候創建的,時序上(1,2)、(1,3)的生成時間都在創建這個視圖數組的時刻之前。但是,在這個時刻:
(1,3)還沒提交,屬于情況1,不可見;
(1,2)提交了,屬于情況3,可見。
所以,這時候事務A查詢語句返回的是k=2。顯然地,事務B查詢結果k=3。
用下面的表結構和初始化語句作為試驗環境,事務隔離級別是可重復讀。現在,我要把所有“字段c和id值相等的行”的c值清零,但是卻發現了一個“詭異”的、改不掉的情況。請你構造出這種情況,并說明其原理
mysql> CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);
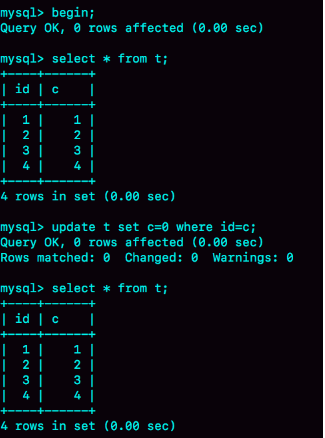
答案:利用update的準確性


“MySQL MVCC更新數據時讀到的值是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





