溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Flink中ProcessFunction類如何使用,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
深入了解ProcessFunction的狀態操作(Flink-1.10);
ProcessFunction;
KeyedProcessFunction類;
ProcessAllWindowFunction(窗口處理);
CoProcessFunction(雙流處理);
如下圖,在常規的業務開發中,SQL、Table API、DataStream API比較常用,處于Low-level的Porcession相對用得較少,從本章開始,我們一起通過實戰來熟悉處理函數(Process Function),看看這一系列的低級算子可以帶給我們哪些能力? 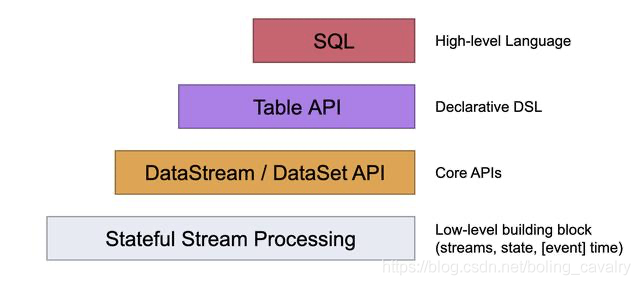
處理函數有很多種,最基礎的應該ProcessFunction類,來看看它的類圖,可見有RichFunction的特性open、close,然后自己有兩個重要的方法processElement和onTimer: 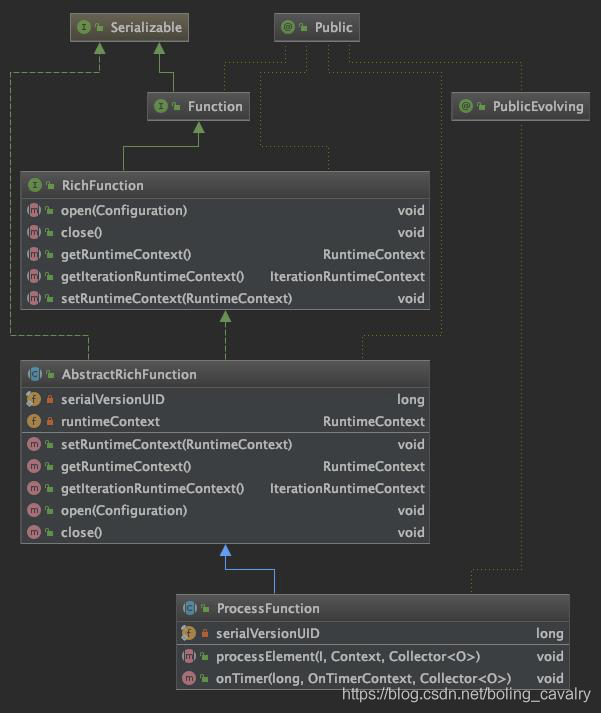 常用特性如下所示:
常用特性如下所示:
處理單個元素;
訪問時間戳;
旁路輸出;
接下來寫兩個應用體驗上述功能;
開發環境操作系統:MacBook Pro 13寸, macOS Catalina 10.15.3
開發工具:IDEA ULTIMATE 2018.3
JDK:1.8.0_211
Maven:3.6.0
Flink:1.9.2
如果您不想寫代碼,整個系列的源碼可在GitHub下載到,地址和鏈接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名稱 | 鏈接 | 備注 |
|---|---|---|
| 項目主頁 | https://github.com/zq2599/blog_demos | 該項目在GitHub上的主頁 |
| git倉庫地址(https) | https://github.com/zq2599/blog_demos.git | 該項目源碼的倉庫地址,https協議 |
| git倉庫地址(ssh) | git@github.com:zq2599/blog_demos.git | 該項目源碼的倉庫地址,ssh協議 |
這個git項目中有多個文件夾,本章的應用在<font color="blue">flinkstudy</font>文件夾下,如下圖紅框所示: 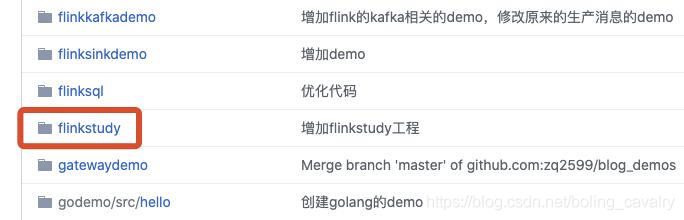
執行以下命令創建一個flink-1.9.2的應用工程:
mvn \ archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.9.2
按提示輸入groupId:com.bolingcavalry,architectid:flinkdemo
第一個demo用來體驗以下兩個特性:
處理單個元素;
訪問時間戳;
創建Simple.java,內容如下:
package com.bolingcavalry.processfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
public class Simple {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 并行度為1
env.setParallelism(1);
// 設置數據源,一共三個元素
DataStream<Tuple2<String,Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
for(int i=1; i<4; i++) {
String name = "name" + i;
Integer value = i;
long timeStamp = System.currentTimeMillis();
// 將將數據和時間戳打印出來,用來驗證數據
System.out.println(String.format("source,%s, %d, %d\n",
name,
value,
timeStamp));
// 發射一個元素,并且戴上了時間戳
ctx.collectWithTimestamp(new Tuple2<String, Integer>(name, value), timeStamp);
// 為了讓每個元素的時間戳不一樣,每發射一次就延時10毫秒
Thread.sleep(10);
}
}
@Override
public void cancel() {
}
});
// 過濾值為奇數的元素
SingleOutputStreamOperator<String> mainDataStream = dataStream
.process(new ProcessFunction<Tuple2<String, Integer>, String>() {
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<String> out) throws Exception {
// f1字段為奇數的元素不會進入下一個算子
if(0 == value.f1 % 2) {
out.collect(String.format("processElement,%s, %d, %d\n",
value.f0,
value.f1,
