溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Flink簡單項目整體流程是怎樣的”,在日常操作中,相信很多人在Flink簡單項目整體流程是怎樣的問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Flink簡單項目整體流程是怎樣的”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
項目概述
CDN熱門分發網絡,日志數據分析,日志數據內容包括
aliyun CN E [17/Jul/2018:17:07:50 +0800] 223.104.18.110 v2.go2yd.com 17168
接入的數據類型就是日志
離線:Flume==>HDFS
實時: Kafka==>流處理引擎==>ES==>Kibana
數據查詢
| 接口名 | 功能描述 |
|---|---|
| 匯總統計查詢 | 峰值帶寬 總流量 總請求數 |
項目功能
統計一分鐘內每個域名訪問產生的流量,Flink接收Kafka的數據進行處理
統計一分鐘內每個用戶產生的流量,域名和用戶是有對應關系的,Flink接收Kafka的數據進行處理+Flink讀取域名和用戶的配置數據(在MySQL中)進行處理
項目架構
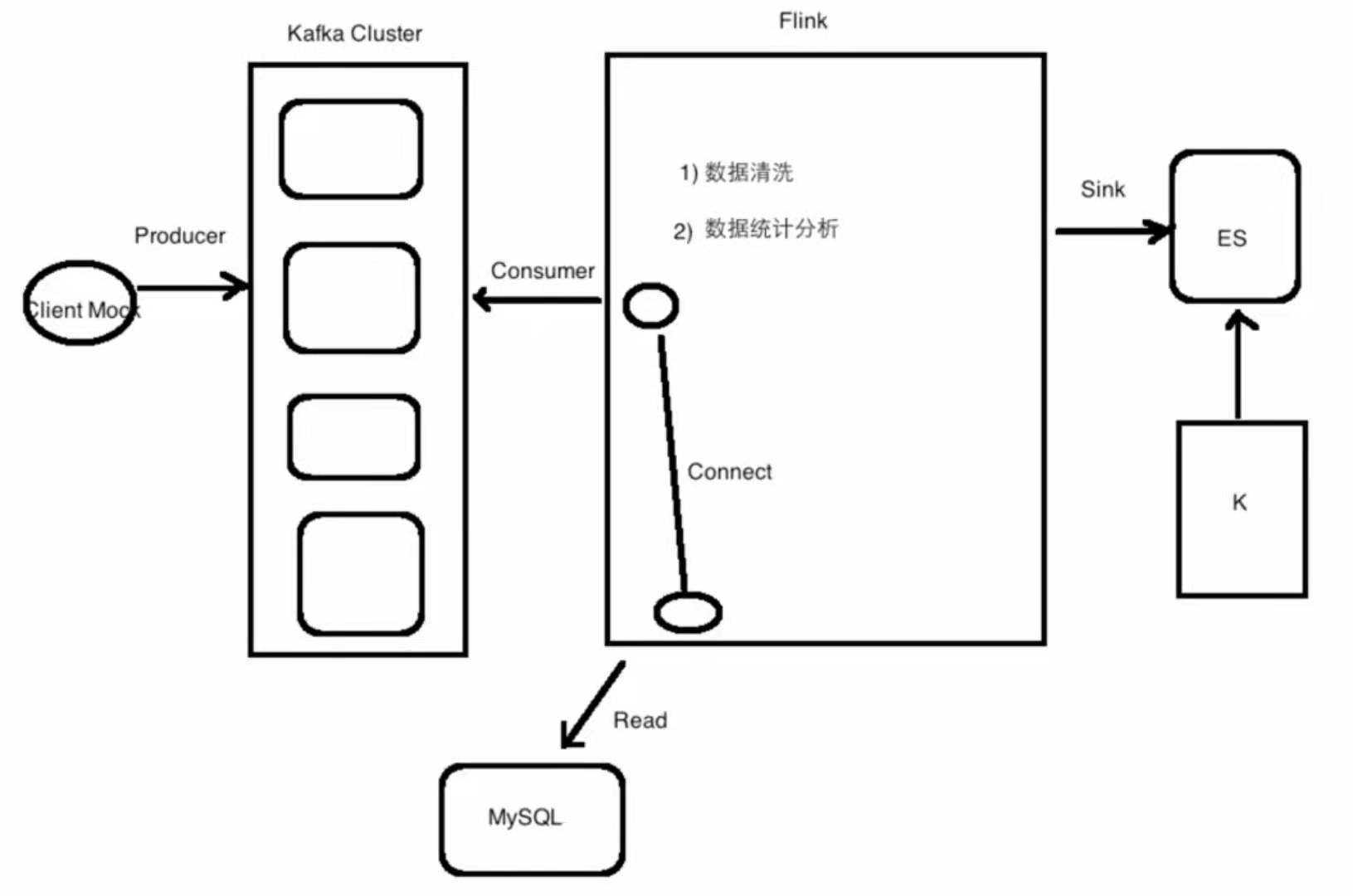
Mock數據
@Component@Slf4jpublic class KafkaProducer {private static final String TOPIC = "pktest"; @Autowired private KafkaTemplate<String,String> kafkaTemplate; @SuppressWarnings("unchecked")public void produce(String message) {try {
ListenableFuture future = kafkaTemplate.send(TOPIC, message); SuccessCallback<SendResult<String,String>> successCallback = new SuccessCallback<SendResult<String, String>>() {@Override public void onSuccess(@Nullable SendResult<String, String> result) {log.info("發送消息成功"); }
}; FailureCallback failureCallback = new FailureCallback() {@Override public void onFailure(Throwable ex) {log.error("發送消息失敗",ex); produce(message); }
}; future.addCallback(successCallback,failureCallback); } catch (Exception e) {log.error("發送消息異常",e); }
}@Scheduled(fixedRate = 1000 * 2)public void send() {
StringBuilder builder = new StringBuilder(); builder.append("aliyun").append("\t")
.append("CN").append("\t")
.append(getLevels()).append("\t")
.append(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
.format(new Date())).append("\t")
.append(getIps()).append("\t")
.append(getDomains()).append("\t")
.append(getTraffic()).append("\t"); log.info(builder.toString()); produce(builder.toString()); }/** * 生產Level數據 * @return */ private String getLevels() {
List<String> levels = Arrays.asList("M","E"); return levels.get(new Random().nextInt(levels.size())); }/** * 生產IP數據 * @return */ private String getIps() {
List<String> ips = Arrays.asList("222.104.18.111", "223.101.75.185", "27.17.127.133", "183.225.121.16", "112.1.65.32", "175.147.222.190", "183.227.43.68", "59.88.168.87", "117.28.44.29", "117.59.34.167"); return ips.get(new Random().nextInt(ips.size())); }/** * 生產域名數據 * @return */ private String getDomains() {
List<String> domains = Arrays.asList("v1.go2yd.com", "v2.go2vd.com", "v3.go2yd.com", "v4.go2yd.com", "vmi.go2yd.com"); return domains.get(new Random().nextInt(domains.size())); }/** * 生產流量數據 * @return */ private int getTraffic() {return new Random().nextInt(10000); }
