溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
SpringBoot項目的流程是怎樣的,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
前言
在我的工作中,我從零開始搭建了不少軟件項目,其中包含了基礎代碼框架和持續集成基礎設施等,這些內容在敏捷開發中通常被稱為“第0個迭代”要做的事情。但是,當項目運行了一段時間之后再來反觀,我總會發現一些不足的地方,要么測試分類沒有分好,要么基本的編碼架子沒有考慮周全。
另外,我在工作中也會接觸到很多既有項目,公司內部和外部的都有,多數項目的編碼實踐我都是不滿意的。比如,我曾經新加入一個項目的時候,前前后后請教了3位同事才把該項目在本地運行起來;又比如在另一項目中,我發現前端請求對應的Java類命名規范不統一,有被后綴為Request的,也有被后綴為Command的。
再者,工作了這么多年之后,我越來越發現基礎知識以及系統性學習的重要性。誠然,技術框架的發展使得我們可以快速地實現業務功能,但是當軟件出了問題之后有時卻需要將各方面的知識融會貫通并在大腦里綜合反應才能找到解決思路。
基于以上,我希望整理出一套公共性的項目模板出來,旨在盡量多地包含日常開發之所需,減少開發者的重復性工作以及提供一些最佳實踐。對于后端開發而言,我選擇了當前被行業大量使用的Spring Boot。
本文以一個簡單的電商訂單系統為例,源代碼請訪問:
git clone https://github.com/e-commerce-sample/order-backend
git checkout a443dace
所使用的技術棧主要包括:Spring Boot、Gradle、MySQL、Junit 5、Rest Assured、Docker等。
一份好的README可以給人以項目全景概覽,可以使新人快速上手項目,可以降低溝通成本。同時,README應該簡明扼要,條理清晰,建議包含以下方面:
項目簡介:用一兩句話簡單描述該項目所實現的業務功能;
技術選型:列出項目的技術棧,包括語言、框架和中間件等;
本地構建:列出本地開發過程中所用到的工具命令;
領域模型:核心的領域概念,比如對于示例電商系統來說有Order、Product等;
測試策略:自動化測試如何分類,哪些必須寫測試,哪些沒有必要寫測試;
技術架構:技術架構圖;
部署架構:部署架構圖;
外部依賴:項目運行時所依賴的外部集成方,比如訂單系統會依賴于會員系統;
環境信息:各個環境的訪問方式,數據庫連接等;
編碼實踐:統一的編碼實踐,比如異常處理原則、分頁封裝等;
FAQ:開發過程中常見問題的解答。
需要注意的是,README中的信息可能隨著項目的演進而改變(比如引入了新的技術棧或者加入了新的領域模型),因此也是需要持續更新的。雖然我們知道,軟件文檔的一個痛點便是無法與項目實際進展保持同步,但是就README這點信息來講,還是建議開發者們不要吝嗇那一點點敲鍵盤的時間。
此外,除了保持README的持續更新,一些重要的架構決定可以通過示例代碼的形式記錄在代碼庫中,新開發者可以通過直接閱讀這些示例代碼快速了解項目的通用實踐方式以及架構選擇,請參考:
https://www.thoughtworks.com/radar/techniques/lightweight-architecture-decision-records
為了避免諸如前文中所提到的“請教了3位同事才本地構建成功”的尷尬,為了減少“懶惰”的程序員們的手動操作,也為了為所有開發者提供一種一致的開發體驗,我們希望用一個命令就可以完成所有的事情。這里,對于不同的場景我總結出了以下命令:
生成IDE工程:idea.sh,生成IntelliJ工程文件并自動打開IntelliJ
本地運行:run.sh,本地啟動項目,自動啟動本地數據庫,監聽調試端口5005
本地構建:local-build.sh,只有本地構建成功才能提交代碼
以上3個命令基本上可以完成日常開發之所需,此時,對于新人的開發流程大致為:
拉取代碼;
運行idea.sh,自動打開IntelliJ;
編寫代碼,包含業務代碼和自動化測試;
運行run.sh,進行本地調試或必要的手動測試(本步驟不是必需);
運行local-build.sh,完成本地構建;
再次拉取代碼,保證local-build.sh成功,提交代碼。
事實上,這些命令腳本的內容非常簡單,比如run.sh文件內容為:
#!/usr/bin/env bash./gradlew clean bootRun
