溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在本地緩存中,最常用的就是OSCache和谷歌的Guava Cache。其中OSCache在07年就停止維護了,但它仍然被廣泛的使用。谷歌的Guava Cache也是一個非常優秀的本地緩存,使用起來非常靈活,功能也十分強大,可以說是當前本地緩存中最優秀的緩存框架之一。之前我們分析了OSCache的部分源碼,本篇就通過Guava Cache的部分源碼,來分析一下Guava Cache的實現原理。
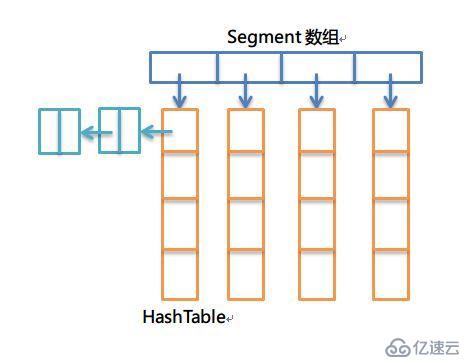
在分析之前,先弄清數據結構的使用。之前的文章提到,OSCache使用了一個擴展的HashTable,作為緩存的數據結構,由于在get操作上,沒有使用同步的方式,通過引入一個更新狀態數據結構,來控制并發訪問的安全。Guava Cache也是使用一個擴展的HashTable作為其緩存數據結構,然而,在實現上,和OSCache是完全不同的。Guava Cache所用的HashTable和ConcurrentHashMap十分相似,通過引入一個Segment數組,對HashTable進行分段,通過分離鎖、final以及volatile的配合,實現了并發環境下的線程安全,同時,性能也非常高(每個Segment段的操作互不影響,即使寫操作,只要在不同的Segment上,也完全可以并發的執行)。具體的原理,可以參考ConcurrentHashMap的實現,這里就不進行具體的剖析了。
數據結構核心部分可以通過下面的圖形表示:
CacheBuilder
CacheBuilder集成了創建緩存所需的各種參數。正如官方文檔介紹的:CacheBuilder將創建一個LoadingCache和Cache的實例,該實例可以包含下面任何特性
自動將內容加載到緩存中
LRU淘汰策略
根據上一次訪問時間或寫入時間決定緩存過期
key關鍵字可以采用弱引用(WeakReference)
value值可以采用弱引用(WeakReference)以及軟引用(SoftReference)
緩存移除或回收進行通知
統計緩存訪問性能信息
所有特性都是可選的,創建的緩存可以包含上面所有的特性,也可以都不使用,具有很強的靈活性。
下面是一個簡單的使用例子:
LoadingCache<Key, Graph> graphs = CacheBuilder.newBuilder()
.maximumSize(10000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.removalListener(MY_LISTENER)
.build(
new CacheLoader<Key, Graph>() {
public Graph load(Key key) throws AnyException {
return createExpensiveGraph(key);
}
});}還可以這樣寫:
String spec = "maximumSize=10000,expireAfterWrite=10m";
LoadingCache<Key, Graph> graphs = CacheBuilder.from(spec)
.removalListener(MY_LISTENER)
.build(
new CacheLoader<Key, Graph>() {
public Graph load(Key key) throws AnyException {
return createExpensiveGraph(key);
}
});}說明:上面的例子指定Cache容量最大為10000,并且寫入后經過10分鐘自動過期,并指定了一個緩存移除的消息監聽器,可以在緩存移除的時候,進行指定的操作。
接下來,根據CacheBuilder的源碼進行簡要的分析:
CacheBuilder中一些重要的參數:
//默認容量
private static final int DEFAULT_INITIAL_CAPACITY = 16;
//默認并發程度(segement大小就是通過這個計算)
private static final int DEFAULT_CONCURRENCY_LEVEL = 4;
//默認失效時間
private static final int DEFAULT_EXPIRATION_NANOS = 0;
//默認刷新時間
private static final int DEFAULT_REFRESH_NANOS = 0;
//默認性能計數器
static final Supplier<? extends StatsCounter> NULL_STATS_COUNTER = Suppliers.ofInstance(
new StatsCounter() {
@Override
public void recordHits(int count) {}
@Override
public void recordMisses(int count) {}
@Override
public void recordLoadSuccess(long loadTime) {}
@Override
public void recordLoadException(long loadTime) {}
@Override
public void recordEviction() {}
@Override
public CacheStats snapshot() {
return EMPTY_STATS;
}
});
static final CacheStats EMPTY_STATS = new CacheStats(0, 0, 0, 0, 0, 0);
static final Supplier<StatsCounter> CACHE_STATS_COUNTER =
new Supplier<StatsCounter>() {
@Override
public StatsCounter get() {
return new SimpleStatsCounter();
}
};
//移除事件監聽器(默認為空)
enum NullListener implements RemovalListener<Object, Object> {
INSTANCE;
@Override
public void onRemoval(RemovalNotification<Object, Object> notification) {}
}
enum OneWeigher implements Weigher<Object, Object> {
