溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何理解OpenCV及其工程應用,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
OpenCV是一個基于BSD許可(開源)發行的跨平臺的計算機視覺和機器學習軟件庫,可以運行在Linux、Windows、Android和Mac OS操作系統上。它輕量級而且高效——由一系列 C 函數和少量 C++ 類構成,同時提供了Python、Ruby、MATLAB等語言的接口,實現了圖像處理和計算機視覺方面的很多通用算法。
OpenCV在圖像分割、人臉識別、物體識別、動作跟蹤、動作分析、機器視覺等領域都有廣泛的應用。
以下是OpenCV的基本操作及其應用案例。
import cv2
image = cv2.imread("test.jpg") # 讀取操作
cv2.imshow("test", image) # 顯示操作
cv2.waitKey() # 等待按鍵
cv2.imwrite("save.jpg") # 保存操作image = cv2.imread("test.jpg")
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # 轉換到HSV空間
hls = cv2.cvtColor(image, cv2.COLOR_BGR2HLS) # 轉換到HLS空間
lab = cv2.cvtColor(image, cv2.COLOR_BGR2Lab) # 轉換到Lab空間
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 轉換到GRAY空間(灰度圖)
HSV這個模型中顏色的參數分別是:色調(H),飽和度(S),明度(V),該模型常用來做綠幕分割。
在圖像檢測中,可以對樣本進行色彩空間轉換實現數據增強,如將訓練數據直接轉換到HSV空間,或者調整V(明度)通道的大小,改變圖片的明暗,再轉到BGR格式。
image = cv2.imread("test.jpg")
resize = cv2.resize(image, (), fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA) # 長寬縮小到0.5倍在對圖像作平移操作時,需創建2行3列變換矩陣,M矩陣表示水平方向上平移為x,豎直方向上的平移距離為y。
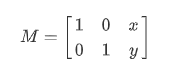
import cv2
import numpy as np
image = cv2.imread("test.jpg")
rows, cols, channels = image.shape
M = np.float32([[1,0,100],[0,1,50]])
res = cv.warpAffine(image, M, (cols, rows))旋轉所需的變換矩陣可以通過函數cv2.getRotationMatrix2D得到。
image = cv2.imread('test.jpg')
rows, cols, channels = image.shape
rotate = cv2.getRotationMatrix2D((rows*0.5, cols*0.5), 45, 1) # 第一個參數:旋轉中心點 第二個參數:旋轉角度 第三個參數:縮放比例
res = cv2.warpAffine(image, rotate, (cols, rows))模糊濾波操作去除圖像中的椒鹽噪聲、提高圖像的對比度、實現銳化處理、提高立體感等。
image = cv2.imread('test.jpg')
blur = cv2.blur(image, (5, 5)) # 均值濾波 第二個參數是卷積核大小
median_blur = cv2.medianBlur(image, 5) # 中值濾波
gaussian_blur = cv2.GussianBlur(image, (5, 5)) # 高斯模糊圖像形態學操作是基于形狀的一系列圖像處理操作的合集,主要是基于集合論基礎上的形態學數學。
形態學有四個基本操作:侵蝕、膨脹、開、閉
膨脹與腐蝕是圖像處理中最常用的形態學操作手段
膨脹就是圖像中的高亮部分進行膨脹,“領域擴張”,效果圖擁有比原圖更大的高亮區域。侵蝕就是原圖中的高亮部分被腐蝕,“領域被蠶食”,效果圖擁有比原圖更小的高亮區域
它們能實現多種多樣的功能,主要如下:
消除噪聲
分割出獨立的圖像元素,在圖像中連接相鄰的元素
尋找圖像中的明顯的極大值區域或極小值區域
求出圖像的梯度
image = cv2.imread("test.jpg")
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3)) # 獲取卷積核
eroded = cv2.erode(image, kernel) # 腐蝕圖像
dilated = cv2.dilate(image, kernel) # 膨脹圖像開運算:先腐蝕后膨脹,用于移除由圖像噪音形成的斑點
閉運算:先膨脹后腐蝕,用來連接被誤分為許多小塊的對象
輪廓查找在圖像檢測領域有很廣泛的應用,比如查找圖像中明顯的色塊、條紋、物體邊緣等等,查找輪廓前先要對圖像進行二值化處理。
# opencv版本大于3 contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 第一個參數:查找的二值圖像 第二個參數:輪廓檢索模式 第三個參數:輪廓近似方法 # 返回值contours為查找到的輪廓列表,hierarhy為輪廓之間的層級關系
查找到輪廓后可以通過drawContours函數繪制出輪廓
cv2.drawContours(temp,contours,-1,(0,255,0),3) # 第一個參數:畫布,可以是原圖 第二個參數:查找到的輪廓 第三個參數:-1表示全畫 第四個參數:顏色 第五個參數:輪廓寬度
游戲畫面因為美術資源缺失、程序bug都會產生各種色塊,常見的有白色、紫色等,怎么通過程序篩選出這類異常畫面,加快測試過程呢?
