溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
從RxJS到Flink該如何處理數據流,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
大家在前端開發的過程中,可能會想過這樣一個問題:前端開發究竟是在開發什么?在我看來,前端開發的本質是讓網頁視圖能夠正確地響應相關事件。在這句話中有三個關鍵字:"網頁視圖","正確地響應"和"相關事件"。
"相關事件"可能包括頁面點擊,鼠標滑動,定時器,服務端請求等等,"正確地響應"意味著我們要根據相關的事件來修改一些狀態,而"網頁視圖"就是我們前端開發中最熟悉的部分了。
按照這樣的觀點我們可以給出這樣 視圖 = 響應函數(事件) 的公式:
View = reactionFn(Event)
在前端開發中,需要被處理事件可以歸類為以下三種:
用戶執行頁面動作,例如 click, mousemove 等事件。
遠程服務端與本地的數據交互,例如 fetch, websocket。
本地的異步事件,例如 setTimeout, setInterval async_event。
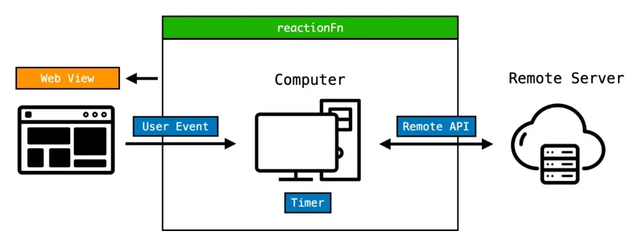
這樣我們的公式就可以進一步推導為:
View = reactionFn(UserEvent | Timer | Remote API)
為了能夠更進一步理解這個公式與前端開發的關系,我們以新聞網站舉例,該網站有以下三個要求:
單擊刷新:單擊 Button 刷新數據。
勾選刷新:勾選 Checkbox 時自動刷新,否則停止自動刷新。
下拉刷新:當用戶從屏幕頂端下拉時刷新數據。
如果從前端的角度分析,這三種需求分別對應著:
單擊刷新:click -> fetch
勾選刷新:change -> (setInterval + clearInterval) -> fetch
下拉刷新:(touchstart + touchmove + touchend) -> fetch news_app