然而,這種顯式化的命令卻可以減少新人的恐懼感,因為他們只需要知道運行這3個命令就可以搞開發了。另外,一個小小的細節:本地構建的local-build.sh命令本來可以重命名為更簡單的build.sh,但是當我們在命令行中使用Tab鍵自動補全的時候,會發現自動補全到了build目錄,而不是build.sh命令,并不方便,因此命名為了local-build.sh。
細節雖小,但是卻體現了一個宗旨,即我們希望給開發者一種極簡的開發體驗,我把這些看似微不足道的東西稱作是對程序員的“人文關懷”。
Maven所提倡的目錄結構當前已經成為事實上的行業標準,Gradle在默認情況下也采用了Maven的目錄結構,這對于多數項目來說已經足夠了。此外,除了Java代碼,項目中還存在其他類型的文件,比如Gradle插件的配置、工具腳本和部署配置等。無論如何,項目目錄結構的原則是簡單而有條理,不要隨意地增加多余的文件夾,并且也需要及時重構。
在示例項目中,頂層只有2個文件夾,一個是用于放置Java源代碼和項目配置的src文件夾,另一個是用于放置所有Gradle配置的gradle文件夾,此外,為了方便開發人員使用,將上文提到的3個常用腳本直接放到根目錄下:
└── order-backend ├── gradle // 文件夾,用于放置所有Gradle配置 ├── src // 文件夾,Java源代碼 ├── idea.sh //生成IntelliJ工程 ├── local-build.sh // 提交之前的本地構建 └── run.sh // 本地運行
對于gradle而言,我們刻意地將Gradle插件腳本與插件配置放到了一起,比如Checkstyle:
├── gradle│ ├── checkstyle│ │ ├── checkstyle.gradle│ │ └── checkstyle.xml
事實上,在默認情況下Checkstyle插件會從項目根目錄下的config目錄查找checkstyle.xml配置文件,但是這一方面增加了多余的文件夾,另一方面與該插件相關的設施分散在了不同的地方,違背了廣義上的內聚原則。
早年的Java分包方式通常是基于技術的,比如與domain包平級的有controller包、service包和infrastructure包等。這種方式當前并不被行業所推崇,而是應該首先基于業務分包。
比如,在訂單示例項目中,有兩個重要的領域對象Order和Product(在DDD中稱為聚合根),所有的業務都圍繞它們展開,因此分別創建order包和product包,再分別在包下創建與之相關的各個子包。此時的order包如下:
├── order│ ├── OrderApplicationService.java│ ├── OrderController.java│ ├── OrderNotFoundException.java│ ├── OrderRepository.java│ ├── OrderService.java│ └── model│ ├── Order.java│ ├── OrderFactory.java│ ├── OrderId.java│ ├── OrderItem.java│ └── OrderStatus.java
可以看到,在order包下我們直接放置了OrderController和OrderRepository等類,而沒有必要再為這些類劃分單獨的子包。而對于領域模型Order來講,由于包含了多個對象,因此基于內聚性原則將它們歸到model包中。但是這并不是一個必須,如果業務足夠簡單,我們甚至可以將所有類直接放到業務包下,product包便是如此:
└── product ├── Product.java ├── ProductApplicationService.java ├── ProductController.java ├── ProductId.java └── ProductRepository.java
在編碼實踐中,我們總是基于一個業務用例來實現代碼,在技術分包場景下,我們需要在分散的各包中來回切換,增加了代碼導航的成本;另外,代碼提交的變更內容也是散落的,在查看代碼提交歷史時,無法直觀的看出該次提交是關于什么業務功能的。
在業務分包下,我們只需要在單個統一的包下修改代碼,減少了代碼導航成本;另外一個好處是,如果哪天我們需要將某個業務遷移到另外的項目(比如識別出了獨立的微服務),那么直接整體移動業務包即可。