}關于Springboot Kafka其他配置請參考Springboot2整合Kafka
打開Kafka服務器消費者,可以看到
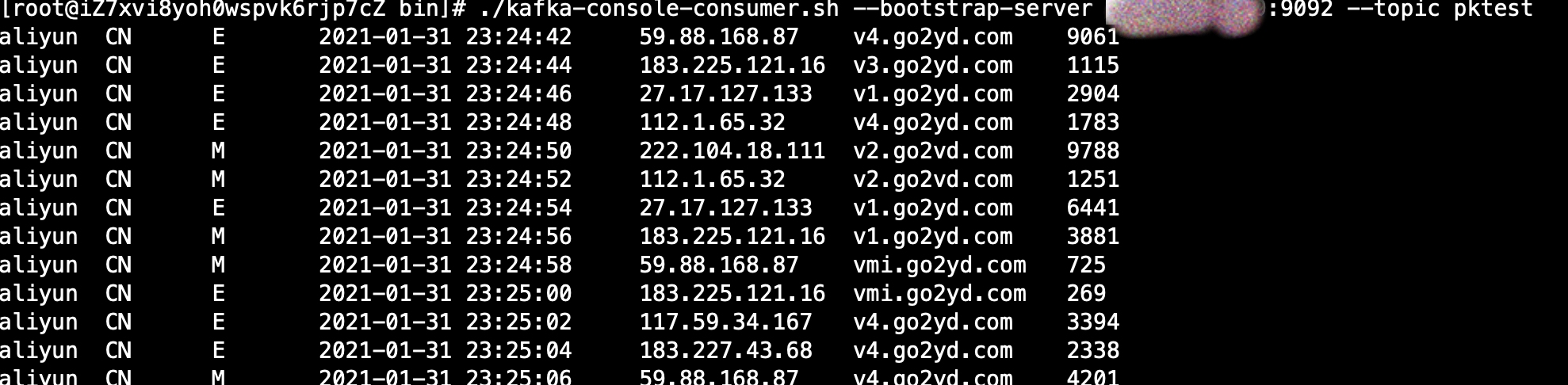
說明Kafka數據發送成功
Flink消費者
public class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.print().setParallelism(1); env.execute("LogAnalysis"); }
}接收到的消息
aliyun CN M 2021-01-31 23:43:07 222.104.18.111 v1.go2yd.com 4603 aliyun CN E 2021-01-31 23:43:09 222.104.18.111 v4.go2yd.com 6313 aliyun CN E 2021-01-31 23:43:11 222.104.18.111 v2.go2vd.com 4233 aliyun CN E 2021-01-31 23:43:13 222.104.18.111 v4.go2yd.com 2691 aliyun CN E 2021-01-31 23:43:15 183.225.121.16 v1.go2yd.com 212 aliyun CN E 2021-01-31 23:43:17 183.225.121.16 v4.go2yd.com 7744 aliyun CN M 2021-01-31 23:43:19 175.147.222.190 vmi.go2yd.com 1318
數據清洗
數據清洗就是按照我們的業務規則把原始輸入的數據進行一定業務規則的處理,使得滿足我們業務需求為準
@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E")) //拋棄level .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
}) .print().setParallelism(1); env.execute("LogAnalysis"); }
}運行結果
(1612130315000,v1.go2yd.com,533) (1612130319000,v4.go2yd.com,8657) (1612130321000,vmi.go2yd.com,4353) (1612130327000,v1.go2yd.com,9566) (1612130329000,v2.go2vd.com,1460) (1612130331000,vmi.go2yd.com,1444) (1612130333000,v3.go2yd.com,6955) (1612130337000,v1.go2yd.com,9612) (1612130341000,vmi.go2yd.com,1732) (1612130345000,v3.go2yd.com,694)
Scala代碼
import java.text.SimpleDateFormatimport java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._object LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.print().setParallelism(1)
env.execute("LogAnalysis")
}
}數據分析
現在我們要分析的是在一分鐘內的域名流量
@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E")) //拋棄level .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
})
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<Long, String, Long>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(1))
.timeWindow(Time.minutes(1)) //輸出格式:一分鐘的時間間隔,域名,該域名在一分鐘內的總流量 .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); }
})
.print().setParallelism(1); env.execute("LogAnalysis"); }
}運行結果
(2021-02-01 07:14:00 - 2021-02-01 07:15:00,vmi.go2yd.com,6307) (2021-02-01 07:15:00 - 2021-02-01 07:16:00,v4.go2yd.com,15474) (2021-02-01 07:15:00 - 2021-02-01 07:16:00,v2.go2vd.com,9210) (2021-02-01 07:15:00 - 2021-02-01 07:16:00,v3.go2yd.com,190) (2021-02-01 07:15:00 - 2021-02-01 07:16:00,v1.go2yd.com,12787) (2021-02-01 07:15:00 - 2021-02-01 07:16:00,vmi.go2yd.com,14250) (2021-02-01 07:16:00 - 2021-02-01 07:17:00,v4.go2yd.com,33298) (2021-02-01 07:16:00 - 2021-02-01 07:17:00,v1.go2yd.com,37140)
Scala代碼