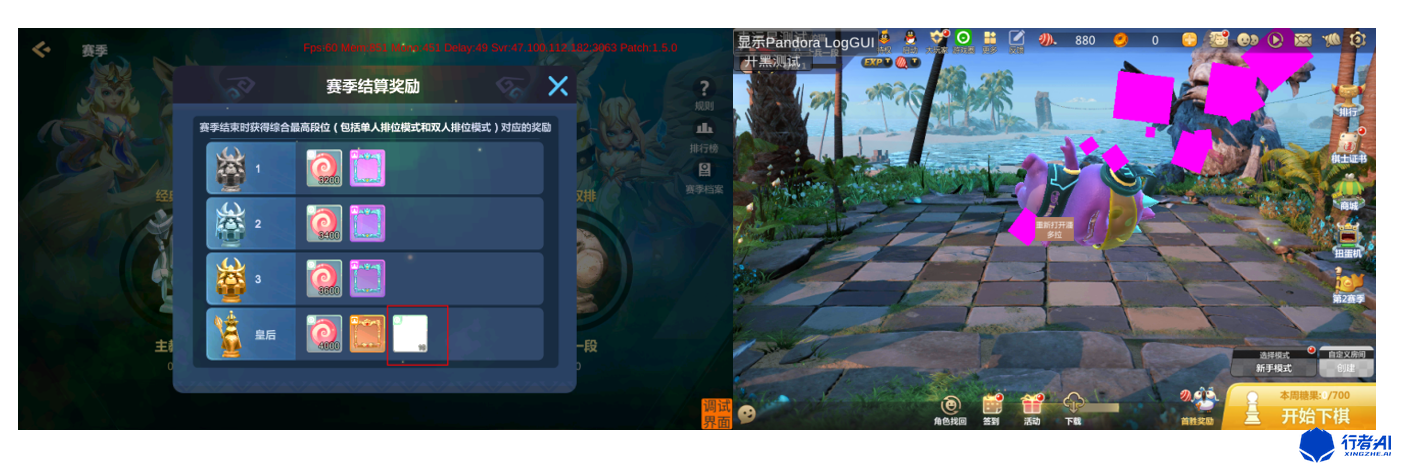
通過觀察,我們發現色塊類的異常都是一些比較規則的矩形圖像,色彩差很明顯,基于這些特點,我們可以很容易的篩選出色塊。
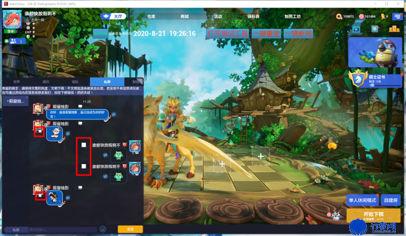
通過RGB通道的數值大小剔除掉其它的顏色,得到黑白二值圖
import cv2
import numpy as np
image = cv2.imread("test.jpg")
b, g, r = cv2.split(self.image) # 分離B、G、R通道
b = np.where(b >= 250, 1, 0) # 找到G通道符合要求的像素點置1,不符合置0
g = np.where(g >= 250, 1, 0) # 找到G通道符合要求的像素點置1,不符合置0
r = np.where(r >= 250, 1, 0) # 找到G通道符合要求的像素點置1,不符合置0
gray = b + g + r # 將三個通道疊加成一個通道
gray = np.where(gray==3, 255, 0).astype(np.uint8) # 像素點為3的即為滿足要求的點設置為白色,不符合設置為黑色
得到的黑白二值圖由于除了色塊外其它圖像位置也有接近色塊顏色的位置被保留了下來,需要剔除
通過查找二值圖輪廓的方法我們可以篩選出分離的小色塊
contours, hierarchy = cv2.findContours(gray, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 獲取輪廓及層級關系
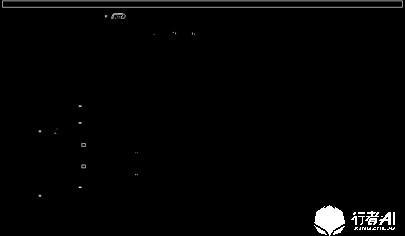
通過輪廓周長和面積剔除掉小色塊,這些色塊很可能就是提取的正常區域顏色較相似的點。
def screen_contour(contour): contour_area = cv2.contourArea(contour) if contour_area > self.area_limit: return True return False pass_contours = [] for contour in contours: if screent_contour(contour): pass_contours.append(contour)
由于色塊更接近于矩形,我們可以通過輪廓計算出色塊的寬和高,色塊的面積可以估算出來,色塊面積與估算面積越接近,說明檢測到的色塊更接近矩形,通過這個方法,可以篩選出大部分不規則的色塊。
def screent_contour(contour): width = np.max(contour[:,:,0]) - np.min(contour[:,:,0]) height = np.max(contour[:,:,1]) - np.min(contour[:,:,1]) block_area = width * heigh contour_area = cv2.contourArea(contour) slimier = cv2.contourArea(contour) / block_area if slimier > self.simliar_rate: return True return False pass_contours = [] for contour in contours: if screent_contour(contour): pass_contours.append(contour)

OpenCV是如何完成以上這些操作的呢?