當然,基于業務分包并不意味著所有的代碼都必須囿于業務包下,這里的邏輯是:優先進行業務分包,然后對于一些不隸屬于任何業務的代碼可以單獨分包,比如一些util類、公共配置等。比如我們依然可以創建一個common包,下面放置了Spring公共配置、異常處理框架和日志等子包:
└── common ├── configuration ├── exception ├── loggin └── utils
在當前的微服務和前后端分離的開發模式下,后端項目僅提供純粹的業務API,而不包含UI邏輯,因此后端項目不會再包含諸如WebDriver的重量級端到端測試。同時,后端項目作為向外提供業務功能的獨立運行單元,在API級別也應該有相應的測試。
此外,程序中有些框架性代碼,要么是諸如Controller之類的技術性框架代碼,要么是基于某種架構風格的代碼(比如DDD實踐中的ApplicationService),這些代碼一方面并不包含業務邏輯,一方面是很薄的一個抽象層(即實現相對簡單),用單元測試來覆蓋顯得沒有必要,因此筆者的觀點是可以不為此編寫單獨的單元測試。歡迎關注公眾號"Java學習之道",查看更多干貨!
再者,程序中有些重要的組件性代碼,比如訪問數據庫的Repository或者分布式鎖,使用單元測試實際上“測不到點上”,而使用API測試又顯得在分類邏輯上不合理,為此我們可以專門創建一種測試類型謂之組件測試。
基于以上,我們可以對自動化測試做個分類:
單元測試:核心的領域模型,包括領域對象(比如Order類),Factory類,領域服務類等;
組件測試:不適合寫單元測試但是又必須測試的類,比如Repository類,在有些項目中,這種類型測試也被稱為集成測試;
API測試:模擬客戶端測試各個API接口,需要啟動程序。
Gradle在默認情況下只提供src/test/java目錄用于測試,對于以上3種類型的測試,我們需要將它們分開以便于管理(也是職責分離的體現)。為此,可以通過Gradle提供的SourceSets對測試代碼進行分類:
sourceSets {componentTest {compileClasspath += sourceSets.main.output + sourceSets.test.outputruntimeClasspath += sourceSets.main.output + sourceSets.test.output}apiTest {compileClasspath += sourceSets.main.output + sourceSets.test.outputruntimeClasspath += sourceSets.main.output + sourceSets.test.output}}
到此,3種類型的測試可以分別編寫在以下目錄:
單元測試:src/test/java
組件測試:src/componentTest/java
API測試:src/apiTest/java
需要注意的是,這里的API測試更多強調的是對業務功能的測試,有些項目中可能還會存在契約測試和安全測試等,雖然從技術上講都是對API的訪問,但是這些測試都是單獨的關注點,因此建議分開對待。
值得一提的是,由于組件測試和API測試需要啟動程序,也即需要準備好本地數據庫,我們采用了Gradle的docker-compose插件(或者jib插件),該插件會在運行測試之前自動運行Docker容器(比如MySQL):
apply plugin: 'docker-compose'dockerCompose {useComposeFiles = ['docker/mysql/docker-compose.yml']}bootRun.dependsOn composeUpcomponentTest.dependsOn composeUpapiTest.dependsOn composeUp
更多的測試分類配置細節,比如JaCoCo測試覆蓋率配置等,請參考本文的示例項目代碼。對Gradle不熟悉的讀者可以參考:
https://www.cnblogs.com/CloudTeng/p/3417762.html
在日志處理中,除了完成基本配置外,還有2個需要考慮的點:
1、在日志中加入請求標識,便于鏈路追蹤。在處理一個請求的過程中有時會輸出多條日志,如果每條日志都共享統一的請求ID,那么在日志追蹤時會更加方便。此時,可以使用Logback原生提供的MDC(Mapped Diagnostic Context)功能,創建一個RequestIdMdcFilter:
protected void doFilterInternal(HttpServletRequest request,HttpServletResponse response,FilterChain filterChain) throws ServletException, IOException { //request id in header may come from Gateway, eg. Nginx String headerRequestId = request.getHeader(HEADER_X_REQUEST_ID); MDC.put(REQUEST_ID, isNullOrEmpty(headerRequestId) ? newUuid() : headerRequestId); try { filterChain.doFilter(request, response); } finally { clearMdc(); } }
2、集中式日志管理,在多節點部署的場景下,各個節點的日志是分散的,為此可以引入諸如ELK之類的工具將日志統一輸出到ElasticSearch中。本文的示例項目使用了RedisAppender將日志輸出到Logstash:
<appender name="REDIS" class="com.cwbase.logback.RedisAppender"> <tags>ecommerce-order-backend-${ACTIVE_PROFILE}</tags> <host>elk.yourdomain.com</host> <port>6379</port> <password>whatever</password> <key>ecommerce-ordder-log</key> <mdc>true</mdc> <type>redis</type></appender>
當然,統一日志的方案還有很多,比如Splunk和Graylog等。
在設計異常處理的框架時,需要考慮以下幾點:
向客戶端提供格式統一的異常返回
異常信息中應該包含足夠多的上下文信息,最好是結構化的數據以便于客戶端解析
不同類型的異常應該包含唯一標識,以便客戶端精確識別
異常處理通常有兩種形式,一種是層級式的,即每種具體的異常都對應了一個異常類,這些類最終繼承自某個父異常;另一種是單一式的,即整個程序中只有一個異常類,再以一個字段來區分不同的異常場景。
層級式異常的好處是能夠顯式化異常含義,但是如果層級設計不好可能導致整個程序中充斥著大量的異常類;單一式的好處是簡單,而其缺點在于表意性不夠。
本文的示例項目使用了層級式異常,所有異常都繼承自一個AppException:
public abstract class AppException extends RuntimeException { private final ErrorCode code; private final Map<String, Object> data = newHashMap();}
這里,ErrorCode枚舉中包含了異常的唯一標識、HTTP狀態碼以及錯誤信息;而data字段表示各個異常的上下文信息。
在示例系統中,在沒有找到訂單時拋出異常:
public class OrderNotFoundException extends AppException { public OrderNotFoundException(OrderId orderId) { super(ErrorCode.ORDER_NOT_FOUND, ImmutableMap.of("orderId", orderId.toString())); }}
在返回異常給客戶端時,通過一個ErrorDetail類來統一異常格式:
public final class ErrorDetail { private final ErrorCode code; private final int status; private final String message; private final String path; private final Instant timestamp; private final Map<String, Object> data = newHashMap();}
最終返回客戶端的數據為:
{ requestId: "d008ef46bb4f4cf19c9081ad50df33bd", error: { code: "ORDER_NOT_FOUND", status: 404, message: "沒有找到訂單", path: "/order", timestamp: 1555031270087, data: { orderId: "123456789" } }}
可以看到,ORDER_NOT_FOUND與data中的數據結構是一一對應的,也即對于客戶端來講,如果發現了ORDER_NOT_FOUND,那么便可確定data中一定存在orderId字段,進而完成精確的結構化解析。
除了即時完成客戶端的請求外,系統中通常會有一些定時性的例行任務,比如定期地向用戶發送郵件或者運行數據報表等;另外,有時從設計上我們會對請求進行異步化處理。此時,我們需要搭建后臺任務相關基礎設施。Spring原生提供了任務處理(TaskExecutor)和任務計劃(TaskSchedulor)機制;而在分布式場景下,還需要引入分布式鎖來解決并發沖突,為此我們引入一個輕量級的分布式鎖框架ShedLock。
啟用Spring任務配置如下:
@Configuration@EnableAsync@EnableSchedulingpublic class SchedulingConfiguration implements SchedulingConfigurer {@Overridepublic void configureTasks(ScheduledTaskRegistrar taskRegistrar) {taskRegistrar.setScheduler(newScheduledThreadPool(10));}@Bean(destroyMethod = "shutdown")@Primarypublic TaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(2);executor.setMaxPoolSize(5);executor.setQueueCapacity(10);executor.setTaskDecorator(new LogbackMdcTaskDecorator());executor.initialize();return executor;}}
然后配置Shedlock:
@Configuration@EnableSchedulerLock(defaultLockAtMostFor = "PT30S")public class DistributedLockConfiguration {@Beanpublic LockProvider lockProvider(DataSource dataSource) {return new JdbcTemplateLockProvider(dataSource);}@Beanpublic DistributedLockExecutor distributedLockExecutor(LockProvider lockProvider) {return new DistributedLockExecutor(lockProvider);}}
實現后臺任務處理:
@Scheduled(cron = "0 0/1 * * * ?")@SchedulerLock(name = "scheduledTask", lockAtMostFor = THIRTY_MIN, lockAtLeastFor = ONE_MIN)public void run() {logger.info("Run scheduled task.");}為了支持代碼直接調用分布式鎖,基于Shedlock的LockProvider創建DistributedLockExecutor:public class DistributedLockExecutor {private final LockProvider lockProvider;public DistributedLockExecutor(LockProvider lockProvider) {this.lockProvider = lockProvider;}public <T> T executeWithLock(Supplier<T> supplier, LockConfiguration configuration) {Optional<SimpleLock> lock = lockProvider.lock(configuration);if (!lock.isPresent()) {throw new LockAlreadyOccupiedException(configuration.getName());}try {return supplier.get();} finally {lock.get().unlock();}}}
