溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何分析TensorFlow基礎中的卷積神經網絡,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
抓住它的核心思路,即通過卷積操作縮小了圖像的內容,將模型注意力集中在圖像特定的、明顯的特征上。
max pooling - 增強特征,減少數據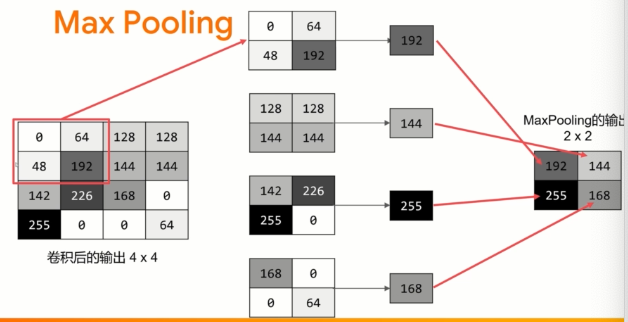
在下面的代碼中模型在訓練數據上的精度可能上升到93%左右,在驗證數據上可能上升到91%。
這是朝著正確方向取得的顯著進步!
試著運行更多的epochs--比如20個epochs,然后觀察結果! 雖然結果可能看起來非常好,但實際上驗證結果可能會下降,這是因為"過擬合"造成的,后面將會討論。
(簡而言之,'過擬合'發生在網絡模型從訓練集中學習到的結果非常好,但它太狹隘了,只能識別訓練數據,而在看到其他數據時效果不佳。舉個例子,如果我們一輩子只看到紅色的鞋子,那么當我們看到一雙藍色的麂皮鞋可能會感到迷惑......再舉一例,應試教育往往使得學生只對做過的題目有很好的正確率,但對真實的問題卻錯誤率很高)

import tensorflow as tf
print(tf.__version__)
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images.reshape(60000, 28, 28, 1)
training_images=training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
model.fit(training_images, training_labels, epochs=5)
test_loss = model.evaluate(test_images, test_labels)
第一步是收集數據。我們會注意到,這里和之前有一點變化,訓練數據需要改變維度(shape)。這是因為第一次卷積期望一個包含所有數據的單一張量,所以要把訓練數據設置為60000x28x28x1的一個4D列表,測試圖像也是如此處理。如果不這樣做,會在訓練時得到一個錯誤,因為卷積操作將不能識別數據形狀。
接下來是定義模型。首先要添加一個卷積層。參數是
過濾器數量)。這個數值是任意的,
但最好是從32開始的倍數。過濾器的大小),在本例中為3x3網格。這是最常用的尺寸。要使用的激活函數 -- 在本例中,我們將使用relu,我們可能還記得它相當于當x>0時返回x,否則返回0。在第一層,設定輸入數據的形狀。在卷積層之后加上一個MaxPooling層,用來壓縮圖像,同時保持卷積所強調的特征內容。通過為MaxPooling指定(2,2),效果是將圖像的大小縮小四分之一。它的想法是創建一個2x2的像素數組,然后選取最大的一個,從而將4個像素變成1個,在整個圖像中重復這樣做,這樣做的結果是將水平像素的數量減半,垂直像素的數量減半,有效地將圖像縮小25%。
再增加一個卷積層和MaxPooling2D。
現在對輸出進行扁平化處理。在這之后,你將擁有與非卷積版本相同的DNN結構,即全連接神經元網絡。
含有128個神經元的全連接層,以及10個神經元的輸出層。
現在編譯模型,調用model.fit方法做訓練,接著用測試集評估損失和準確率。
看看可否只使用單個卷積層和單個MaxPooling 2D將MNIST(手寫數字)識別率提高到99.8%或更高的準確率。一旦準確率超過這個數值,應該停止訓練。Epochs不應超過20個。如果epochs達到20但精度未達到要求,那么就需要重新設計層結構。當達到99.8%的準確率時,你應該打印出 "達到99.8%準確率,所以取消訓練!"的字符串。
import tensorflow as tf
from tensorflow import keras
## overwrite callback
class Callbacks(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>=0.998):
print("達到99.8%準確率,所以取消訓練!")
self.model.stop_training = True
callbacks = Callbacks()
## 準備數據
mnist = tf.keras.datasets.mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
## 歸一化
training_images = training_images.reshape(60000, 28, 28, 1)
training_images = training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images = test_images / 255.0
## 建立模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
# tf.keras.layers.Conv2D(62, (3, 3), activation='relu'),
# tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(), ##扁平化
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
## 訓練
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
model.summary()
model.fit(training_images, training_labels, epochs=4, callbacks=[callbacks])
## 預測和評估
test_loss = model.evaluate(test_images, test_labels)
結果
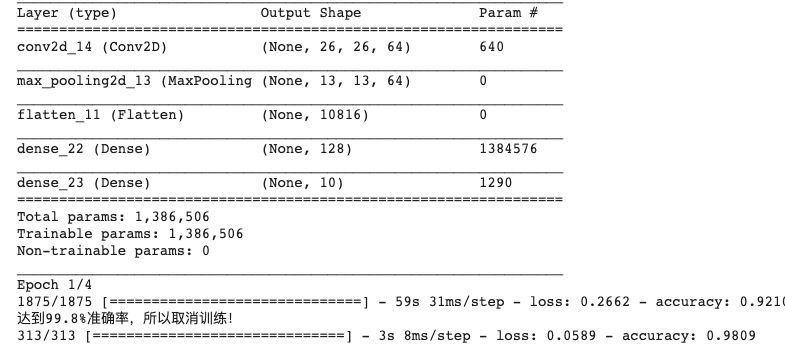
關于如何分析TensorFlow基礎中的卷積神經網絡問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