INSTANCE;
@Override
public int weigh(Object key, Object value) {
return 1;
}
}
static final Ticker NULL_TICKER = new Ticker() {
@Override
public long read() {
return 0;
}
};
static final int UNSET_INT = -1;
boolean strictParsing = true;
//初始容量
int initialCapacity = UNSET_INT;
//并發程度,Segment數組的大小通過這個進行計算,后面會進行介紹
int concurrencyLevel = UNSET_INT;
//緩存最大容量
long maximumSize = UNSET_INT;
//
long maximumWeight = UNSET_INT;
Weigher<? super K, ? super V> weigher;
//引用類型(默認都為強引用)
Strength keyStrength;
Strength valueStrength;
//寫入后過期時間
long expireAfterWriteNanos = UNSET_INT;
//讀取后過期時間
long expireAfterAccessNanos = UNSET_INT;
//刷新時間
long refreshNanos = UNSET_INT;
//判斷是否相同的方法(因為有引用類型可以為弱引用和軟引用)
Equivalence<Object> keyEquivalence;
Equivalence<Object> valueEquivalence;
RemovalListener<? super K, ? super V> removalListener;
Ticker ticker;
Supplier<? extends StatsCounter> statsCounterSupplier = NULL_STATS_COUNTER;說明:上面就是創建緩存涉及的參數,我們可以人工指定,也可以使用默認值。我們可以看看NULL_STATS_COUNTER、NullListener的定義,其對各個方法的實現進行了重寫,函數內容直接為空,這也是為了不影響性能的做法。CacheBuilder將創建緩存方法進行了封裝,是值得我們借鑒的地方。
Guava Cache對于緩存的key和value提供了多種引用類型,默認情況下,兩者都是強引用類型。關于引用類型的枚舉定義如下:
STRONG {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new StrongValueReference<K, V>(value)
: new WeightedStrongValueReference<K, V>(value, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.equals();
}
},
SOFT {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new SoftValueReference<K, V>(segment.valueReferenceQueue, value, entry)
: new WeightedSoftValueReference<K, V>(
segment.valueReferenceQueue, value, entry, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.identity();
}
},
WEAK {
@Override
<K, V> ValueReference<K, V> referenceValue(
Segment<K, V> segment, ReferenceEntry<K, V> entry, V value, int weight) {
return (weight == 1)
? new WeakValueReference<K, V>(segment.valueReferenceQueue, value, entry)
: new WeightedWeakValueReference<K, V>(
segment.valueReferenceQueue, value, entry, weight);
}
@Override
Equivalence<Object> defaultEquivalence() {
return Equivalence.identity();
}
};值得注意的是,Equivalence<Object> defaultEquivalence()是不同的,這也正對應了上面Equivalence<Object> keyEquivalence;和Equivalence<Object> valueEquivalence;兩個參數。對于強引用來說,直接使用equal進行判斷對象是否相同,但對于弱引用和軟引用,采用的identity方法。關于這里的的細節,會有單獨章節進行討論。本章節以STRONG進行分析。
LocalCache
這一部分結合文章開頭給出的數據結構圖解,就很容易理解了。
首先查看LocalCache下的成員變量:
static final int MAXIMUM_CAPACITY = 1 << 30:緩存最大容量,該數值必須是2的冪,同時小于這個最大值2^30
static final int MAX_SEGMENTS = 1 << 16:Segment數組最大容量
static final int CONTAINS_VALUE_RETRIES = 3:containsValue方法的重試次數
static final int DRAIN_THRESHOLD = 0x3F(63):Number of cache access operations that can be buffered per segment before the cache's recency ordering information is updated. This is used to avoid lock contention by recording a memento of reads and delaying a lock acquisition until the threshold is crossed or a mutation occurs.