使用時在代碼中直接調用:
public String doBusiness() { return distributedLockExecutor.executeWithLock(() -> "Hello World.", new LockConfiguration("key", Instant.now().plusSeconds(60))); }
本文的示例項目使用了基于JDBC的分布式鎖,事實上任何提供原子操作的機制都可用于分布式鎖,Shedlock還提供基于Redis、ZooKeeper和Hazelcast等的分布式鎖實現機制。
除了Checkstyle統一代碼格式之外,項目中有些通用的公共的編碼實踐方式也需要在整個開發團隊中進行統一,包括但不限于以下方面:
客戶端的請求數據類統一使用相同后綴,比如Command
返回給客戶端的數據統一使用相同后綴,比如Represetation
統一對請求處理的流程框架,比如采用傳統的3層架構或者DDD戰術模式
提供一致的異常返回(請參考“異常處理”小節)
提供統一的分頁結構類
明確測試分類以及統一的測試基礎類(請參考“自動化測試分類”小節)
靜態代碼檢查主要包含以下Gradle插件,具體配置請參考本文示例代碼:
Checkstyle:用于檢查代碼格式,規范編碼風格
Spotbugs:Findbugs的繼承者
Dependency check:OWASP提供的Java類庫安全性檢查
Sonar:用于代碼持續改進的跟蹤
健康檢查主要用于以下場景:
我們希望初步檢查程序是否運行正常
有些負載均衡軟件會通過一個健康檢查URL判斷節點的可達性
此時,可以實現一個簡單的API接口,該接口不受權限管控,可以公開訪問。如果該接口返回HTTP的200狀態碼,便可初步認為程序運行正常。此外,我們還可以在該API中加入一些額外的信息,比如提交版本號、構建時間、部署時間等。
啟動本文的示例項目:
./run.sh
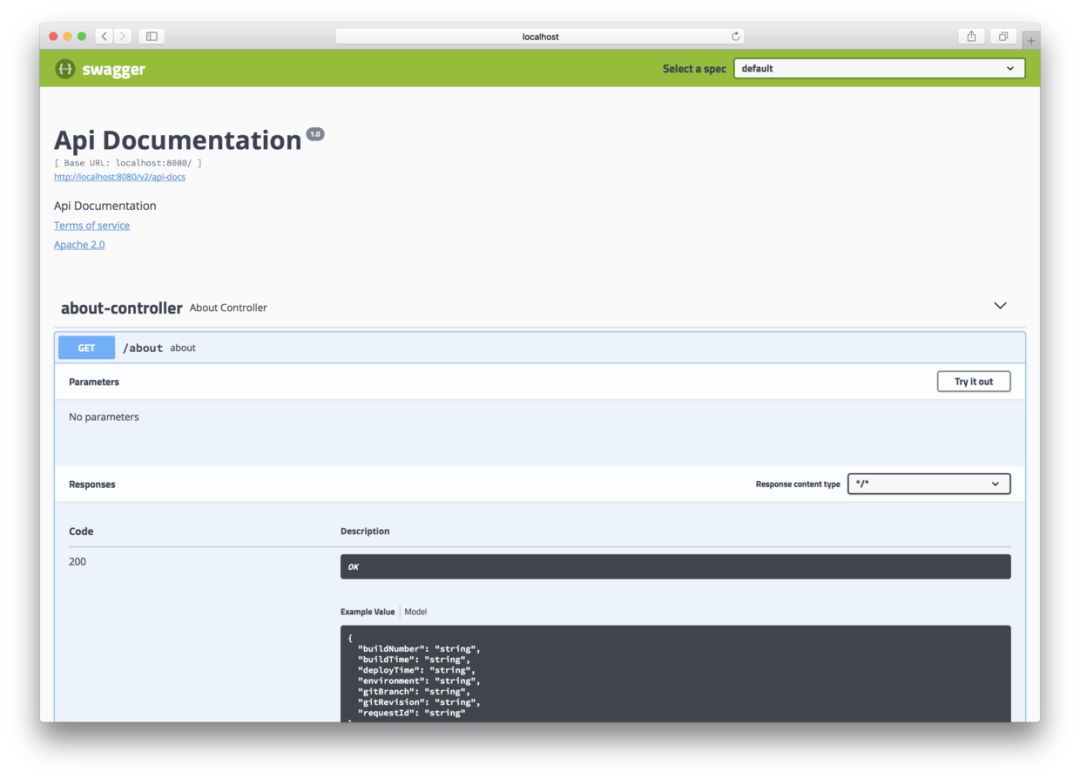
然后訪問健康檢查API:http://localhost:8080/about,結果如下:
{ requestId: "698c8d29add54e24a3d435e2c749ea00", buildNumber: "unknown", buildTime: "unknown", deployTime: "2019-04-11T13:05:46.901+08:00[Asia/Shanghai]", gitRevision: "unknown", gitBranch: "unknown", environment: "[local]"}
以上接口在示例項目中用了一個簡單的Controller實現,事實上Spring Boot的Acuator框架也能夠提供相似的功能。
軟件文檔的難點不在于寫,而在于維護。多少次,當我對照著項目文檔一步一步往下走時,總得不到正確的結果,問了同事之后得到回復“哦,那個已經過時了”。本文示例項目所采用的Swagger在一定程度上降低了API維護的成本,因為Swagger能自動識別代碼中的方法參數、返回對象和URL等信息,然后自動地實時地創建出API文檔。
配置Swagger如下:
@Configuration@EnableSwagger2@Profile(value = {"local", "dev"})public class SwaggerConfiguration {@Beanpublic Docket api() {return new Docket(SWAGGER_2).select().apis(basePackage("com.ecommerce.order")).paths(any()).build();}}
在傳統的開發模式中,數據庫由專門的運維團隊或者DBA來維護,要對數據庫進行修改需要向DBA申請,告之遷移內容,最后由DBA負責數據庫變更實施。在持續交付和DevOps運動中,這些工作逐步提前到開發過程,當然并不是說不需要DBA了,而是這些工作可以由開發者和運維人員一同完成。
另外,在微服務場景下,數據庫被包含在單個服務的邊界之內,因此基于內聚性原則(咦,這好像是本文第三次提到內聚原則了,可見其在軟件開發中的重要性),數據庫的變更最好也與項目代碼一道維護在代碼庫中。