import java.text.SimpleDateFormatimport java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.util.Collectorobject LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._2)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long),(String,String,Long),String,TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long)], out: Collector[(String, String, Long)]): Unit = {val list = input.toListval sum = list.map(_._3).sumval format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
})
.print().setParallelism(1)
env.execute("LogAnalysis")
}
}Sink到Elasticsearch
安裝ES
我們這里使用的版本為6.2.4
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
解壓縮后進入config目錄,編輯elasticsearch.yml,修改
network.host: 0.0.0.0
增加一個非root用戶
useradd es
將ES目錄下的所有文件更改為es所有者
chown -R es:es elasticsearch-6.2.4
修改/etc/security/limits.conf,將最下方的內容改為
es soft nofile 65536 es hard nofile 65536
修改/etc/sysctl.conf,增加
vm.max_map_count=655360
執行命令
sysctl -p
進入es的bin文件夾,并切換用戶es
su es
在es用戶下執行
./elasticsearch -d
此時可以在Web界面中看到ES的信息(外網ip:9200)

給Flink添加ES Sink,先添加依賴
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7_2.11</artifactId> <version>${flink.version}</version></dependency>@Slf4jpublic class LogAnalysis {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("外網ip",9200,"http")); ElasticsearchSink.Builder<Tuple3<String,String,Long>> builder = new ElasticsearchSink.Builder<>(httpHosts, new ElasticsearchSinkFunction<Tuple3<String, String, Long>>() {@Override public void process(Tuple3<String, String, Long> value, RuntimeContext runtimeContext, RequestIndexer indexer) {
Map<String,Object> json = new HashMap<>(); json.put("time",value.getField(0)); json.put("domain",value.getField(1)); json.put("traffic",value.getField(2)); String id = value.getField(0) + "-" + value.getField(1); indexer.add(Requests.indexRequest()
.index("cdn")
.type("traffic")
.id(id)
.source(json)); }
}); //設置批量寫數據的緩沖區大小 builder.setBulkFlushMaxActions(1); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level,time,domain,traffic); }
}).filter(x -> (Long) x.getField(1) != 0) //此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E")) //拋棄level .map(new MapFunction<Tuple4<String,Long,String,String>, Tuple3<Long,String,Long>>() { @Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception { return new Tuple3<>(value.getField(1),value.getField(2),Long.parseLong(value.getField(3))); }
})
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<Long, String, Long>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(1))
.timeWindow(Time.minutes(1)) //輸出格式:一分鐘的時間間隔,域名,該域名在一分鐘內的總流量 .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); }
})
.addSink(builder.build()); env.execute("LogAnalysis"); }