static final int DRAIN_MAX = 16:一次清理操作中,最大移除的entry數量
final int segmentMask:定位segment
final int segmentShift:定位segment,同時讓entry分布均勻,盡量平均分布在每個segment[i]中
final Segment<K, V>[] segments:segment數組,每個元素下都是一個HashTable
final int concurrencyLevel:并發程度,用來計算segment數組的大小。segment數組的大小正決定了并發的程度
final Equivalence<Object> keyEquivalence:key比較方式
final Equivalence<Object> valueEquivalence:value比較方式
final Strength keyStrength:key引用類型
final Strength valueStrength:value引用類型
final long maxWeight:最大權重
final Weigher<K, V> weigher:計算每個entry權重的接口
final long expireAfterAccessNanos:一個entry訪問后多久過期
final long expireAfterWriteNanos:一個entry寫入后多久過期
final long refreshNanos:一個entry寫入多久后進行刷新
final Queue<RemovalNotification<K, V>> removalNotificationQueue:移除監聽器使用隊列
final RemovalListener<K, V> removalListener:entry過期移除或者gc回收(弱引用和軟引用)將會通知的監聽器
final Ticker ticker:統計時間
final EntryFactory entryFactory:創建entry的工廠
final StatsCounter globalStatsCounter:全局緩存性能統計器(命中、未命中、put成功、失敗次數等)
final CacheLoader<? super K, V> defaultLoader:默認的緩存加載器
LocalCache構造入口如下:
LocalCache(CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader)
其中,builder就是通過CacheBuilder創建的實例,這個在上面的小節中已經講解了,下面看一下LocalCache初始化部分的代碼:
LocalCache(
CacheBuilder<? super K, ? super V> builder, @Nullable CacheLoader<? super K, V> loader) {
//并發程度,根據我們傳的參數和默認最大值中選取小者。
//如果沒有指定該參數的情況下,CacheBuilder將其置為UNSET_INT即為-1
//getConcurrencyLevel方法獲取時,如果為-1就返回默認值4
//否則返回用戶傳入的參數
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
//鍵值的引用類型,沒有指定的話,默認為強引用類型
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
//判斷相同的方法,強引用類型就是Equivalence.equals()
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
maxWeight = builder.getMaximumWeight();
weigher = builder.getWeigher();
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
refreshNanos = builder.getRefreshNanos();
//移除消息監聽器
removalListener = builder.getRemovalListener();
//如果我們指定了移除消息監聽器的話,會創建一個隊列,臨時保存移除的內容
removalNotificationQueue = (removalListener == NullListener.INSTANCE)
? LocalCache.<RemovalNotification<K, V>>discardingQueue()
: new ConcurrentLinkedQueue<RemovalNotification<K, V>>();
ticker = builder.getTicker(recordsTime());
//創建新的緩存內容(entry)的工廠,會根據引用類型選擇對應的工廠
entryFactory = EntryFactory.getFactory(keyStrength, usesAccessEntries(), usesWriteEntries());
globalStatsCounter = builder.getStatsCounterSupplier().get();
defaultLoader = loader;
//初始化緩存容量,默認為16
int initialCapacity = Math.min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
if (evictsBySize() && !customWeigher()) {
initialCapacity = Math.min(initialCapacity, (int) maxWeight);
}
// Find the lowest power-of-two segmentCount that exceeds concurrencyLevel, unless
// maximumSize/Weight is specified in which case ensure that each segment gets at least 10
// entries. The special casing for size-based eviction is only necessary because that eviction
// happens per segment instead of globally, so too many segments compared to the maximum size
// will result in random eviction behavior.
