溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Vertica的C-Store知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Vertica的C-Store知識點有哪些”吧!
背景知識
Vertica 是 C-Store 的商業化產品,C-Store 在 2006 年發布了0.2版本之后就沒在開發了。C-Store 的一部分人與 2006 年開啟 Vertica 項目,在 2011 年被 Hewlett-Packard(HP)收購。Vertica 沒有使用 C-Store 原型系統的代碼,僅借鑒了思想。
截止2012年,有超過 500 個生產環境部署了 Vertica,其中有至少 3 個項目數據量達到 PB 級。和 C-Store 一樣,Vertica 提供經典的關系型接口,Vertica 證明了一個系統既可以支持完整的 ACID 事務,也可以支持 PB 級數據高效的查詢。這個說法我感覺已經超過現在的 NewSQL 分布式關系型數據庫了。
業務場景
事務型:每秒有很多筆請求(上千),每個請求只處理小部分數據。大部分事務是插入一行數據或者更新一行數據。
分析型:每秒只有少數個請求(幾十),但是每個請求會遍歷表的一大部分數據。例如按時間和空間聚合銷售數據。
現在商業公司中一張表中的數據已經達到了百萬或者十億級,事務型和分析型場景的區別越來越明顯,針對分析型場景單獨做優化可以比 one-size-fits-all 的系統性能提升幾個數量級。
Projection 和物化視圖的區別
projection 可以看做是帶限制的物化視圖,但是和標準的物化視圖不一樣,因為projection 僅僅是數據的物理結構,而不是輔助索引。傳統的物化視圖通常還包含聚合、連接和其他的查詢結果。但是 projection 不包含。并且在分布式系統中維護物化視圖的代價很高,尤其是再加上對聚合和過濾的支持是不現實的。
總而言之,物化視圖比 projection 雜,實現復雜,在分布式系統中需要被拋棄掉了。
join index
C-Store 中提過的 join index 被廢棄掉了,維護這個索引代價太大,而且需要多存很多 id。那如何構建一個完整的行呢? Vertica 維護了一個包含所有列的 super projection,也就是一張完整的表。
存儲模型
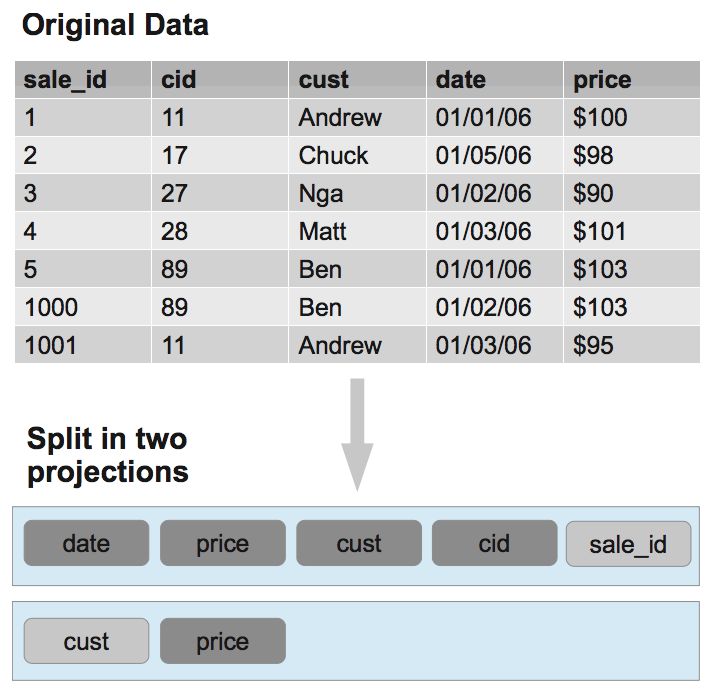
對于每個 projection 來說,哪些數據存儲到一個 segment 中,放在哪個節點上是分段策略決定的。數據只在每個 segment 內部排序。第一個 projection 按 hash(sale_id) 分段,按 date 排序。第二個 projection 按 hash(cust) 分段,按 cust 排序。
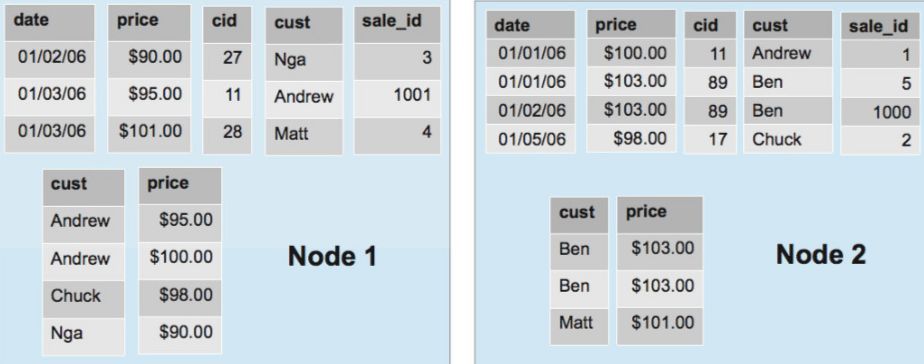
節點間分段:Segmentation
這里說的分段是節點間的,用來決定哪些數據分配在哪些節點上。分段方式是在定義 projection 時指定的。分段的依據是一個整數表達式,給一行 projection 數據,就計算出一個整數,根據這個整數的大小分配到不同節點上去。作者在這給了一個分段的公式。
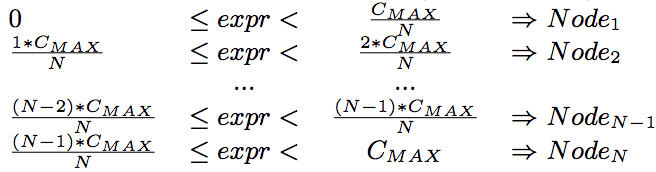