}執行后可以在ES中查詢到數據
http://外網ip:9200/cdn/traffic/_search

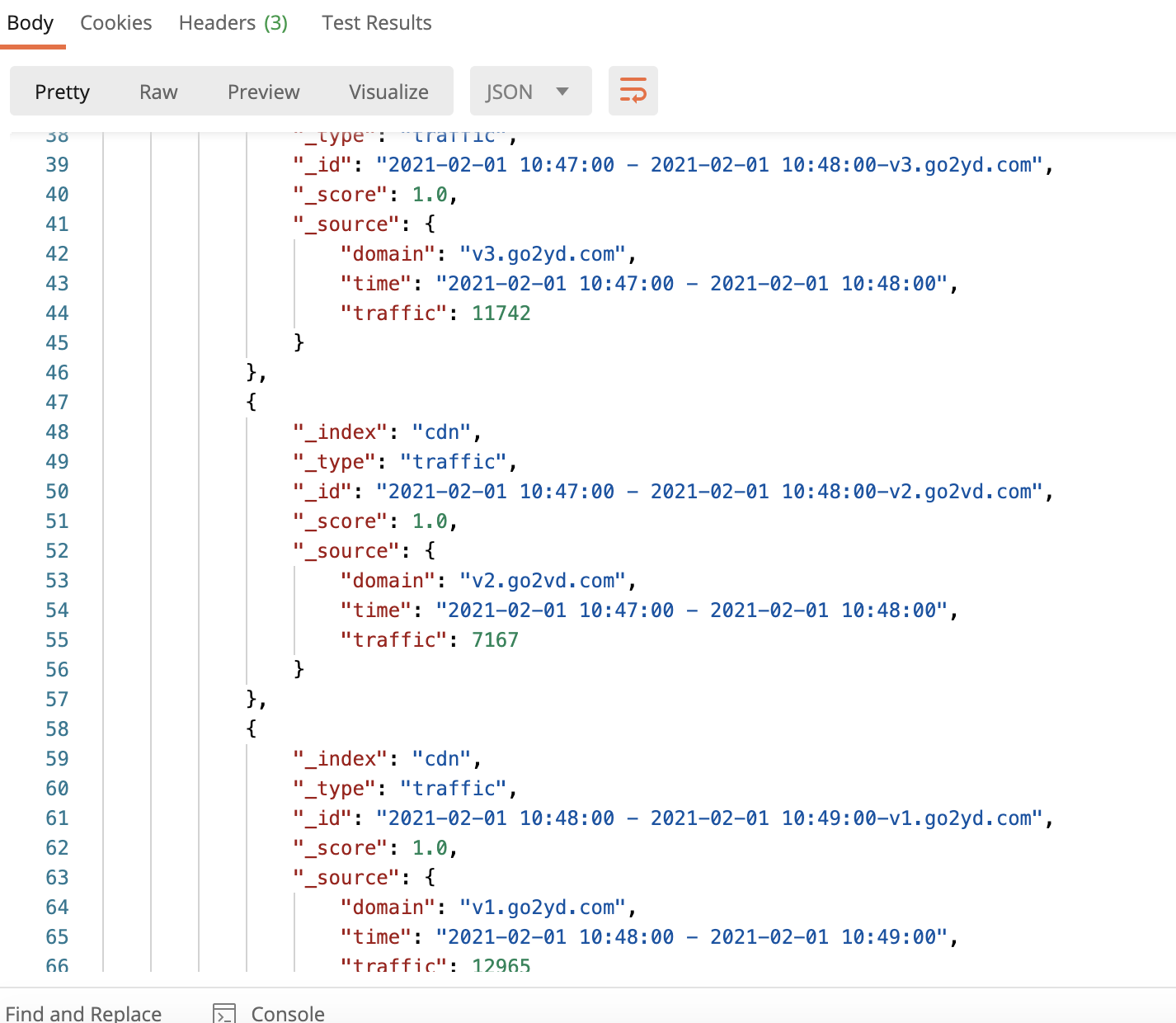
Scala代碼
import java.text.SimpleDateFormatimport java.utilimport java.util.Propertiesimport org.apache.flink.api.common.functions.RuntimeContextimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.slf4j.LoggerFactoryimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSinkimport org.apache.flink.util.Collectorimport org.apache.http.HttpHostimport org.elasticsearch.client.Requestsobject LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val httpHosts = new util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("外網ip",9200,"http"))val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,new ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = {val json = new util.HashMap[String,Any]
json.put("time",t._1)
json.put("domain",t._2)
json.put("traffic",t._3)val id = t._1 + "-" + t._2
indexer.add(Requests.indexRequest()
.index("cdn")
.`type`("traffic")
.id(id)
.source(json))
}
})
builder.setBulkFlushMaxActions(1)val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))
data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))
.setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._2)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long),(String,String,Long),String,TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long)], out: Collector[(String, String, Long)]): Unit = {val list = input.toListval sum = list.map(_._3).sumval format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
})
.addSink(builder.build)
env.execute("LogAnalysis")
}
}Kibana圖形展示
安裝kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
kibana要跟ES保持版本相同,解壓縮后進入config目錄,編輯kibana.yml
server.host: "host2" elasticsearch.url: "http://host2:9200"
這里面的內容會根據版本不同會有一些不同,保存后,進入bin目錄
切換es用戶,執行
./kibana &
訪問Web頁面,外網ip:5601
這里我做了一個表,一個柱狀圖
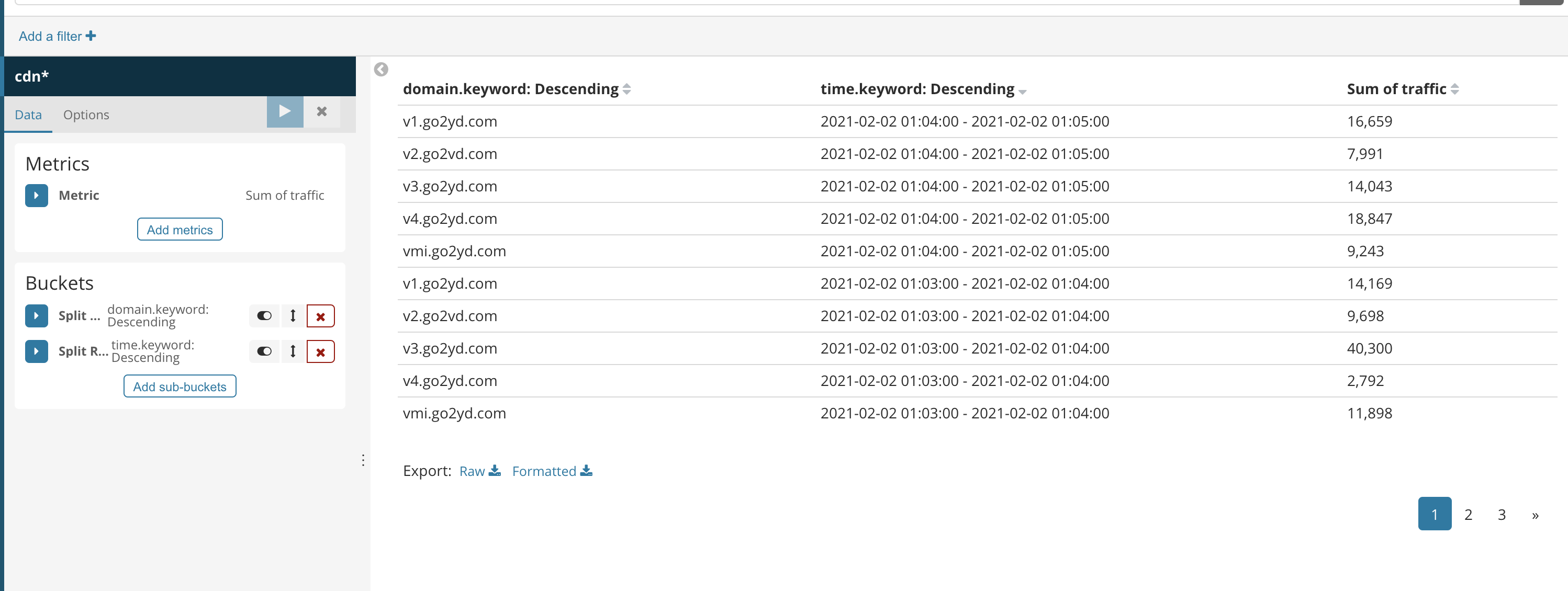
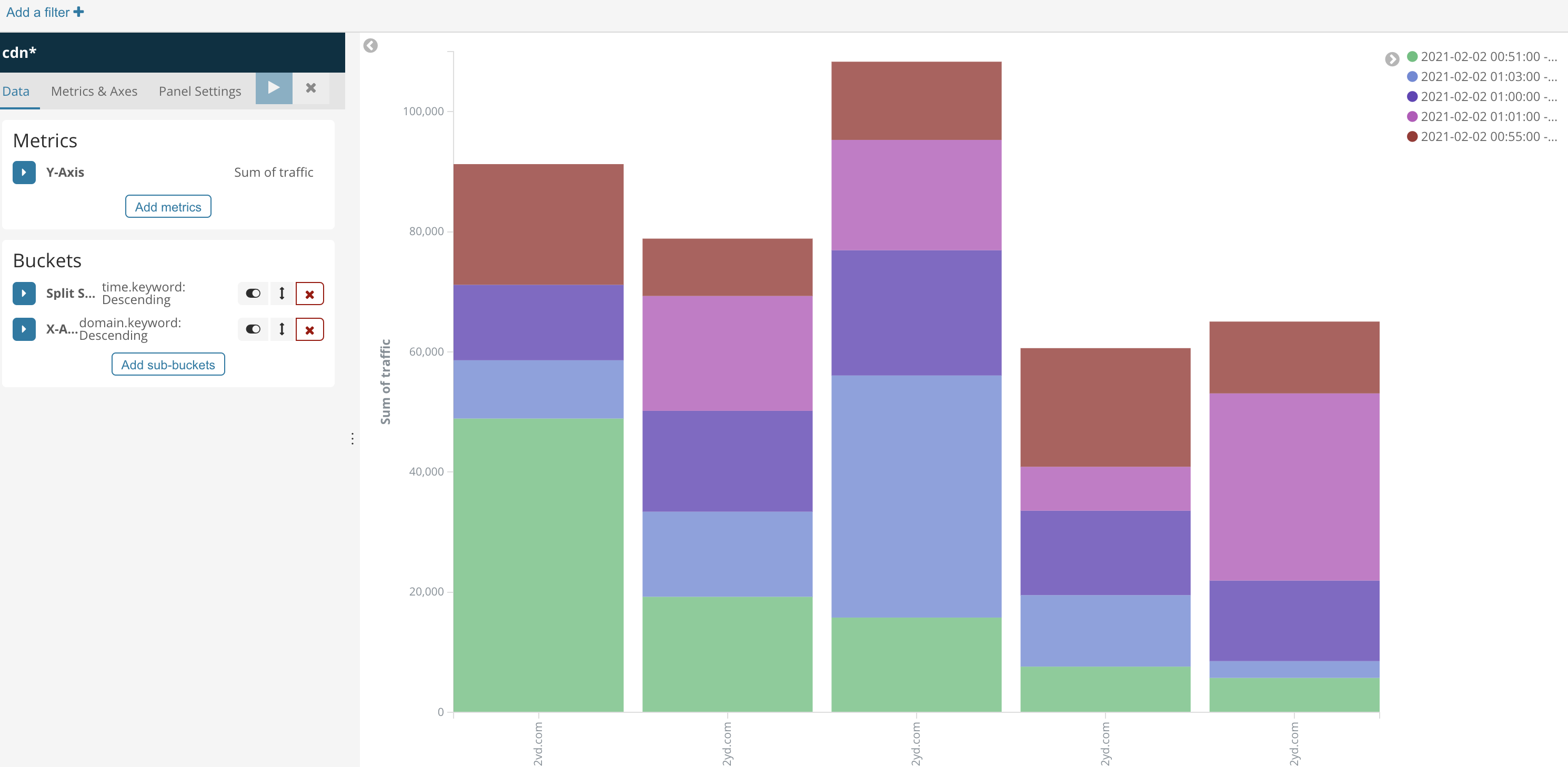
第二個需求,統計一分鐘內每個用戶產生的流量
在MySQL數據庫中新增一張表user_domain_config,字段如下

表中內容如下
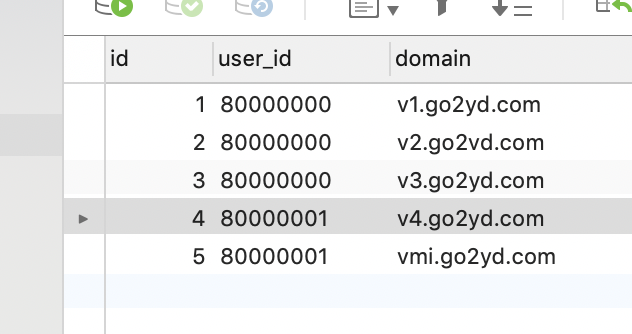
數據清洗
/** * 自定義MySQL數據源 */public class MySQLSource extends RichParallelSourceFunction<Tuple2<String,String>> {private Connection connection; private PreparedStatement pstmt; private Connection getConnection() {
Connection conn = null; try {
Class.forName("com.mysql.cj.jdbc.Driver"); String url = "jdbc:mysql://外網ip:3306/flink"; conn = DriverManager.getConnection(url,"root","******"); }catch (Exception e) {