int segmentShift = 0;
int segmentCount = 1;
//根據并發程度來計算segement數組的大小(大于等于concurrencyLevel的最小的2的冪,這里即為4)
while (segmentCount < concurrencyLevel
&& (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
//這里的segmentShift和segmentMask用來打散entry,讓緩存內容盡量均勻分布在每個segment下
this.segmentShift = 32 - segmentShift;
segmentMask = segmentCount - 1;
//這里進行初始化segment數組,大小即為4
this.segments = newSegmentArray(segmentCount);
//每個segment的容量,總容量/segment的大小,向上取整,這里就是16/4=4
int segmentCapacity = initialCapacity / segmentCount;
if (segmentCapacity * segmentCount < initialCapacity) {
++segmentCapacity;
}
//這里計算每個Segment[i]下的table的大小
int segmentSize = 1;
//SegmentSize為小于segmentCapacity的最大的2的冪,這里為4
while (segmentSize < segmentCapacity) {
segmentSize <<= 1;
}
//初始化每個segment[i]
//注:根據權重的方法使用較少,這里走else分支
if (evictsBySize()) {
// Ensure sum of segment max weights = overall max weights
long maxSegmentWeight = maxWeight / segmentCount + 1;
long remainder = maxWeight % segmentCount;
for (int i = 0; i < this.segments.length; ++i) {
if (i == remainder) {
maxSegmentWeight--;
}
this.segments[i] =
createSegment(segmentSize, maxSegmentWeight, builder.getStatsCounterSupplier().get());
}
} else {
for (int i = 0; i < this.segments.length; ++i) {
this.segments[i] =
createSegment(segmentSize, UNSET_INT, builder.getStatsCounterSupplier().get());
}
}
}到這里緩存就初始化完成了。
下面我們看一下Segment的定義,實現上跟ConcurrentHashMap的原理很像,因此不作詳細介紹。具體可以看看ConcurrentHashMap的實現源碼。
static class Segment<K, V> extends ReentrantLock {
final LocalCache<K, V> map;
/**
* The number of live elements in this segment's region.
*/
volatile int count;
/**
* The weight of the live elements in this segment's region.
*/
@GuardedBy("this")
long totalWeight;
/**
* Number of updates that alter the size of the table. This is used during bulk-read methods to
* make sure they see a consistent snapshot: If modCounts change during a traversal of segments
* loading size or checking containsValue, then we might have an inconsistent view of state
* so (usually) must retry.
*/
int modCount;
/**
* The table is expanded when its size exceeds this threshold. (The value of this field is
* always {@code (int) (capacity * 0.75)}.)
*/
int threshold;
/**
* The per-segment table.
*/
volatile AtomicReferenceArray<ReferenceEntry<K, V>> table;
/**
* The maximum weight of this segment. UNSET_INT if there is no maximum.
*/
final long maxSegmentWeight;
/**
* The key reference queue contains entries whose keys have been garbage collected, and which
* need to be cleaned up internally.
*/
final ReferenceQueue<K> keyReferenceQueue;
/**
* The value reference queue contains value references whose values have been garbage collected,
* and which need to be cleaned up internally.
*/
final ReferenceQueue<V> valueReferenceQueue;
/**
* The recency queue is used to record which entries were accessed for updating the access
* list's ordering. It is drained as a batch operation when either the DRAIN_THRESHOLD is
* crossed or a write occurs on the segment.
