溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用TensorFlow進行訓練識別視頻圖像中物體,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
注意: windows用戶名不能出現中文!!!
安裝Python
注意: Windows平臺的TensorFlow僅支持3.5.X版本的Python 進入Python3.5.2下載頁,選擇 Files 中Windows平臺的Python安裝包,下載并安裝。 
安裝TensorFlow
進入TensorFlow on Windows下載頁,本教程使用最簡便的組合 CPU support only + Native pip。
打開cmd,輸入以下指令即進行TensorFlow的下載安裝,下載位置為python\Lib\site-packages\tensorflow:  打開 IDLE,輸入以下指令:
打開 IDLE,輸入以下指令:  如果出現如下結果則安裝成功:
如果出現如下結果則安裝成功:  若出現問題,請參考TensorFlow on Windows下載頁底端的常見問題。
若出現問題,請參考TensorFlow on Windows下載頁底端的常見問題。 
安裝Protoc
Protoc用于編譯相關程序運行文件,進入Protoc下載頁,下載類似下圖中帶win32的壓縮包。  解壓后將bin文件夾內的protoc.exe拷貝到c:\windows\system32目錄下(用于將protoc.exe所在的目錄配置到環境變量當中)。
解壓后將bin文件夾內的protoc.exe拷貝到c:\windows\system32目錄下(用于將protoc.exe所在的目錄配置到環境變量當中)。
安裝git
進入git官網下載Windows平臺的git,詳細安裝及配置注意事項可參考此文。 
安裝其余組件
在cmd內輸入如下指令下載并安裝相關API運行支持組件:  注意: Native pip會受電腦中另外Python應用的影響,博主因為之前做仿真安裝了Anaconda,導致下載的jupyter等相關組件安裝到了Anaconda內的site-packages文件夾,后期調用失敗。
注意: Native pip會受電腦中另外Python應用的影響,博主因為之前做仿真安裝了Anaconda,導致下載的jupyter等相關組件安裝到了Anaconda內的site-packages文件夾,后期調用失敗。
下載代碼并編譯
在cmd中輸入如下代碼:  從github下載谷歌tensorflow/models的代碼,一般默認下載到C盤。
從github下載谷歌tensorflow/models的代碼,一般默認下載到C盤。
同樣在cmd進入到models文件夾,編譯Object Detection API的代碼: 
運行notebook demo
繼續在models文件夾下運行如下命令:  瀏覽器自動開啟,顯示如下界面:
瀏覽器自動開啟,顯示如下界面:  進入object_detection文件夾中的object_detection_tutorial.ipynb:
進入object_detection文件夾中的object_detection_tutorial.ipynb:  點擊Cell內的Run All,等待三分鐘左右(博主電腦接近報廢),即可顯示如下結果:
點擊Cell內的Run All,等待三分鐘左右(博主電腦接近報廢),即可顯示如下結果: 
 修改文件路徑,即可檢測自己的圖片:
修改文件路徑,即可檢測自己的圖片: 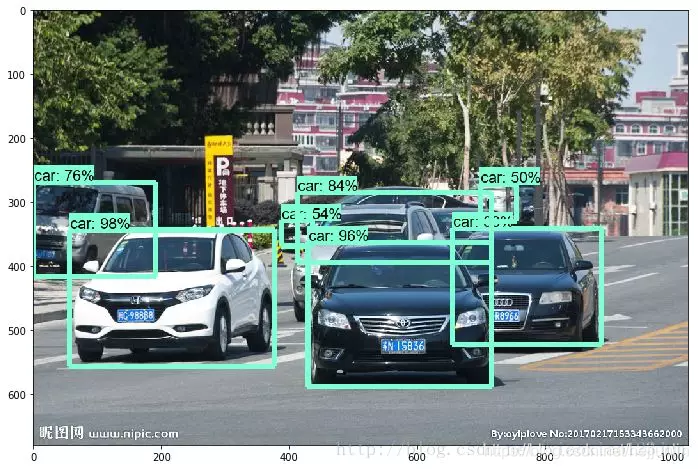
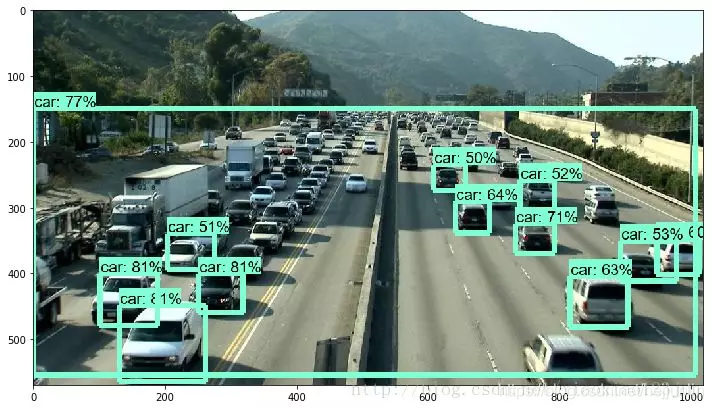 注意:要將圖片名稱設置的和代碼描述相符合,如image1.jpg
注意:要將圖片名稱設置的和代碼描述相符合,如image1.jpg  TensorFlow Object Detection API中提供了五種可直接調用的識別模型,默認的是最簡單的ssd + mobilenet模型。
TensorFlow Object Detection API中提供了五種可直接調用的識別模型,默認的是最簡單的ssd + mobilenet模型。 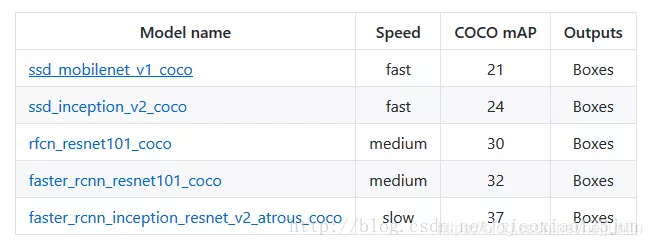 可直接將MODEL_NAME修改為如下值調用其他模型:
可直接將MODEL_NAME修改為如下值調用其他模型:
MODEL_NAME = 'ssd_inception_v2_coco_11_06_2017' MODEL_NAME = 'rfcn_resnet101_coco_11_06_2017' MODEL_NAME = 'faster_rcnn_resnet101_coco_11_06_2017' MODEL_NAME = 'faster_rcnn_inception_resnet_v2_atrous_coco_11_06_2017'
將模型換為faster_rcnn_inception_resnet,結果如下: 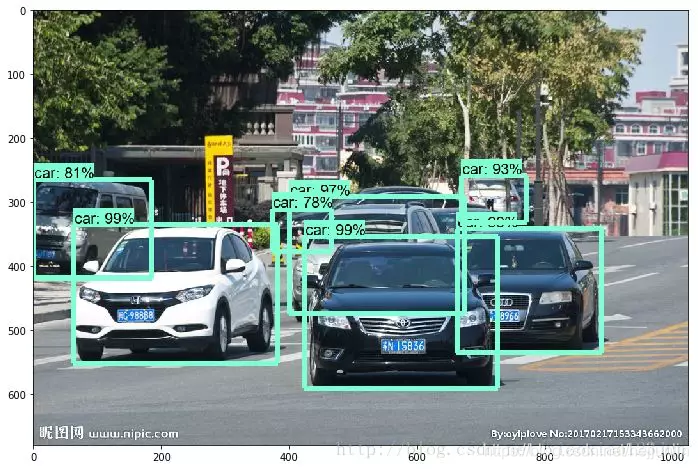
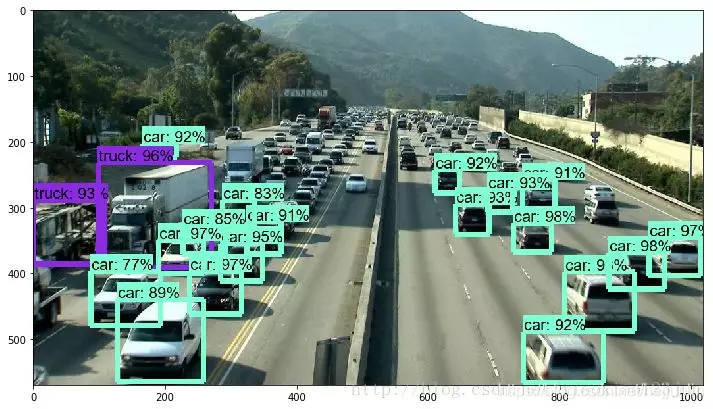 準確率確實獲得了極大提高,但是速度卻下降了,在博主的老爺機上需要五分鐘才能跑出結果。
準確率確實獲得了極大提高,但是速度卻下降了,在博主的老爺機上需要五分鐘才能跑出結果。
視頻物體識別
谷歌在github上公布了此項目的完整代碼,接下來我們將在現有代碼基礎上添加相應模塊實現對于視頻中物體的識別。
第一步:下載opencv的cv2包  在Python官網即可下載opencv相關庫,點擊此處直接進入。
在Python官網即可下載opencv相關庫,點擊此處直接進入。
博主安裝的版本如下:  下載完成后,在cmd中執行安裝命令
下載完成后,在cmd中執行安裝命令
pip install opencv_python-3.2.0.8-cp35-cp35m-win_amd64.whl
安裝完成后,進入IDLE輸入命令
import cv2
若未報錯,則opencv-python庫成功導入,環境搭配成功。
第二步:在原代碼中引入cv2包  第三步:添加視頻識別代碼 主要步驟如下: 1.使用 VideoFileClip 函數從視頻中抓取圖片。 2.用fl_image函數將原圖片替換為修改后的圖片,用于傳遞物體識別的每張抓取圖片。 3.所有修改的剪輯圖像被組合成為一個新的視頻。
第三步:添加視頻識別代碼 主要步驟如下: 1.使用 VideoFileClip 函數從視頻中抓取圖片。 2.用fl_image函數將原圖片替換為修改后的圖片,用于傳遞物體識別的每張抓取圖片。 3.所有修改的剪輯圖像被組合成為一個新的視頻。