本文的示例項目采用了Flyway作為數據庫遷移工具,加入了Flyway依賴后,在src/main/sources/db/migration目錄下創建遷移腳本文件即可:
resources/├── db│ └── migration│ ├── V1__init.sql│ └── V2__create_product_table.sql
遷移腳本的命名需要遵循一定的規則以保證腳本執行順序,另外遷移文件生效之后不要任意修改,因為Flyway會檢查文件的checksum,如果checksum不一致將導致遷移失敗。
在軟件的開發流程中,我們需要將軟件部署到多個環境,經過多輪驗證后才能最終上線。在不同的階段中,軟件的運行態可能是不一樣的,比如本地開發時可能將所依賴的第三方系統stub掉;持續集成構建時可能使用的是測試用的內存數據庫等等。為此,本文的示例項目推薦采用以下環境:
local:用于開發者本地開發
ci:用于持續集成
dev:用于前端開發聯調
qa:用于測試人員
uat:類生產環境,用于功能驗收(有時也稱為staging環境)
prod:正式的生產環境
在前后端分離的系統中,前端單獨部署,有時連域名都和后端不同,此時需要進行跨域處理。傳統的做法可以通過JSONP,但這是一種比較“trick”的做法,當前更通用的實踐是采用CORS機制,在Spring Boot項目中,啟用CORS配置如下:
@Configurationpublic class CorsConfiguration { @Bean public WebMvcConfigurer corsConfigurer() { return new WebMvcConfigurer() { @Override public void addCorsMappings(CorsRegistry registry) { registry.addMapping("/**"); } }; }}
@EnableWebSecuritypublic class WebSecurityConfig extends WebSecurityConfigurerAdapter {@Overrideprotected void configure(HttpSecurity http) throws Exception {http// by default uses a Bean by the name of corsConfigurationSource.cors().and()...}@BeanCorsConfigurationSource corsConfigurationSource() {CorsConfiguration configuration = new CorsConfiguration();configuration.setAllowedOrigins(Arrays.asList("https://example.com"));configuration.setAllowedMethods(Arrays.asList("GET","POST"));UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();source.registerCorsConfiguration("/**", configuration);return source;}}
這里列出一些比較常見的第三方庫,開發者們可以根據項目所需引入:
Guava:來自Google的常用類庫
Apache Commons:來自Apache的常用類庫
Mockito:主要用于單元測試的mock
DBUnit:測試中管理數據庫測試數據
Rest Assured:用于Rest API測試
Jackson 2:Json數據的序列化和反序列化
jjwt:Jwt token認證
Lombok:自動生成常見Java代碼,比如equals()方法,getter和setter等;
Feign:聲明式Rest客戶端
Tika:用于準確檢測文件類型
itext:生成Pdf文件等
zxing:生成二維碼
Xstream:比Jaxb更輕量級的XML處理庫
最后,需要提醒的是,本文提到的實踐方式只是一個參考,一方面依然存在考慮不周的地方,另一方面示例項目中用到的技術工具還存在其他替代方案,請根據自己項目的實際情況進行取舍。
看完上述內容,你們掌握SpringBoot項目的流程是怎樣的的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