*/
final Queue<ReferenceEntry<K, V>> recencyQueue;
/**
* A counter of the number of reads since the last write, used to drain queues on a small
* fraction of read operations.
*/
final AtomicInteger readCount = new AtomicInteger();
/**
* A queue of elements currently in the map, ordered by write time. Elements are added to the
* tail of the queue on write.
*/
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> writeQueue;
/**
* A queue of elements currently in the map, ordered by access time. Elements are added to the
* tail of the queue on access (note that writes count as accesses).
*/
@GuardedBy("this")
final Queue<ReferenceEntry<K, V>> accessQueue;
/** Accumulates cache statistics. */
final StatsCounter statsCounter;
}注意到其中有幾個隊列,keyReferenceQueue和valueReferenceQueue,在弱引用或軟引用情況下gc回收的內容會放入這兩個隊列,accessQueue,用來進行LRU替換算法,recencyQueue記錄哪些entry被訪問,用于accessQueue的更新。
各種緩存的核心操作無外乎put/get/remove等。下面我們先拋開統計、LRU等,重點關注Guava Cache的put、get方法的實現。
下面是get方法的源碼:
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
//這里對哈希再哈希(Wang/Jenkins方法,為了進一步降低沖突)的細節暫時不講,重點關注后面的get方法
int hash = hash(checkNotNull(key));
//根據hash找到對應的那個segment
return segmentFor(hash).get(key, hash, loader);
}
Segment<K, V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
//key和loader不能為null(空指針異常)
checkNotNull(key);
checkNotNull(loader);
try {
//count保存的是該sengment中緩存的數量,如果為0,就直接去載入
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
//e != null說明緩存中已存在
if (e != null) {
long now = map.ticker.read();
//getLiveValue在entry無效、過期、正在載入都會返回null,如果返回不為空,就是正常命中
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
//性能統計
statsCounter.recordHits(1);
//根據用戶是否設置距離上次訪問或者寫入一段時間會過期,進行刷新或者直接返回
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
//如果正在加載中,等待加載完成獲取
return waitForLoadingValue(e, key, valueReference);
}
}
}
//如果不存在或者過期,就通過loader方法進行加載
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
//清理。通常情況下,清理操作會伴隨寫入進行,但是如果很久不寫入的話,就需要讀線程進行完成
//那么這個“很久”是多久呢?還記得前面我們設置了一個參數DRAIN_THRESHOLD=63吧
//而我們的判斷條件就是if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0)
//條件成立,才會執行清理,也就是說,連續讀取64次就會執行一次清理操作
//具體是如何清理的,后面再介紹,這里僅關注核心流程
postReadCleanup();
}
}說明:一般緩存的get方法會去查找指定的key對應的value,如果不存在就直接返回null或者拋出異常,如OSCache就是拋出一個緩存需要刷新的異常,讓用戶進行put操作,Guava Cache這樣的處理很有意思,在get獲取不到或者過期的話,會通過我們提供的load方法將entry主動加載到緩存中來。
下面是get方法的核心源碼,大部分說明都在注釋中:
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader)
throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
boolean createNewEntry = true;
//加鎖
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
//當前segment下的HashTable
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
//這里也是為什么table的大小要為2的冪(最后index范圍剛好在0-table.length()-1)
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
//在鏈表上查找
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
//如果正在載入中,就不需要創建,只需要等待載入完成讀取即可
if (valueReference.isLoading()) {
createNewEntry = false;
} else {
V value = valueReference.get();
// 被gc回收(在弱引用和軟引用的情況下會發生)
if (value == null) {
enqueueNotification(entryKey, hash, valueReference, RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// 過期
enqueueNotification(entryKey, hash, valueReference, RemovalCause.EXPIRED);
} else {
//存在并且沒有過期,更新訪問隊列并記錄命中信息,返回value
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// 對于被gc回收和過期的情況,從寫隊列和訪問隊列中移除
// 因為在后面重新載入后,會再次添加到隊列中
