溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Spark大數據分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
之前的Flask的基礎教程暫時先結束了。 因為目前所涉及到的東西已經能夠滿足我的需要。剩下的東西都是根據需求修改和優化。 不涉及更多的東西。 所以我也就是平時維護著,我們接下來講講Spark,為什么要講Spark呢,因為我們性能測試的需求要造10億級甚至更多的數據。普通的方式肯定不行了,得用到spark提交到yarn上運行才跑的動。所以現在我們來談論談論大數據方面的東西。同時大數據也是人工智能的基礎,現在搞搞大數據的東西,也為以后討論人工智能方面的測試做做鋪墊吧。
萬事開頭難,我剛接觸大數據的那會是天天的一臉懵逼。因為以前只跟數據庫打過交道,對于hadoop生態圈完全是沒聽過的狀態。看資料的時候也根本看不懂。所以我先介紹一下基礎的概念吧。
大數據,首先要能存的下大數據。 傳統的數據庫雖然衍生了主從,分片。但是他們在存儲上也無法應對TB甚至PB的數據量,尤其是在計算處理上他們更無法突破單機計算的桎梏。因為我們傳統的文件系統是單機的,不能橫跨不同的機器。在前些年的時候隨著互聯網的崛起,我們進入了數據爆炸的時代。傳統的數據存儲方式不論在存儲量上還是計算性能上都已經越來越跟不上數據發展的速度了。當時開發一個新的方式處理數據在業界呼聲很高。之后在04年(好像是吧,記不清了)Google發表了論文--MapReduce,詳細講述了Google的分布式計算原理。這時候業界才發現原來數據還可以這么玩,但是Google的良心大大滴壞,他只發了論文但是沒有開源,這把一干人等急的抓耳撓腮,后來Apache組織了一幫人根據Google的論文糊出了一個hadoop。直到現在hadoop生態已經發展了10余年(是的沒錯,我們現在看的很高大上的hadoop技術是人家Google玩剩下的)。
先前說我們傳統的文件系統是單機的,無法橫跨不同的機器。而HDFS的出現(Hadoop Distributed FileSystem),打破了我們單機的限制。HDFS是Apache專門研發的分布式文件系統。設計本質上是為了大量的數據能橫跨成百上千臺機器,但是你看到的是一個文件系統而不是多個。比如說我要取/hdfs/gaofei/file1上的數據。你引用的是一個文件路徑,但是實際的數據是存放在很多個不同的機器上的。作為用戶,我們不知道實際的物理存儲結構,我們知道的只要暴露給我們的邏輯路徑。那么在我們有能力存在這么大的數據后,就開始考慮怎么處理數據了。 雖然HDFS幫助我們管理不同機器上的數據并抽象一個統一接口給我們。但是這仍然改變不了這些數據非常大的事實。 如果我們仍然是在一臺機器上處理這海量的數據,那性能上仍然是不可接受的。那么如果我們要在多臺機器上同時處理這些數據,就面臨了一個機器之間如何通信和調度的問題。 這就是MapReduce/Spark的功能。MapReduce是第一代的產物,Apache研發的hadoop就是基于MapReduce框架(根據Google的論文而來)。Spark是第二代。 MapReduce采用了很簡化的模型,只有Map和Reduce兩個計算過程(中間用shuffle串聯)。
那什么是MapReduce呢, 舉個最常用的wordcount的例子。 假如你需要統計一個巨大的文件中所有單詞出現的詞頻。 首先你需要很多臺機器同時并發的讀取這個文件的各個部分,分別把自己讀到的部分進行第一步計算。 假如在這臺機器上,我讀取了一部分數據,對這些數據統計出了類似(Hello--100次)(word--1000次)這樣的結果。 每臺機器都讀取了部分數據并做了相同的操作。這就是MapReduce中的Map階段(額,中間其實還有別的操作,恕我學藝不精,解釋不清了)。然后我們進入Reduce階段,這個階段也會并發啟動很多的機器,框架會將Map機器上的數據按一定規則分別放到這些Reduce機器上進行計算。 例如我們把所有Hello這個單詞的放在ReduceA上,把所有word這個單詞的數據放到ReduceB上。然后ReduceA匯總所有的Map數據中的Hello這個單詞的結果,計算出這個單詞在數據中出現的詞頻為1000次。 ReduceB匯總所有Word這個單詞并計算出它在數據中出現的詞頻為1000次。這樣我們就統計出了這個巨大文件的詞頻了。 這就是MapReduce, 可以簡單理解為Map階段并發機器讀取不同的數據塊做第一步處理,然后Reduce階段并發機器按規則匯總Map階段的數據做第二部處理。中間有個很重要的過程是shuffle,暫時可以理解為這個shuffle就是哪些Map的數據放到哪個Reduce上的規則過程。詳細的不表示了,shuffle這個東西有點復雜,我們之后再講。
MapReduce的模型簡單暴力,但是程序寫起來真麻煩。因為全靠程序員編碼,框架只是提供了Map和Reduce的函數,至于里面什么邏輯全靠你自己寫。于是有了pig和Hive。Pig我沒怎么了解過,Hive是基于SQL的,它們把SQL翻譯成的MapReduce程序。有了Hive以后,大家發現Sql實在太容易寫了,這比寫java代碼方便太多了。例如我司的產品中,專門有一個算子是sql,可以讓業務人員也sql做拼表的動作。但是我們發現Hive在MapReduce上跑的特別慢,這個實在讓人接受不了。 于是中間又經過了幾個引擎的進化,Spark和SparkSQL應運而生。Spark不僅擁有新一代的計算引擎(跑的更快),而且內置了很多的方法供你操作數據,我們編寫起程序來現在變的更快更簡單。假如我們有這么一個需求,統計一個文件中a,b這兩個字母出現的單詞有多少個。 可以像下面這樣寫:
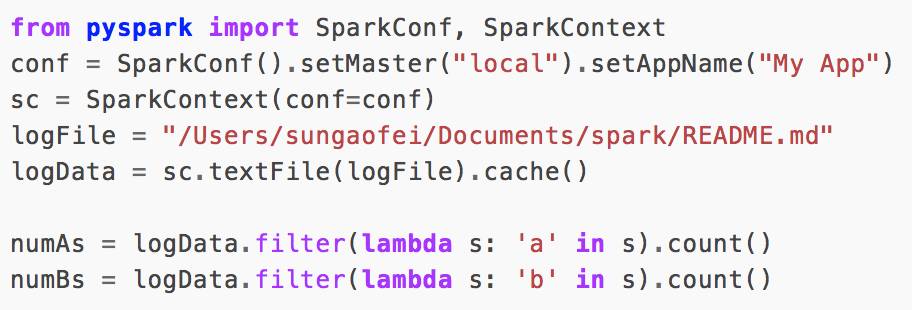
numAs和numBs就是我們統計的結果。可以看到spark提供了filter這種過濾函數和count這種內置的統計數量函數。 我們不再像以前MapReduce一樣要寫那么多的邏輯。 同時SparkSQL也支持了我們把SQL翻譯成代碼的功
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





