溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“python數據分析的知識點有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
數據預處理一方面是要提高數據的質量,另一方面是要讓 數據更好地適應特定的挖掘技術或工具。統計發現,在數據挖掘的過程中,數據預處理工作量占到了整個過程的60%。
數據清洗主要是刪除原始數據集中的無關數 據、重復數據,平滑噪聲數據,篩選掉與挖掘主 題無關的數據,處理缺失值、異常值等。
處理缺失值的方法可分為3類:刪除記錄、 數據插補和不處理。其中常用的數據插補方法
表4-1常用的插補方法
| 插補方法 | 方法描述 |
|---|---|
| 均值/中位數/眾數插補 | 根據屬性值的類型,用該屬性取值的平均數/中位數/眾數進行插補 |
| 使用固定值 | 將缺失的屬性值用一個常量替換。如廣州一個工廠普通外來務工人員的“基本工資”屬性的空缺值可以用2015年廣州市普通外來務工人員工資標準1895元/月,該 方法就是使用固定值 |
| 最近臨插補 | 在記錄中找到與缺失樣本最接近的樣本的該屬性值插補 |
| 回歸方法 | 對帶有缺失值的變量,根據已有數據和與其有關的其他變量(因變量)的數據建立擬合模型來預測缺失的屬性值 |
| 插值法 | 插值法是利用已知點建立合適的插值函數f(x),未知值由對應點X,求出的函數值f(xi),近似代替 |
如果通過簡單的刪除小部分記錄達到既定的目標,那么刪除含有缺失值的記錄的方法是最有效的。然而,這種方法卻有很大的局限性。它是以減少歷史數據來換取數據的完備,會造成資源的大量浪費,將丟棄了大量隱藏在這些記錄中的信息。尤其在數據集本來就包含很少記錄的情況下,刪除少量記錄可能會嚴重影響到分析結果的客觀性和正確性。一些模型可以將缺失值視作一種特殊的取值,允許直接在含有缺失值的數據上進行建模。
本節重點介紹拉格朗日插值法和牛頓插值法。其他的插值方法還有Hermite插值、分段插值、樣條插值法等。
牛頓插值法也是多項式插值,但采用了另一種構造插值多項式的方法,與拉格朗日插值相比,具有承襲性和易于變動節點的特點。從本質上來說,兩者給出的結果是一樣的(相同 次數、相同系數的多項式),只不過表示的形式不同。因此,在Python的Scipy庫中,只提 供了拉格朗日插值法的函數(因為實現上比較容易),如果需要牛頓插值法,則需要自行編寫
代碼清單4-1,用拉格朗日法進行插補
# -*- coding:utf-8 -*- #拉格朗日插值代碼 import pandas as pd #導入數據分析庫Pandas from scipy.interpolate import lagrange #導入拉格朗日插值函數 inputfile = '../data/catering_sale.xls' #銷量數據路徑 outputfile = '../tmp/sales.xls' #輸出數據路徑 data = pd.read_excel(inputfile) #讀入數據 data[u'銷量'][(data[u'銷量'] < 400) | (data[u'銷量'] > 5000)] = None #過濾異常值,將其變為空值 #自定義列向量插值函數 #s為列向量,n為被插值的位置,k為取前后的數據個數,默認為5 def ployinterp_column(s, n, k=5): y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取數 y = y[y.notnull()] #剔除空值 return lagrange(y.index, list(y))(n) #插值并返回插值結果 #逐個元素判斷是否需要插值 for i in data.columns: for j in range(len(data)): if (data[i].isnull())[j]: #如果為空即插值。 data[i][j] = ployinterp_column(data[i], j) data.to_excel(outputfile) #輸出結果,寫入文件
在數據預處理時,異常值是否剔除,需視具體情況而定,因為有些異常值可能蘊含著有 用的信息。異常值處理常用方法見表4-3。