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) {
//先創建一個loadingValueReference,表示正在載入
loadingValueReference = new LoadingValueReference<K, V>();
if (e == null) {
//如果當前鏈表為空,先創建一個頭結點
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
//解鎖
unlock();
//執行清理
postWriteCleanup();
}
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
//異步加載
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
//記錄未命中
statsCounter.recordMisses(1);
}
} else {
// 等待加載進來然后讀取即可
return waitForLoadingValue(e, key, valueReference);
}
}下面是異步載入的代碼:
V loadSync(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
CacheLoader<? super K, V> loader) throws ExecutionException {
//這里通過我們重寫的load方法,根據key,將value載入
ListenableFuture<V> loadingFuture = loadingValueReference.loadFuture(key, loader);
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
}
//等待載入,并記錄載入成功或失敗
V getAndRecordStats(K key, int hash, LoadingValueReference<K, V> loadingValueReference,
ListenableFuture<V> newValue) throws ExecutionException {
V value = null;
try {
value = getUninterruptibly(newValue);
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
//性能統計信息記錄載入成功
statsCounter.recordLoadSuccess(loadingValueReference.elapsedNanos());
//這個方法才是真正的將緩存內容加載完成(當前還是loadingValueReference,表示isLoading)
storeLoadedValue(key, hash, loadingValueReference, value);
return value;
} finally {
if (value == null) {
statsCounter.recordLoadException(loadingValueReference.elapsedNanos());
removeLoadingValue(key, hash, loadingValueReference);
}
}
}
boolean storeLoadedValue(K key, int hash, LoadingValueReference<K, V> oldValueReference,
V newValue) {
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
//找到
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference<K, V> valueReference = e.getValueReference();
V entryValue = valueReference.get();
// replace the old LoadingValueReference if it's live, otherwise
// perform a putIfAbsent
if (oldValueReference == valueReference
|| (entryValue == null && valueReference != UNSET)) {
++modCount;
if (oldValueReference.isActive()) {
RemovalCause cause =
(entryValue == null) ? RemovalCause.COLLECTED : RemovalCause.REPLACED;
enqueueNotification(key, hash, oldValueReference, cause);
newCount--;
}
//LoadingValueReference變成對應引用類型的ValueReference,并進行賦值
setValue(e, key, newValue, now);
//volatile寫入
this.count = newCount; // write-volatile
evictEntries();
return true;
}
// the loaded value was already clobbered
valueReference = new WeightedStrongValueReference<K, V>(newValue, 0);
enqueueNotification(key, hash, valueReference, RemovalCause.REPLACED);
return false;
}
}
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, newValue, now);
table.set(index, newEntry);
this.count = newCount; // write-volatile
evictEntries();
return true;
} finally {
unlock();
postWriteCleanup();
}
}至此,Guava Cache從get以及put的核心部分已經分析完了。關于其余的部分細節以及各個數據結構的具體實現,可以好好研讀源碼,本文主要理通總體流程,分析其實現原理。
OSCache和Guava Cache在實現上有很大不同,但二者都是非常優秀的本地緩存框架,認真學習它們的實現原理和源碼,對開發是大有裨益的。我們對其進行一下簡要的對比:
OSCache和Guava Cache底層都是HashTable,但是二者又是不同的。OSCache對原有HashTable進行了擴展,在get方法上是沒有加鎖的,而是通過其他措施進行并發安全控制,因此讀性能大幅度提高;Guava Cache也是對HashTable進行了擴展,原理類似于ConcurrentHashMap,通過分離鎖等實現線程安全的同時,讀寫性能都大大提高,尤其在寫上,也是可以并發的。
OSCache在get方法時,如果緩存過期或者不存在,會拋出需要刷新的異常,用戶需要通過put方法進行刷新緩存,否則會發生死鎖;而Guava Cache在get的時候,會通過用戶重載的load方法,自動進行加載,十分方便。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