ctx.timestamp()));
}
}
});
// 打印結果,證明每個元素的timestamp確實可以在ProcessFunction中取得
mainDataStream.print();
env.execute("processfunction demo : simple");
}
}這里對上述代碼做個介紹:
創建一個數據源,每個10毫秒發出一個元素,一共三個,類型是Tuple2,f0是個字符串,f1是整形,每個元素都帶時間戳;
數據源發出元素時,提前把元素的f0、f1、時間戳打印出來,和后面的數據核對是否一致;
在后面的處理中,創建了ProcessFunction的匿名子類,里面可以處理上游發來的每個元素,并且還能取得每個元素的時間戳(這個能力很重要),然后將f1字段為奇數的元素過濾掉;
最后將ProcessFunction處理過的數據打印出來,驗證處理結果是否符合預期;
直接執行Simple類,結果如下,可見過濾和提取時間戳都成功了: 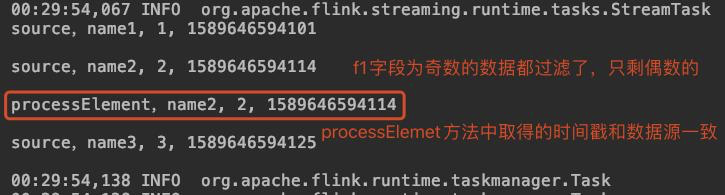
第二個demo是實現旁路輸出(Side Outputs),對于一個DataStream來說,可以通過旁路輸出將數據輸出到其他算子中去,而不影響原有的算子的處理,下面來演示旁路輸出:
創建SideOutput類:
package com.bolingcavalry.processfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.ArrayList;
import java.util.List;
public class SideOutput {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度為1
env.setParallelism(1);
// 定義OutputTag
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
// 創建一個List,里面有兩個Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 2));
list.add(new Tuple2("ccc", 3));
//通過List創建DataStream
DataStream<Tuple2<String, Integer>> fromCollectionDataStream = env.fromCollection(list);
//所有元素都進入mainDataStream,f1字段為奇數的元素進入SideOutput
SingleOutputStreamOperator<String> mainDataStream = fromCollectionDataStream
.process(new ProcessFunction<Tuple2<String, Integer>, String>() {
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<String> out) throws Exception {
//進入主流程的下一個算子
out.collect("main, name : " + value.f0 + ", value : " + value.f1);
//f1字段為奇數的元素進入SideOutput
if(1 == value.f1 % 2) {
ctx.output(outputTag, "side, name : " + value.f0 + ", value : " + value.f1);
}
}
});
// 禁止chanin,這樣可以在頁面上看清楚原始的DAG
mainDataStream.disableChaining();
// 取得旁路數據
DataStream<String> sideDataStream = mainDataStream.getSideOutput(outputTag);
mainDataStream.print();
sideDataStream.print();
env.execute("processfunction demo : sideoutput");
}
}這里對上述代碼做個介紹:
數據源是個集合,類型是Tuple2,f0字段是字符串,f1字段是整形;
ProcessFunction的匿名子類中,將每個元素的f0和f1拼接成字符串,發給主流程算子,再將f1字段為奇數的元素發到旁路輸出;
數據源發出元素時,提前把元素的f0、f1、時間戳打印出來,和后面的數據核對是否一致;
將主流程和旁路輸出的元素都打印出來,驗證處理結果是否符合預期;
執行SideOutput看結果,如下圖,main前綴的都是主流程算子,一共三條記錄,side前綴的是旁路輸出,只有f1字段為奇數的兩條記錄,符合預期: 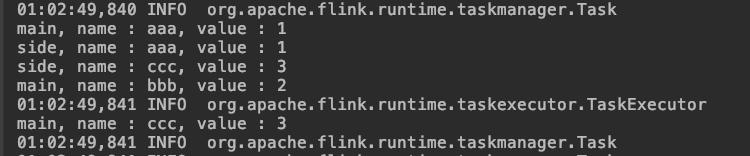 上面的操作都是在IDEA上執行的,還可以將flink單獨部署,再將上述工程構建成jar,提交到flink的jobmanager,可見DAG如下:
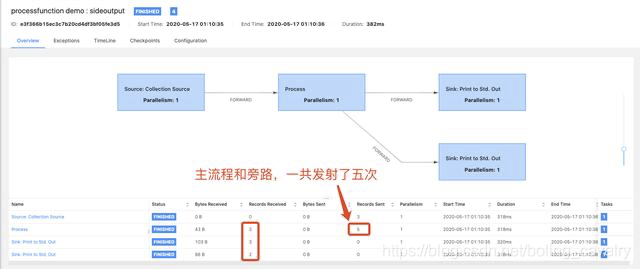
上面的操作都是在IDEA上執行的,還可以將flink單獨部署,再將上述工程構建成jar,提交到flink的jobmanager,可見DAG如下:
 至此,處理函數中最簡單的ProcessFunction類的學習
至此,處理函數中最簡單的ProcessFunction類的學習
關于Flink中ProcessFunction類如何使用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