其實就是一致性hash環,以后再介紹。
節點內部數據分區:Partitioning
分區是指每個數據分區用一個文件存儲,物理上分離開了。
分區的第一個好處是批量刪除,通常數據按照年月分成多個文件,這樣在刪除一段時間數據時就可以簡單的刪除一個文件。如果數據沒有提前分區,就需要逐個遍歷記錄。
批量刪除只有在一個表的多個 projection 分區方式一樣時才能實現,不然只能刪掉部分 projection 的分區,因此 Vertica 的分區是指定在 table 層級的。
分區的另一個好處是加速查詢,每個分區有一個摘要信息,可以快速跳過一些分區。
他這個對 partition 的解釋我覺得很別扭,一致性hash里 partition 是用來控制數據存儲在哪個節點上的。
三個組件
和 C-Store 一樣,Vertica 也包括一個 Read Optimized Store(ROS),一個 Write Optimized Store(WOS)。一般來說,每個文件存一列,也可以存多列,這樣類似混合架構。
數據在 WOS 里沒有壓縮編碼,因為很小,而且在內存里采用行式或列式沒有什么區別,Vertica 的 WOS 從行式改成了列式,又改成了行式,主要是出于軟件工程考慮,性能上沒啥區別。
Tuple mover:兩個主要功能:(1)Moveout,將 WOS 中的數據移動到 ROS 中,即 flush (2)Mergeout,將 ROS 中的小文件合并成大文件。其實就是 LSM 的概念,換了個叫法。
Vertica 有個功能,當 flush 的時候,允許新來的寫入直接寫到 ROS 中,這個我不理解,這怎么保序?雖然作者最后又提了一遍這個功能,說初始化導入數據時寫到 WOS 里是浪費內存,但是內存是用來排序的,否則 ROS 豈不是亂了?
容錯
為了保證每個 projection 都可以恢復,每個 projection 都至少要有一個包含相同列和相同分段方式的 buddy projection。
因為每個 projection 可以有自己的排序鍵,這里恢復就有兩種情況了:
(1)排序鍵一樣,可以直接拷貝文件,副本恢復也是這么做的。
(2)排序鍵不一樣,需要先查詢再寫入,沒啥更好的方法。
另外,Vertica 可以容忍 K 個錯,因此,數據庫在設計 projection 時需要保證每個 segment 需要至少在 K+1 個節點都有備份。 這句話的意思應該是直接生成 K+1 個 projection,而不是純粹復制 segment。
局限
Vertica 解決了 C-Store 的一個大麻煩: join index,但是還是有刺可以挑的:
沒有講如何生成 projection,順序如何選擇,要配多少個副本,不同的 projection 按照不同順序存儲,會不會拖慢寫入速度沒有介紹。
用戶一般不會設置最大空間占用,只會設置副本數,沒有用戶給系統一個最大可用的空間限制,然后讓數據庫自己把這些空間都吃滿,頂多給一個原始數據占空間多少和允許數據庫占的空間的比例,根據一個預設的可用空間來選擇副本數的數據庫都是耍流氓。
負載均衡沒有提如何做。
感謝各位的閱讀,以上就是“Vertica的C-Store知識點有哪些”的內容了,經過本文的學習后,相信大家對Vertica的C-Store知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