表4-3異常值處理常用方法
| 異常值處理方法 | 方法描述 |
|---|---|
| 刪除含有異常值的記錄 | 直接將含有異常值的記錄刪除 |
| 視為缺失值 | 將異常值視為缺失值,利用缺失值處理的方法進行處理 |
| 平均值修正 | 可用前后兩個觀測值的平均值修正該異常值 |
| 不處理 | 直接在具有異常值的數據集上進行挖掘建模 |
數據挖掘需要的數據往往分布在不同的數據源中,數據集成就是將多個數據源合并存放 在一個一致的數據存儲(如數據倉庫)中的過程。
在數據集成時,來自多個數據源的現實世界實體的表達形式是不一樣的,有可能不匹配,要考慮實體識別問題和屬性冗余問題,從而將源數據在最低層上加以轉換、提煉和集成。
實體識別是指從不同數據源識別出現實世界的實體,它的任務是統一不同源數據的矛盾之處,常見形式如下。
(1 )同名異義
數據源A中的屬性ID和數據源B中的屬性ID分別描述的是菜品編號和訂單編號,即 描述的是不同的實體。
(2) 異名同義
數據源A中的sales_dt和數據源B中的sales_date都是描述銷售日期的,即A. sales_dt= B. sales_date。
(3 )單位不統一
描述同一個實體分別用的是國際單位和中國傳統的計量單位。
檢測和解決這些沖突就是實體識別的任務。
數據集成往往導致數據冗余,例如,
同一屬性多次出現;
同一屬性命名不一致導致重復。
數據變換主要是對數據進行規范化處理,將數據轉換成“適當的”形式,以適用于挖掘任務及算法的需要。
簡單函數變換是對原始數據進行某些數學函數變換,常用的變換包括平方、開方、取對數、差分運算等。
簡單的函數變換常用來將不具有正態分布的數據變換成具有正態分布的數據。
數據規范化(歸一化)處理是數據挖掘的一項基礎工作。不同評價指標往往具有不同的量綱,數值間的差別可能很大,不進行處理可能會影響到數據分析的結果。為了消除指標之間的量綱和取值范圍差異的影響,需要進行標準化處理,將數據按照比例進行縮放,使之落 入一個特定的區域,便于進行綜合分析。如將工資收入屬性值映射到[-1,1]或者[0,1]內。
數據規范化對于基于距離的挖掘算法尤為重要。
(1)最小-最大規范化
最小-最大規范化也稱為離差標準化,是對原始數據的線性變換,將數值值映射到[0,1]之間。
(2 )零-均值規范化
零-均值規范化也稱標準差標準化,經過處理的數據的均值為0,標準差為1。是當前用得最多的數據標準化方法。
(3) 小數定標規范化
通過移動屬性值的小數位數,將屬性值映射到[-1,1]之間,移動的小數位數取決于屬性值絕對值的最大值。
代碼清單4-2數據規范化代碼
#-*- coding: utf-8 -*- #數據規范化 import pandas as pd import numpy as np datafile = '../data/normalization_data.xls' #參數初始化 data = pd.read_excel(datafile, header = None) #讀取數據 (data - data.min())/(data.max() - data.min()) #最小-最大規范化 (data - data.mean())/data.std() #零-均值規范化 data/10**np.ceil(np.log10(data.abs().max())) #小數定標規范化
一些數據挖掘算法,特別是某些分類算法(如ID3算法、Apriori算法等),要求數據是 分類屬性形式。這樣,常常需要將連續屬性變換成分類屬性,即連續屬性離散化。
離散化的過程
連續屬性的離散化就是在數據的取值范圍內設定若干個離散的劃分點,將取值范圍劃分為一些離散化的區間,最后用不同的符號或整數值代表落在每個子區間中的數據值。所以, 離散化涉及兩個子任務:確定分類數以及如何將連續屬性值映射到這些分類值。
常用的離散化方法
常用的離散化方法有等寬法、等頻法和(一維)聚類。
(1 )等寬法
將屬性的值域分成具有相同寬度的區間,區間的個數由數據本身的特點決定,或者由用 戶指定,類似于制作頻率分布表。
(2 )等頻法