OpenCV在讀取圖像的時候是將圖像信息轉換成了矩陣,默認矩陣為(height,width,channel),channel對應的是B、G、R通道,每個像素點的顏色由三個通道一起決定,和三元色的關系是一樣的,B、G、R的大小代表的是色彩比例。
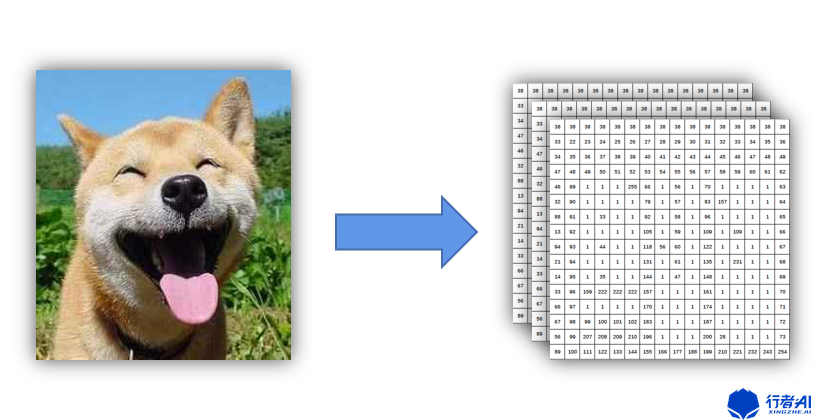
色彩空間的轉換是將圖像數據從一種表示關系變換到了另一種表示關系,比如BGR轉換到HSV顏色空間是將原本的三原色表示法轉換到了色調(H),飽和度(S),明度(V)表示法,每個channel所表示的含義發生了變化。
從信息的角度考慮,攝像機將光照信息采集后轉化成了數字的形式(圖像矩陣),顏色空間的轉換是將圖像數據從一種表示方法變換到另一種表示方法,信息的轉化也會引起信息的丟失或者引入噪聲,比如攝像機在采集光照信息的時候很容易采集到椒鹽噪聲,丟棄光照信息中的一些頻段,清晰度降低等等,在做色彩空間轉換的時候也可能發生信息丟失,比如從彩色圖片轉化到灰度圖。深度學習中的圖像檢測、人臉識別就是要從這些圖像信息中提取我們想要的信息。
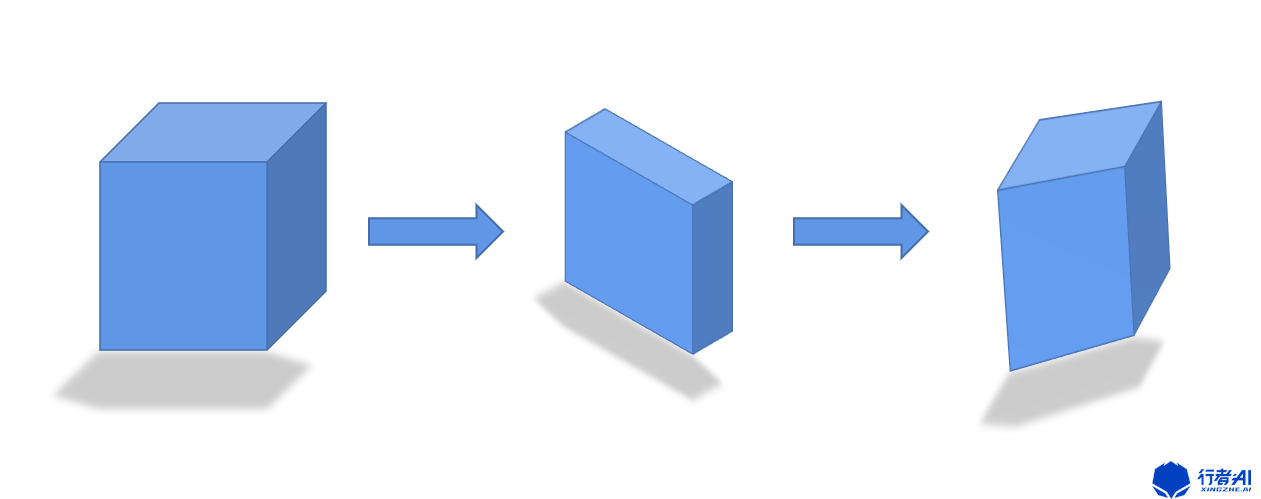
在做圖像幾何變換的時候,我們需要提供變換矩陣,矩陣是怎么完成這些操作的呢?