e.printStackTrace(); }return conn; }@Override public void open(Configuration parameters) throws Exception {super.open(parameters); connection = getConnection(); String sql = "select user_id,domain from user_domain_config"; pstmt = connection.prepareStatement(sql); }@Override @SuppressWarnings("unchecked")public void run(SourceContext<Tuple2<String,String>> ctx) throws Exception {
ResultSet rs = pstmt.executeQuery(); while (rs.next()) {
Tuple2 tuple2 = new Tuple2(rs.getString("domain"),rs.getString("user_id")); ctx.collect(tuple2); }pstmt.close(); }@Override public void cancel() {
}@Override public void close() throws Exception {super.close(); if (pstmt != null) {pstmt.close(); }if (connection != null) {connection.close(); }
}
}@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E"))//拋棄level .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //雙流匯聚 logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); }
}運行結果
(1612239325000,vmi.go2yd.com,7115,80000001) (1612239633000,v4.go2yd.com,8412,80000001) (1612239635000,v3.go2yd.com,3527,80000000) (1612239639000,v1.go2yd.com,7385,80000000) (1612239643000,vmi.go2yd.com,8650,80000001) (1612239645000,vmi.go2yd.com,2642,80000001) (1612239647000,vmi.go2yd.com,1525,80000001) (1612239649000,v2.go2vd.com,8832,80000000)
Scala代碼
import java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}class MySQLSource extends RichParallelSourceFunction[(String,String)]{ var connection: Connection = null var pstmt: PreparedStatement = null def getConnection:Connection = {var conn: Connection = null Class.forName("com.mysql.cj.jdbc.Driver")val url = "jdbc:mysql://外網ip:3306/flink" conn = DriverManager.getConnection(url, "root", "******")
conn
} override def open(parameters: Configuration): Unit = {connection = getConnectionval sql = "select user_id,domain from user_domain_config" pstmt = connection.prepareStatement(sql)
} override def cancel() = {} override def run(ctx: SourceFunction.SourceContext[(String, String)]) = {val rs = pstmt.executeQuery()while (rs.next) { val tuple2 = (rs.getString("domain"),rs.getString("user_id"))
ctx.collect(tuple2)
}pstmt.close()
} override def close(): Unit = {if (pstmt != null) { pstmt.close()
}if (connection != null) { connection.close()
}
}
}import java.text.SimpleDateFormatimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
}
}數據分析
@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E"))//拋棄level .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //雙流匯聚 logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(3))
.timeWindow(Time.minutes(1)) //輸出格式:一分鐘的時間間隔,用戶,該用戶在一分鐘內的總流量 .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); }
}).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); }
}運行結果
