溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Web漏洞掃描器的設計與實現是怎么樣的,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
畢業設計給自己挖了個巨坑,雖然這個設想從我大二開始就已經有了一個大概的模型,但是實際實現起來與想象之中還是有很大的區別,特別是在漏洞報告準確度,與及速度方面有一些比較難的取舍,所以就開了一個新系列,記錄一下自己玩死自己的過程。
目前主流的漏洞掃描器大概分為以下三類。
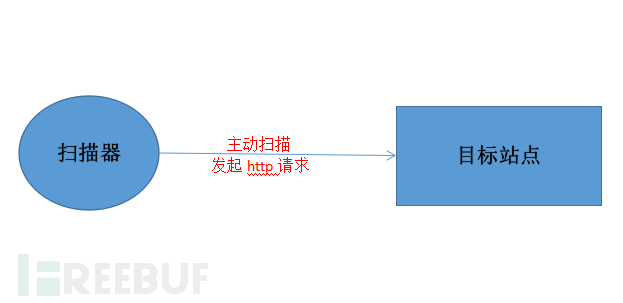
主動型:直接主動發起掃描請求。(ps: 圖自己畫的,丑別怪我hhhh)
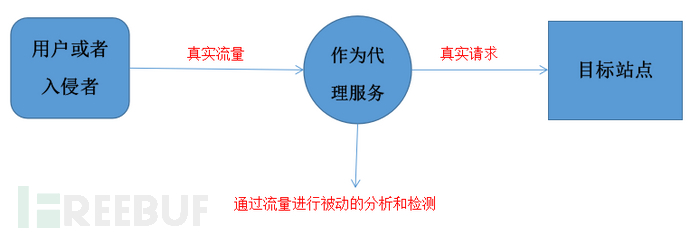
被動型:利用中間代理或者別的方式進行發現漏洞。
云掃描:部署在云端的掃描器,用戶通過瀏覽器就可進行掃描。
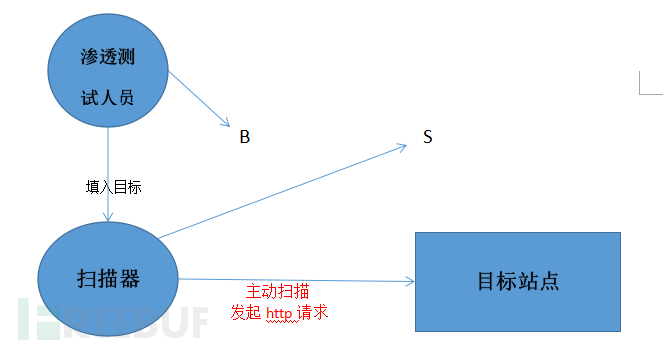
這里我打算做的是主動型與云端型,主體是主動型,主動型做好了,改成云端的不難。
03掃描器的工作流程
首先作為一個自動化的測試工具,得先弄清楚掃描器與手工測試的區別
手工滲透測試的流程如下
- 信息收集
- 漏洞發現
- 驗證漏洞
- 利用方法(EXP或者POC)
- 編寫測試報告
掃描器的流程
- 信息收集
- 發現漏洞(漏洞驗證)
- 生成報告
人為的滲透測試需要簽寫各類合約,在不破化業務的功能性下,盡可能的獲得更多的數據與及權限。但是掃描器不一樣。只需要點到即可,驗證漏洞,不需要后續的漏洞利用環節。
其中信息收集不管是在人為的滲透測試,還是掃描器中都是至關重要的一步,沒有信息收集,那就不會為下一步的發現漏洞做鋪墊,越多的信息對整個滲透測試或者掃描過程來說都是愈好的。
在WEB掃描中,我們大概所需要的信息如下
IP信息:其中這里的ip包括端口開放信息,c段信息等等。
子域名: 企業一般會把各種業務放在二級域名下,比如說百度的網盤業務地址為:pan.baidu.com
指紋信息:知曉目標的指紋信息可以去找相應的nday實現攻擊
敏感信息:敏感目錄,備份文件,未授權訪問的后臺,郵箱,數據庫等等
超鏈接: 在爬蟲對目標站點進行爬取時,都應該進行入庫處理,方便后續處理
在信息收集完畢之后,就需要對所收集到的內容進行漏洞發現,在漏洞發現之后還需要進行漏洞驗證,避免出現大量誤報,提高準確率
以下是主要進行的方式
端口:識別端口服務,進行相應的爆破,0day測試
URL:識別參數,進行類似sql注入等測試
cms:指紋識別。進行入庫匹配相應poc
http協議 :改變各類參數,進行fuzz
生成html或者execl格式報告
04如何設計
掃描器的設計我們得遵循一些原則,不然做出來的東西,難以維護,難以增減模塊,那不是我們想要的。
1,足夠的獨立性。
如果模塊之間相互影響太大,牽一發而動全身那明顯不是我們所需要的。
2,單一職責原則
如果某一個模塊擔任了太多的功能,那么很可能某個掛了然后剩下的也會掛的,所以一個模塊一個功能是非常必要的。
3,高并發的設計思想
掃描器如果做不到高并發,我想沒人愿意等到漫長的掃描時間。
所以根據以上信息,我們可以確定一下我們漏洞掃描器的功能模塊。
一 爬蟲模塊:
負責爬取目標站點可見的url,進行相應的入庫處理,然后分級處理,比如說可以遞交到敏感信息模塊去匹配信息,又或者遞交給漏洞檢測模塊進行檢測。爬蟲模塊作為漏掃的主要眼睛,必須非常壯碩,所以在未來的實現爬蟲模塊篇中,將會是個問題。
二 域名探測模塊:
進行子域名的查詢,包括二級,三級,多級。這里實現的方式主要有爆破,dns,搜索引擎。
三 端口掃描模塊:
通過各種方法獲取真實ip 爆破服務器端口,將結果遞交給指紋識別模塊進行識別與爆破模塊進行相應服務的爆破。
四 指紋識別模塊:
內置大量指紋信息,居然可拓展的性質,進行相應的指紋識別,并將識別結果提交漏洞檢測模塊進行相應的nday查詢。
五 敏感信息模塊:
具有大量敏感信息目錄,進行爆破操作,或者從爬蟲獲取相應數據進行匹配。
六 爆破模塊:
內置各類服務爆破操作。
七 漏洞檢測模塊:
分為常規漏洞檢測,與0day/nday檢測,如何做到高效率的檢測,又是一個問題了。
八 生成報告模塊:
將結果輸出成掃描報告。
九 “主控模塊”:
進行各模塊安全可控的調度,以高效率的運轉。
關于Web漏洞掃描器的設計與實現是怎么樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