我們知道矩陣代表的就是一種空間映射,nxm的矩陣(列向量線性無關)代表的是n維空間到m維空間的映射,如上圖所示,第一個立方體所在的空間通過一個3x3的矩陣映射到了第二個立方體所在的空間,立方體的形狀發生了變化,再比如第一個立方體所在的空間通過一個3x2的矩陣映射到了它的影子所在的空間,立方體被壓縮成了一個平面。
立方體可以通過矩陣(實數范圍)映射成球體嗎?因為其代表的是線性變換,所以是不可以的。
我們在處理圖像問題的時候要將信息從一個空間映射到另一個空間,由于問題的復雜性所以線性映射是滿足不了要求的,這也就是為什么在深度學習中需要加入激活函數的原因。
從上一節的分析中我們發現,圖像的處理過程就是從數據中找規律,將圖像信息從一種表示變換到另一種表示,這個工作正好是機器學習的強項,再延申一下,不管是圖像數據、文本數據、音頻數據,要從數據中找規律,都會用到機器學習,從信息的角度考慮,這些問題本質上是沒有區別的。
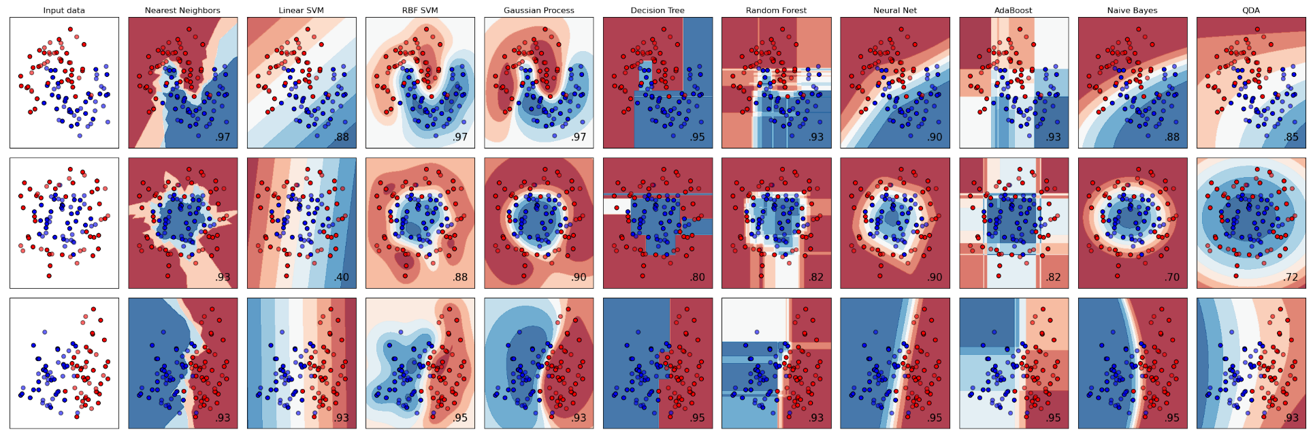
openCV已經集成了很多機器學習算法、如K近鄰(KNN),支持向量機(SVM)、決策樹、隨機森林、Boost、邏輯回歸、ANN等。
下圖是摘自scikit-learn的一張圖片,很形象的展示了不同的機器學習算法是如何對數據進行處理的,從宏觀角度來講就是如何將信息變換到不同的空間。
關于如何理解OpenCV及其工程應用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