(2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000000,20933) (2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000001,6928) (2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000001,38202) (2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000000,39394) (2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000001,23070) (2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000000,41701)
Scala代碼
import java.text.SimpleDateFormatimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long, String)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._4)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long,String),(String,String,Long),String,TimeWindow] {override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long, String)], out: Collector[(String, String, Long)]): Unit = { val list = input.toList val sum = list.map(_._3).sum val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
}
}Sink到ES
@Slf4jpublic class LogAnalysisWithMySQL {public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String topic = "pktest"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers","外網ip:9092"); properties.setProperty("group.id","test"); List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("外網ip",9200,"http")); ElasticsearchSink.Builder<Tuple3<String,String,Long>> builder = new ElasticsearchSink.Builder<>(httpHosts, new ElasticsearchSinkFunction<Tuple3<String, String, Long>>() {@Override public void process(Tuple3<String, String, Long> value, RuntimeContext runtimeContext, RequestIndexer indexer) {
Map<String,Object> json = new HashMap<>(); json.put("time",value.getField(0)); json.put("userId",value.getField(1)); json.put("traffic",value.getField(2)); String id = value.getField(0) + "-" + value.getField(1); indexer.add(Requests.indexRequest()
.index("user")
.type("traffic")
.id(id)
.source(json)); }
}); //設置批量寫數據的緩沖區大小 builder.setBulkFlushMaxActions(1); DataStreamSource<String> data = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties)); SingleOutputStreamOperator<Tuple3<Long, String, Long>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {@Override public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t"); String level = splits[2]; String timeStr = splits[3]; Long time = 0L; try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime(); } catch (ParseException e) {log.error("time轉換錯誤:" + timeStr + "," + e.getMessage()); }
String domain = splits[5]; String traffic = splits[6]; return new Tuple4<>(level, time, domain, traffic); }