在原版代碼基礎上,在最后面依次添加如下代碼(可從完整代碼 處復制,但需要作出一些改變,當然也可以直接從下文復制修改后的代碼): 
# Import everything needed to edit/save/watch video clips import imageio imageio.plugins.ffmpeg.download() from moviepy.editor import VideoFileClip from IPython.display import HTML
此處會下載一個剪輯必備的程序ffmpeg.win32.exe,內網下載過程中容易斷線,可以使用下載工具下載完然后放入如下路徑:
C:\Users\ 用戶名 \AppData\Local\imageio\ffmpeg\ffmpeg.win32.exe
def detect_objects(image_np, sess, detection_graph):
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
return image_np處理圖像
def process_image(image): # NOTE: The output you return should be a color image (3 channel) for processing video below # you should return the final output (image with lines are drawn on lanes) with detection_graph.as_default(): with tf.Session(graph=detection_graph) as sess: image_process = detect_objects(image, sess, detection_graph) return image_process
輸入視頻文件
white_output = 'video1_out.mp4'
clip1 = VideoFileClip("video1.mp4").subclip(25,30)
white_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!s
%time white_clip.write_videofile(white_output, audio=False)
其中video1.mp4已經從電腦中上傳至object_detection文件夾,subclip(25,30)代表識別視頻中25-30s這一時間段。原版視頻:  展示識別完畢的視頻:
展示識別完畢的視頻: 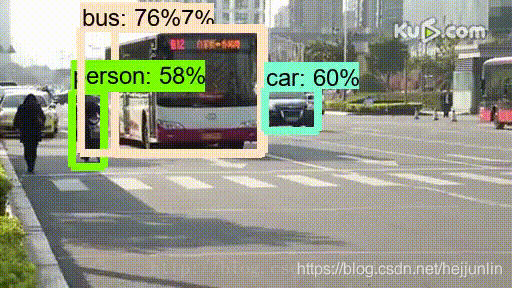
from moviepy.editor import *
clip1 = VideoFileClip("video1_out.mp4")
clip1.write_gif("final.gif")將識別完畢的視頻導為gif格式,并保存至object_detection文件夾。
看完上述內容,你們掌握如何使用TensorFlow進行訓練識別視頻圖像中物體的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