將相同數量的記錄放進每個區間。
這兩種方法簡單,易于操作,但都需要人為地規定劃分區間的個數。同時,等寬法的缺點在于它對離群點比較敏感,傾向于不均勻地把屬性值分布到各個區間。有些區間包含許多數據,而另外一些區間的數據極少,這樣會嚴重損壞建立的決策模型。等頻法雖然避免了上述問題的產生,卻可能將相同的數據值分到不同的區間以滿足每個區間中固定的數據個數。
(3)基于聚類分析的方法
一維聚類的方法包括兩個步驟,首先將連續屬性的值用聚類算法(如K-Means算法)進 行聚類,然后再將聚類得到的簇進行處理,合并到一個簇的連續屬性值并做同一標記。聚類分析的離散化方法也需要用戶指定簇的個數,從而決定產生的區間數。
代碼清單4-3數據離散化
#-*- coding: utf-8 -*- #數據規范化 import pandas as pd datafile = '../data/discretization_data.xls' #參數初始化 data = pd.read_excel(datafile) #讀取數據 data = data[u'肝氣郁結證型系數'].copy() k = 4 d1 = pd.cut(data, k, labels = range(k)) #等寬離散化,各個類比依次命名為0,1,2,3 #等頻率離散化 w = [1.0*i/k for i in range(k+1)] w = data.describe(percentiles = w)[4:4+k+1] #使用describe函數自動計算分位數 w[0] = w[0]*(1-1e-10) d2 = pd.cut(data, w, labels = range(k)) def cluster_plot(d, k): #自定義作圖函數來顯示聚類結果 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #用來正常顯示中文標簽 plt.rcParams['axes.unicode_minus'] = False #用來正常顯示負號 plt.figure(figsize = (8, 3)) for j in range(0, k): plt.plot(data[d==j], [j for i in d[d==j]], 'o') plt.ylim(-0.5, k-0.5) return plt if __name__=='__main__': from sklearn.cluster import KMeans # 引入KMeans kmodel = KMeans(n_clusters=k, n_jobs=4) # 建立模型,n_jobs是并行數,一般等于CPU數較好 kmodel.fit(data.values.reshape((len(data), 1))) # 訓練模型 c = pd.DataFrame(kmodel.cluster_centers_).sort_values(0) # 輸出聚類中心,并且排序(默認是隨機序的) w = c.rolling(2).mean().iloc[1:] # 相鄰兩項求中點,作為邊界點 w = [0] + list(w[0]) + [data.max()] # 把首末邊界點加上 d3 = pd.cut(data, w, labels=range(k)) cluster_plot(d1, k).show() cluster_plot(d2, k).show() cluster_plot(d3, k).show()
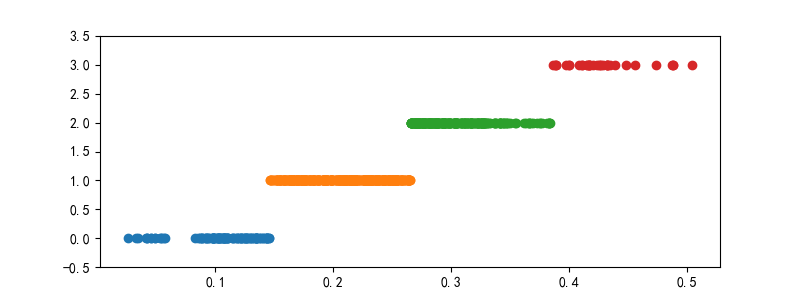
等寬離散化結果
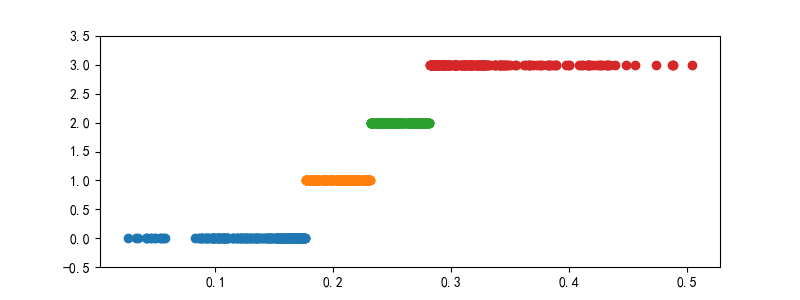
等頻離散化結果
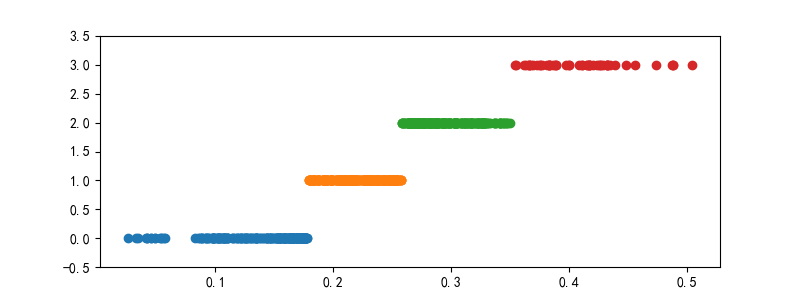
(一維)聚類離散化結果
在數據挖掘的過程中,為了提取更有用的信息,挖掘更深層次的模式,提高挖掘結果的 精度,我們需要利用已有的屬性集構造出新的屬性,并加入到現有的屬性集合中。
代碼清單4-4線損率屬性構造
