溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹未探索的TensorFlow庫都有哪些,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
TensorFlow是一個端到端的開源機器學習平臺,能夠執行一系列任務。它為初學者和研究人員提供了一個易用性,可以用于不同的應用,如,但不限于,計算機視覺,自然語言處理和強化學習。
在計算機視覺領域,我們大多數人都熟悉TensorFlow的核心以及TensorFlow Lite和JS。它們用于在移動設備和邊緣設備上運行模型,為后者在web上運行模型。然而,TensorFlow還提供了更多神秘的庫,我們將在文中對此進行解釋。
實時模型對于許多商業操作是必不可少的。MobileNet的推理速度使它成為了眾人矚目的焦點,即使這意味著要犧牲一點準確性。
優化TensorFlow模型首先想到的是將其轉換為TensorFlow lite服務。但是,這在桌面上不太好用,因為它是為ARM neon優化的。這篇問題對此進行了解釋(https://github.com/tensorflow/tensorflow/issues/35380),否則我們需要進一步優化模型。模型優化工具箱可以幫助我們完成這些任務。根據其主頁,它可以用于:
減少云和邊緣設備(如移動設備、物聯網)的延遲和推理成本。
將模型部署到邊緣設備,并限制處理、內存、功耗、網絡使用和模型存儲空間。
支持對現有硬件或新的專用加速器執行和優化。
它可以應用于已經訓練過的模型,也可以在訓練期間用于進一步優化解決方案。在編寫本文時,它提供了三種技術,以及其他一些正在進行的改進模型的技術。
第一種方法是權重剪枝。它的工作原理是刪除層之間的一些連接,從而減少所涉及的參數和操作的數量,從而優化模型。在訓練過程中消除了不必要的張量。這有助于縮小模型的大小,通過訓練后量化可以進一步減小模型的大小。
與只在訓練期間進行的修剪不同,量化可以在訓練和測試中進行。Tensorflow Lite模型也被量化為使用8位整數,而不是通常使用的32位浮點。這提高了性能和效率,因為整數運算比浮點運算快得多。
然而,這是有代價的。量化是一種有損技術。這意味著先前從-3e38到3e38表示的信息必須從-127表示到127。這回引入更多錯誤。為了解決這個問題,可以在訓練期間應用量化。
通過在訓練中應用量化,我們迫使模型學習它將導致的差異并相應地采取行動。量化誤差作為噪聲引入,優化器試圖將其最小化。用這種方法訓練的模型具有與浮點模型相當的精度。很有意思的是,我們可以比較一下用這種方法創建的Tensorflow-Lite模型與普通模型。
雖然最好在訓練期間應用量化,但有時這樣做是不可行的,因為我們可能有預訓練好的權重可供使用。
它將相似的權重組合起來,并用一個值替換它們。它可以想象成JPEG壓縮。此外,由于相似的權重被插值到相同的數目,它也是有損的。
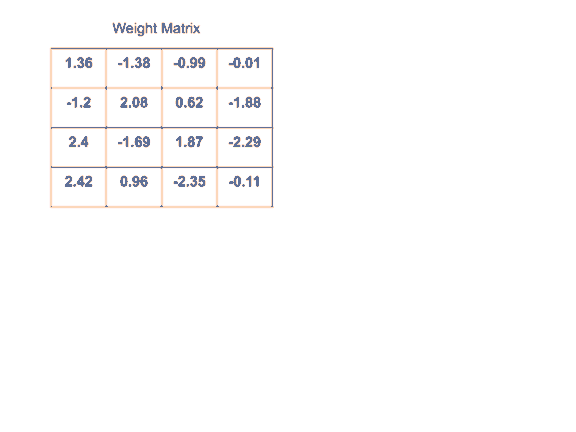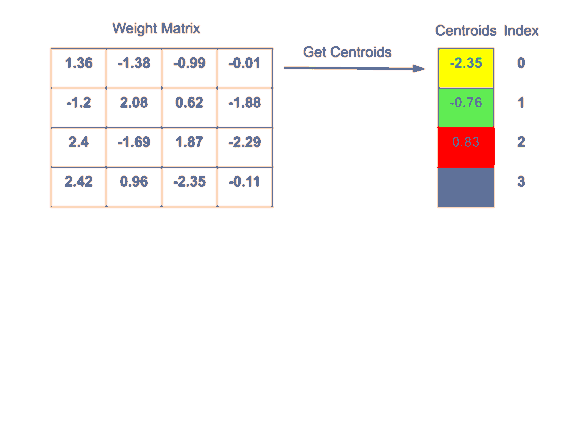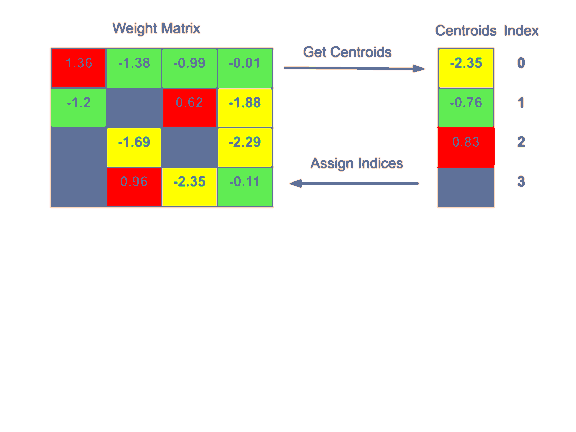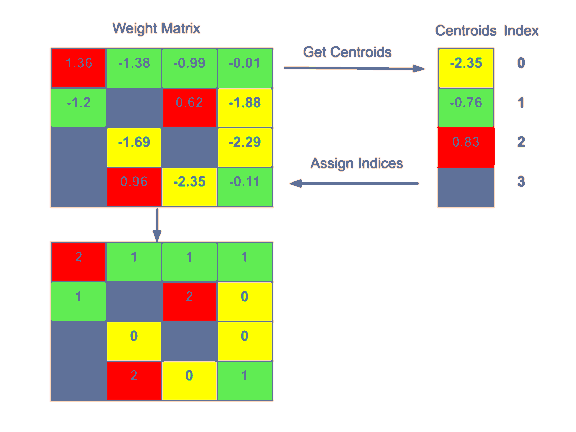
權重矩陣原本存儲浮點值。這些值被轉換成整數,整數代表簇號。我們再存儲包含簇的查找表以便查詢。這減少了所需的空間,因為整數需要更少的存儲空間。
如下面的示例所示,16個float-32值被指定給4個float-32質心,層權重被轉換為整數值。權重矩陣越大,節省的空間就越大。
TensorFlow graphics旨在將計算機視覺和計算機圖形學結合起來,解決復雜的三維任務。