}).filter(x -> (Long) x.getField(1) != 0)//此處我們只需要Level為E的數據 .filter(x -> x.getField(0).equals("E"))//拋棄level .map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {@Override public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {return new Tuple3<>(value.getField(1), value.getField(2), Long.parseLong(value.getField(3))); }
}); DataStreamSource<Tuple2<String, String>> mysqlData = env.addSource(new MySQLSource()); //雙流匯聚 logData.connect(mysqlData).flatMap(new CoFlatMapFunction<Tuple3<Long,String,Long>, Tuple2<String,String>, Tuple4<Long,String,Long,String>>() {private Map<String,String> userDomainMap = new HashMap<>(); @Override public void flatMap1(Tuple3<Long, String, Long> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {
String domain = value.getField(1); String userId = userDomainMap.getOrDefault(domain,""); out.collect(new Tuple4<>(value.getField(0),value.getField(1),value.getField(2),userId)); }@Override public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception {userDomainMap.put(value.getField(0),value.getField(1)); }
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() {private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() {return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }@Override public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) {
Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; }
}).keyBy(x -> (String) x.getField(3))
.timeWindow(Time.minutes(1)) //輸出格式:一分鐘的時間間隔,用戶,該用戶在一分鐘內的總流量 .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); }
}).addSink(builder.build()); env.execute("LogAnalysisWithMySQL"); }
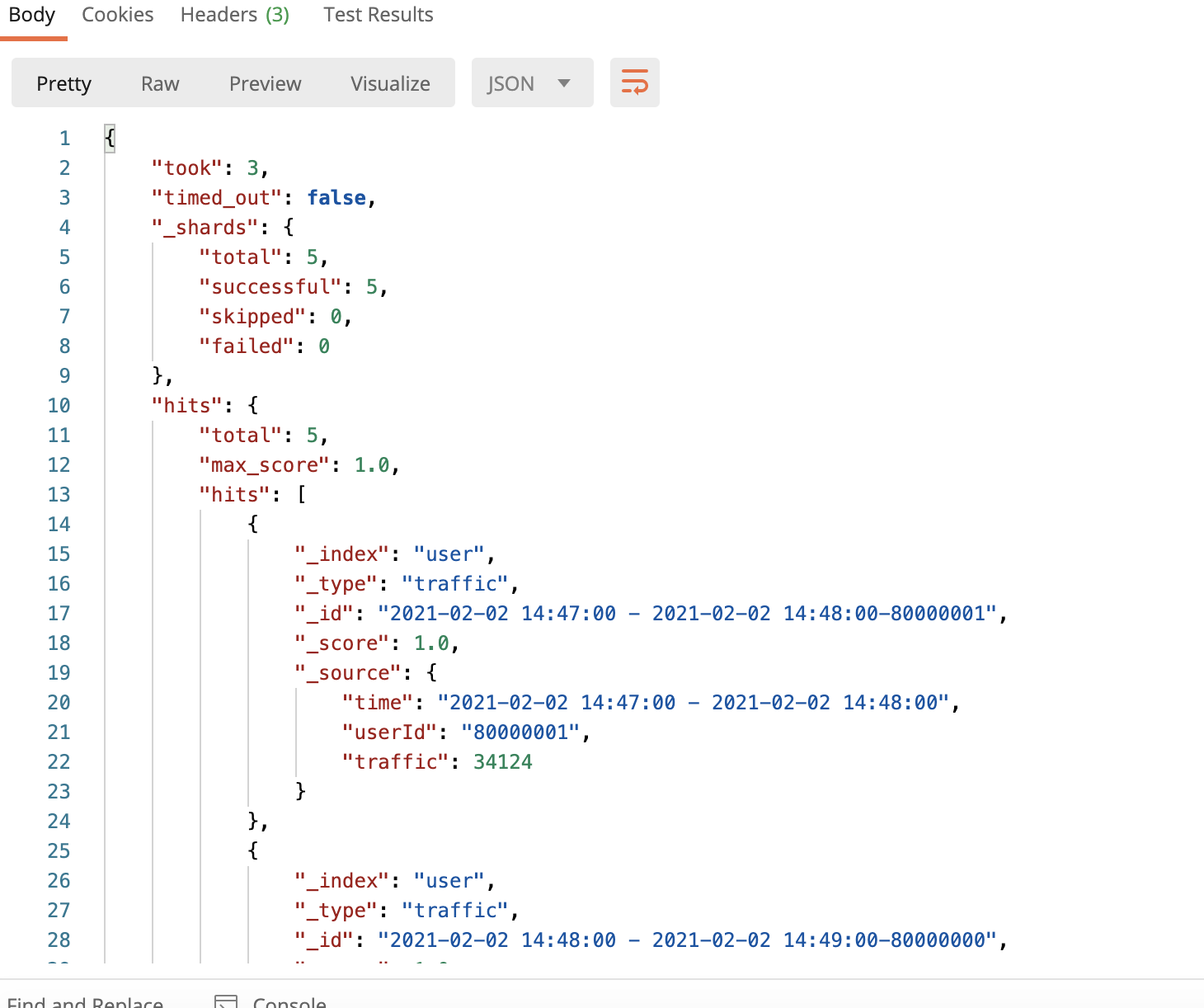
}運行結果
訪問http://外網ip:9200/user/traffic/_search

Scala代碼
port java.text.SimpleDateFormatimport java.utilimport java.util.Propertiesimport com.guanjian.flink.scala.until.MySQLSourceimport org.apache.flink.api.common.functions.RuntimeContextimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.scala._import org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarksimport org.apache.flink.streaming.api.functions.co.CoFlatMapFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala.function.WindowFunctionimport org.apache.flink.streaming.api.watermark.Watermarkimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindowimport org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer}import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSinkimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerimport org.apache.flink.util.Collectorimport org.apache.http.HttpHostimport org.elasticsearch.client.Requestsimport org.slf4j.LoggerFactoryimport scala.collection.mutableobject LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass) def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)val topic = "pktest" val properties = new Properties