#-*- coding: utf-8 -*- #線損率屬性構造 import pandas as pd #參數初始化 inputfile= '../data/electricity_data.xls' #供入供出電量數據 outputfile = '../tmp/electricity_data.xls' #屬性構造后數據文件 data = pd.read_excel(inputfile) #讀入數據 data[u'線損率'] = (data[u'供入電量'] - data[u'供出電量'])/data[u'供入電量'] data.to_excel(outputfile, index = False) #保存結果
小波變換的同是一種新型的數據分析工具,是近年來興起的信號分析手段。小波分析的理論和方法在信號處理、圖像處理、語音處理、模式識別、量子物理等領域得到越來越廣泛的應用,它被認為是近年來在工具及方法上的重大突破。小波變換具有多分辨率的特點,在 時域和頻域都具有表征信號局部特征的能力,通過伸縮和平移等運算過程對信號進行多尺度 聚焦分析,提供了一種非平穩信號的時頻分析手段,可以由粗及細地逐步觀察信號,從中提取有用信息。
能夠刻畫某個問題的特征量往往是隱含在一個信號中的某個或者某些分量中,小波變換 可以把非平穩信號分解為表達不同層次、不同頻帶信息的數據序列,即小波系數。選取適當的小波系數,即完成了信號的特征提取。下面將介紹基于小波變換的信號特征提取方法。
(1)基于小波變換的特征提取方法
基于小波變換的特征提取方法主要有:基于小波變換的多尺度空間能量分布特征提取、 基于小波變換的多尺度空間的模極大值特征提取、基于小波包變換的特征提取、基于適應性小波神經網絡的特征提取,詳見表4-5。
表4-5基于小波變換的特征提取方法
| 基于小波變換的特征提取方法 | 方法描述 |
|---|---|
| 基于小波變換的多尺度空間 能量分布特征提取方法 | 各尺度空間內的平滑信號和細節信號能提供原始信號的時頻局域信息,特別 是能提供不同頻段上信號的構成信息。把不同分解尺度上信號的能量求解出來, 就可以將這些能量尺度順序排列,形成特征向量供識別用 |
| 基于小波變換的多尺度空間 的模極大值特征提取方法 | 利用小波變換的信號局域化分析能力,求解小波變換的模極大值特性來檢測 信號的局部奇異性,將小波變換模極大值的尺度參數S、平移參數,及其幅值作 為目標的特征量 |
| 基于小波包變換的特征提取 方法 | 利用小波分解,可將時域隨機信號序列映射為尺度域各子空間內的隨機系數 序列,按小波包分解得到的最佳子空間內隨機系數序列的不確定性程度最低, 將最佳子空間的嫡值及最佳子空間在完整二叉樹中的位置參數作為特征量,可 以用于目標識別 |
| 基于適應性小波神經網絡的 特征提取方法 | 基于適應性小波神經網絡的特征提取方法可以把信號通過分析小波擬合表示, 進行特征提取 |
利用小波變換可以對聲波信號進行特征提取,提取出可以代表聲波信號的向量數據,即完成從聲波信號到特征向量數據的變換。
在Python中,Scipy本身提供了一些信號處理函數,但不夠全面, 而更好的信號處理庫是PyWavelets (pywt)。
代碼清單4-5,小波變換特征提取代碼
#-*- coding: utf-8 -*- #利用小波分析進行特征分析 #參數初始化 inputfile= '../data/leleccum.mat' #提取自Matlab的信號文件 from scipy.io import loadmat #mat是MATLAB專用格式,需要用loadmat讀取它 mat = loadmat(inputfile) signal = mat['leleccum'][0] import pywt #導入PyWavelets coeffs = pywt.wavedec(signal, 'bior3.7', level = 5) #返回結果為level+1個數字,第一個數組為逼近系數數組,后面的依次是細節系數數組
在大數據集上進行復雜的數據分析和挖掘需要很長的時間,數據規約產生更小但保持原數據完整性的新數據集。在規約后的數據集上進行分析和挖掘將更有效率。
數據規約的意義在于:
降低無效、錯誤數據對建模的影響,提高建模的準確性;
少量且具代表性的數據將大幅縮減數據挖掘所需的時間;
降低儲存數據的成本。