計算機圖形工作流需要三維對象及其在場景中的絕對位置、對它們由燈光構成的材質的描述以及生成合成渲染的攝影機。另一方面,計算機視覺工作流將從圖像開始,并嘗試推導其參數。
這可以看作是一個自編碼器,視覺系統(編碼器)將嘗試查找參數,而圖形系統(解碼器)將基于這些參數生成圖像,并與原始圖像進行比較。此外,該系統不需要標記數據,也不需要以自我監督的方式訓練。一些用途是:
變換-可以對對象執行旋轉和平移等對象變換。這可以通過神經網絡學習來精確地找到物體的位置。它對于需要精確估計這些物體位置的機械手臂很有用。
建模攝像機-可以設置不同的攝像機內部參數來改變圖像的感知方式。例如,更改攝影機的焦距會更改對象的大小。
材料-可以使用具有不同類型光反射能力的不同類型的材料。因此,創建的場景可以精確地模擬對象在真實世界中的行為。
三維卷積和池(點云和網格)-它有三維卷積和池層,允許我們對三維數據進行語義分類和分割。
TensorBoard 3D-3D數據變得越來越普遍,可以用來解決從2D數據進行三維重建、點云分割、3D對象變形等問題。通過TensorBoard 3D,這些結果可以可視化,從而更好地了解模型。
進一步閱讀:https://blog.tensorflow.org/2019/05/introducing-tensorflow-graphics_9.html
這個庫也可以用于計算機視覺以外的其他領域。隨著移動設備和邊緣設備數量的增加,產生了大量的數據。
聯邦學習的目標是在分散數據上執行機器學習,即在設備本身上!這意味著不需要向服務器上傳大量(敏感)數據。它已經在谷歌鍵盤上使用。
通過隱私攻擊可以從經過訓練的ML模型中提取敏感信息。

左側是僅使用人名和模型重建的圖像。右邊的圖像是原始圖像。
同樣,像TensorFlow Federated一樣,這并不是計算機視覺所獨有的。最常用的技術是差分隱私。
差分隱私一種公開共享數據集信息的系統,通過描述數據集中組的模式,同時保留數據集中個人的信息。
假設敏感信息不會在數據集中完全重復,通過使用差分隱私模型,可以確保模型不會學習此類信息。
例如,假設有一個人與人之間聊天的數據集。現在,聊天中傳遞的敏感信息可以是密碼、銀行帳戶詳細信息等。因此,如果在這個數據集上創建了一個模型,則差分隱私將確保該模型無法學習這些細節,因為這些信息的數量很少。閱讀這篇關于差分隱私的文章,它還包含了執行它的代碼。
你們中的大多數人一定對這個庫有所了解,所以我對它的介紹將非常簡短。
TensorFlow Hub是一個在TensorFlow中發布、發現和重用部分機器學習模塊的平臺。把它稱為TensorFlow模型的GitHub是正確的。
開發人員可以共享他們預訓練過的模型,然后可以被其他人重用。通過重用,開發人員可以使用較小的數據集訓練模型,提高泛化能力,或者只是加快訓練速度。讓我們快速了解一下現有的幾種不同的計算機視覺模型。
圖像分類——從MobileNet到Inception 再到EfficientNet,有一百多個可用于此任務的模型。說出你想要的任何型號,很可能會在那里找到它。
對象檢測和分割-同樣,你需要的任何模型都可以在這里找到,特別是在COCO數據集上訓練的TensorFlow model-zoo對象檢測器的集合中。Deeplab架構在圖像分割領域占據主導地位。還有大量的TfLite和TensorFlow Js模型可用。
圖像樣式化-圖像樣式化的不同的主干,以及一個卡通感興趣。
**生成對抗網絡-**提供了像Big GAN和Compare GAN這樣的GAN模型,在ImageNet和Celeb數據集上進行訓練。還有一個無邊界的GAN,可以用來生成攝像機捕捉到的場景之外的區域。此外,他們中的大多數有一個Colab Notebook,所以實現他們不會太難。
關于未探索的TensorFlow庫都有哪些就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