properties.setProperty("bootstrap.servers", "外網ip:9092")
properties.setProperty("group.id","test")val httpHosts = new util.ArrayList[HttpHost]
httpHosts.add(new HttpHost("外網ip",9200,"http"))val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,new ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = {val json = new util.HashMap[String,Any]
json.put("time",t._1)
json.put("userId",t._2)
json.put("traffic",t._3)val id = t._1 + "-" + t._2
indexer.add(Requests.indexRequest()
.index("user")
.`type`("traffic")
.id(id)
.source(json))
}
})
builder.setBulkFlushMaxActions(1)val data = env.addSource(new FlinkKafkaConsumer[String](topic, new SimpleStringSchema, properties))val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try {
time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime
}catch {case e: Exception => { log.error(s"time轉換錯誤: $timeStr",e.getMessage)
}
} val domain = splits(5) val traffic = splits(6)
(level,time,domain,traffic)
}).filter(_._2 != 0)
.filter(_._1 == "E")
.map(x => (x._2,x._3,x._4.toLong))val mysqlData = env.addSource(new MySQLSource)
logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]() override def flatMap1(value: (Long, String, Long), out: Collector[(Long, String, Long, String)]) = {val domain = value._2val userId = userDomainMap.getOrElse(domain,"")
out.collect((value._1,value._2,value._3,userId))
} override def flatMap2(value: (String, String), out: Collector[(Long, String, Long, String)]) = {userDomainMap += value._1 -> value._2
}
}).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long, String)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _ override def getCurrentWatermark: Watermark = {new Watermark(currentMaxTimestamp - maxOutOfOrderness)
} override def extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long = {val timestamp = element._1currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp)
timestamp
}
}).keyBy(_._4)
.timeWindow(Time.minutes(1))
.apply(new WindowFunction[(Long,String,Long,String),(String,String,Long),String,TimeWindow] {override def apply(key: String, window: TimeWindow, input: Iterable[(Long, String, Long, String)], out: Collector[(String, String, Long)]): Unit = { val list = input.toList val sum = list.map(_._3).sum val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " + format.format(window.getEnd),key,sum))
}
}).addSink(builder.build)
env.execute("LogAnalysisWithMySQL")
}
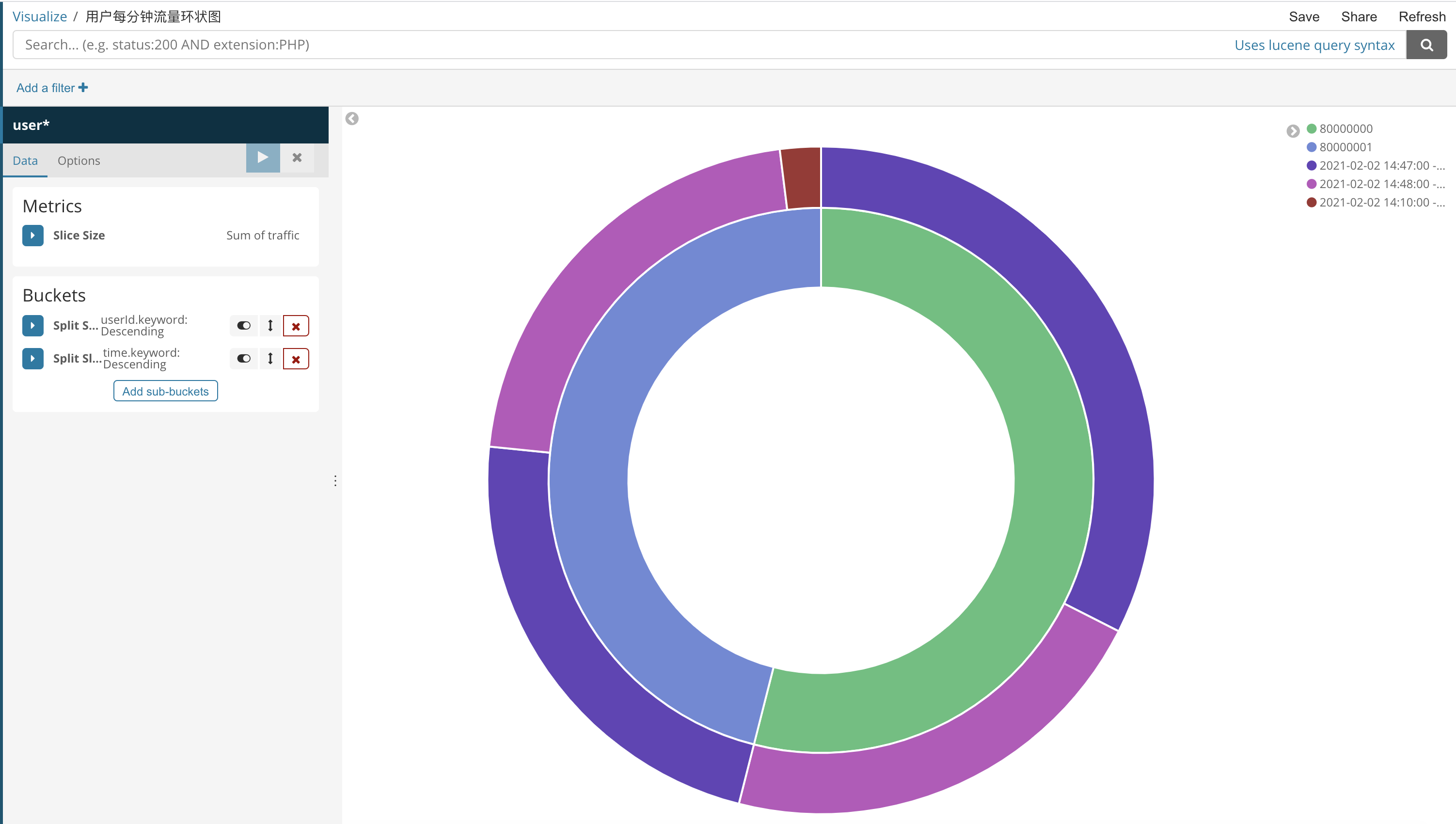
}Kibana圖表展示
這里我們就畫一個環狀圖吧
到此,關于“Flink簡單項目整體流程是怎樣的”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