屬性規約通過屬性合并來創建新屬性維數,或者直接通過刪除不相關的屬性(維)來減少數據維數,從而提高數據挖掘的效率、降低計算成本。屬性規約的目標是尋找出最小的屬性子集并確保新數據子集的概率分布盡可能地接近原來數據集的概率分布。
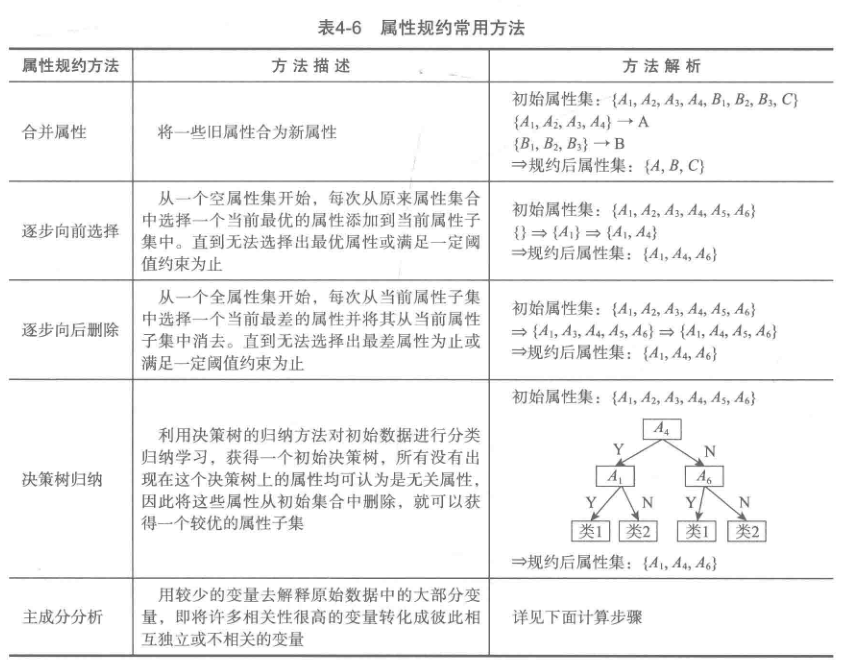
逐步向前選擇、逐步向后刪除和決策樹歸納是屬于直接刪除不相關屬性(維)方法。主成分分析是一種用于連續屬性的數據降維方法,它構造了原始數據的一個正交變換,新空間的基底去除了原始空間基底下數據的相關性,只需使用少數新變量就能夠解釋原始數據中的 大部分變異。在應用中,通常是選出比原始變量個數少,能解釋大部分數據中的變量的幾個新變量,即所謂主成分,來代替原始變量進行建模。
計算主成分:
在Python中,主成分分析的函數位于Scikit-Leam下:
sklearn.decomposition.PCA(n_components = None,copy = True,whiten = False)
參數說明:
(1) n_components
意義:PCA算法中所要保留的主成分個數n,也即保留下來的特征個數n。
類型:int或者string,缺省時默認為None,所有成分被保留。賦值為int,比如n_components =1將把原始數據降到一個維度。賦值為string,比如n_components =‘mle’,將自動選取特征個數n,使得滿足所要求的方差百分比。
(2 ) copy
類型:bool, True或者False,缺省時默認為True。
意義:表示是否在運行算法時,將原始訓練數據復制一份。若為True,則運行PCA 算法后,原始訓練數據的值不會有任何改變,因為是在原始數據的副本上進行運算;若為 False,則運行PCA算法后,原始訓練數據的值會改,因為是在原始數據上進行降維計算。
(3 ) whiten
類型:bool,缺省時默認為False。
意義:白化,使得每個特征具有相同的方差。
使用主成分分析降維的程序如代碼清單4-6所示。
代碼清單4-6,主成分分析降維代碼
#-*- coding: utf-8 -*- #主成分分析 降維 import pandas as pd #參數初始化 inputfile = '../data/principal_component.xls' outputfile = '../tmp/dimention_reducted.xls' #降維后的數據 data = pd.read_excel(inputfile, header = None) #讀入數據 from sklearn.decomposition import PCA pca = PCA() pca.fit(data) print(pca.components_ )#返回模型的各個特征向量 print(pca.explained_variance_ratio_) #返回各個成分各自的方差百分比(貢獻率) ''' 方差百分比越大,說明向量的權 重越大 當選取前4個主成分時,累計貢獻率已達到97.37%,說明選取前3個主成分進行計算已經相當不錯了, 因此可以重新建立PCA模型,設置n_components=3,計算出成分結果。 ''' pca = PCA(n_components=3) pca.fit(data) low_d = pca.transform(data) #用它來降低維度 print(low_d) pd.DataFrame(low_d).to_excel(outputfile) #保存結果 pca.inverse_transform(low_d) #必要時可inverse_transform()函數來復原數據
數值規約指通過選擇替代的、較小的數據來減少數據量,包括有參數方法和無參數方法兩類。有參數方法是使用一個模型來評估數據,只需存放參數,而不需要存放實際數據,例如回歸(線性回歸和多元回歸)和對數線性模型(近似離散屬性集中的多維概率分布)。無參數方法就需要存放實際數據,例如直方圖、聚類、抽樣(采樣)。
表4-7 Python主要數據預處理函數
| 函數名 | 函數功能 | 所屬擴展庫 |
|---|---|---|
| interpolate | 一維、高維數據插值 | Scipy |
| unique | 去除數據中的重復元素,得到單值元素列表,它是對象的方法名 | Pandas/Numpy |
| isnull | 判斷是否空值 | Pandas |
| notnull | 判斷是否非空值 | Pandas |
| PCA | 對指標變量矩陣進行主成分分析 | Scikit-Leam |
| random | 生成隨機矩陣 | Numpy |
(1 ) interpolate
1 ) 功能:interpolate是Scipy的一個子庫,包含了大量的插值函數,如拉格朗日插值、 樣條插值、高維插值等。使用前需要用from scipy.interpolate import *引入相應的插值函數, 讀者應該根據需要到官網查找對應的函數名。
2 ) 使用格式:f = scipy.interpolate.lagrange(x, y)。這里僅僅展示了一維數據的拉格朗日插值的命令,其中x,y為對應的自變量和因變量數據。插值完成后,可以通過f(a)計算新的 插值結果。類似的還有樣條插值、多維數據插值等,此處不一一展示。
(2) unique
1 ) 功能:去除數據中的重復元素,得到單值元素列表。它既是Numpy庫的一個函數 (np.unique()),也是Series對象的一個方法。
2 ) 使用格式:
np.unique(D), D 是一維數據,可以是 list、array、Series;
D.unique(), D 是 Pandas 的 Series 對象。
3 ) 實例:求向量A中的單值元素,并返回相關索引。
> D = pd.Series ([1, 1, 2, 3, 5]) > D.unique () array([1, 2, 3, 5], dtype=int64) > np.unique (D) array([1, 2, 3, 5], dtype=int64)
(3) isnull/ notnull
1 ) 功能:判斷每個元素是否空值/非空值。
2 ) 使用格式:D.isnull()/ D.notnull()。這里的D要求是Series對象,返回一個布爾 Series。可以通過D[D.isnull()]或D[D.notnull()]找出D中的空值/非空值。
(4) random
1 ) 功能:random是Numpy的一個子庫(Python本身也自帶了 random,但Numpy的更加強大),可以用該庫下的各種函數生成服從特定分布的隨機矩陣,抽樣時可使用。
2 ) 使用格式:
np.random.rand(k, m, n,…)生成一個k x m x n x…隨機矩陣,其元素均勻分布在區 間(0,1)上;
np.random.randn(k, m, n,…)生成一個k x m x n x …隨機矩陣,其元素服從標準正態分布。
(5) PCA
1 ) 功能:對指標變量矩陣進行主成分分析。使用前需要用from skleam.decomposition import PCA引入該函數。
2 ) 使用格式:model = PCA()。注意,Scikit-Leam下的PCA是一個建模式的對象,也 就是說,一般的流程是建模,然后是訓練model.fit(D), D為要進行主成分分析的數據矩陣, 訓練結束后獲取模型的參數,如.components_獲取特征向量,以及.explained_variance_ratio_獲取各個屬性的貢獻率等。
3 ) 實例:使用PCA()對一個10x4維的隨機矩陣進行主成分分析。
from sklearn.decomposition import PCA D = np.random.rand(10,4) pca = PCA() pca.fit (D) PCA(copy=True, n_components=None, whiten=False) pca. components_ #返回模型的各個特征向量 pca.explained_variance_ratio_ #返回各個成分各自的方差百分比
“python數據分析的知識點有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