1 MVVM
在 MVVM 的模式下,對應上文的響應函數(reactionFn)會在 Model 與 ViewModel 或者 View 與 ViewModel 之間進行被執行,而事件 (Event) 會在 View 與 ViewModel 之間進行處理。
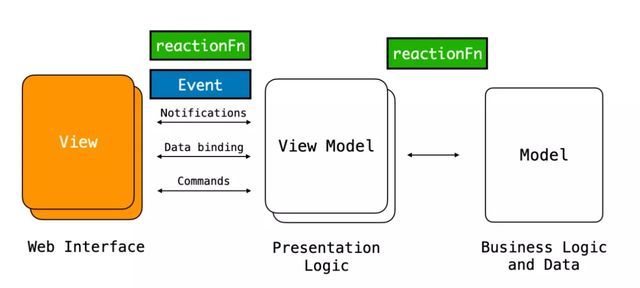
MVVM 可以很好的抽象視圖層與數據層,但是響應函數(reactionFn)會散落在不同的轉換過程中,這會導致數據的賦值與收集過程難以進行精確追蹤。另外因為事件 (Event) 的處理在該模型中與視圖部分緊密相關,導致 View 與 ViewModel 之間對事件處理的邏輯復用困難。
2 Redux
在 Redux 最簡單的模型下,若干個事件 (Event) 的組合會對應到一個 Action 上,而 reducer 函數可以被直接認為與上文提到的響應函數 (reactionFn) 對應。
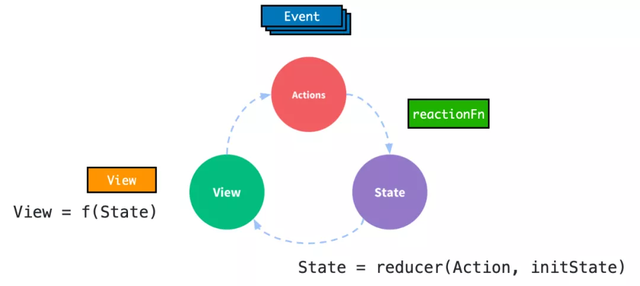
但是在 Redux 中:
State 只能用于描述中間狀態,而不能描述中間過程。
Action 與 Event 的關系并非一一對應導致 State 難以追蹤實際變化來源。
3 響應式編程與 RxJS
維基百科中是這樣定義響應式編程:
在計算中,響應式編程或反應式編程(英語:Reactive programming)是一種面向數據流和變化傳播的聲明式編程范式。這意味著可以在編程語言中很方便地表達靜態或動態的數據流,而相關的計算模型會自動將變化的值通過數據流進行傳播。
以數據流維度重新考慮用戶使用該應用的流程:
點擊按鈕 -> 觸發刷新事件 -> 發送請求 -> 更新視圖
勾選自動刷新
手指觸摸屏幕
自動刷新間隔 -> 觸發刷新事件 -> 發送請求 -> 更新視圖
手指在屏幕上下滑
自動刷新間隔 -> 觸發刷新事件 -> 發送請求 -> 更新視圖
手指在屏幕上停止滑動 -> 觸發下拉刷新事件 -> 發送請求 -> 更新視圖
自動刷新間隔 -> 觸發刷新事件 -> 發送請求 -> 更新視圖
關閉自動刷新
以 Marbles 圖表示:
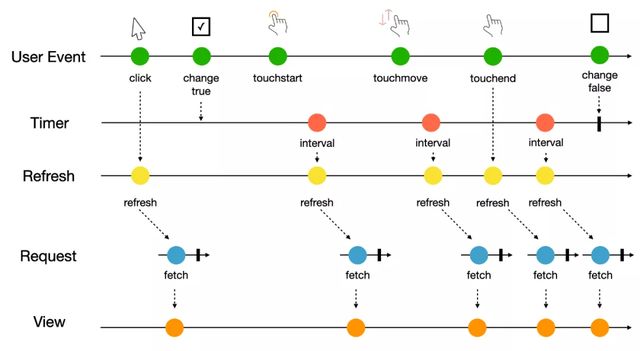
拆分上圖邏輯,就會得到使用響應式編程開發當前新聞應用時的三個步驟:
定義源數據流
組合/轉換數據流
消費數據流并更新視圖
我們分別來進行詳細描述。
定義源數據流
使用 RxJS,我們可以很方便的定義出各種 Event 數據流。
1)單擊操作
涉及 click 數據流。
click$ = fromEvent<MouseEvent>(document.querySelector('button'), 'click');2)勾選操作
涉及 change 數據流。
change$ = fromEvent(document.querySelector('input'), 'change');3)下拉操作
涉及 touchstart, touchmove 與 touchend 三個數據流。
touchstart$ = fromEvent<TouchEvent>(document, 'touchstart'); touchend$ = fromEvent<TouchEvent>(document, 'touchend'); touchmove$ = fromEvent<TouchEvent>(document, 'touchmove');
4)定時刷新
interval$ = interval(5000);
5)服務端請求
fetch$ = fromFetch('https://randomapi.azurewebsites.net/api/users');組合/轉換數據流
1)點擊刷新事件流
在點擊刷新時,我們希望短時間內多次點擊只觸發最后一次,這通過 RxJS 的 debounceTime operator 就可以實現。

clickRefresh$ = this.click$.pipe(debounceTime(300));
2)自動刷新流
使用 RxJS 的 switchMap 與之前定義好的 interval$ 數據流配合。

autoRefresh$ = change$.pipe( switchMap(enabled => (enabled ? interval$ : EMPTY)) );
3)下拉刷新流
結合之前定義好的 touchstart$touchmove$ 與 touchend$ 數據流。
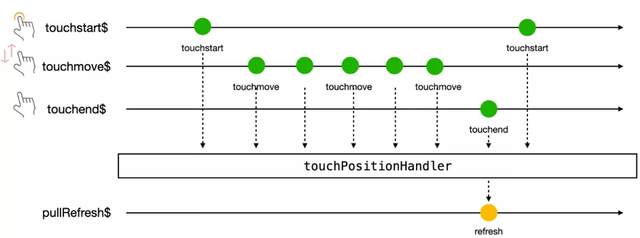
pullRefresh$ = touchstart$.pipe( switchMap(touchStartEvent => touchmove$.pipe( map(touchMoveEvent => touchMoveEvent.touches[0].pageY - touchStartEvent.touches[0].pageY), takeUntil(touchend$) ) ), filter(position => position >= 300), take(1), repeat() );
最后,我們通過 merge 函數將定義好的 clickRefresh$autoRefresh$ 與 pullRefresh$ 合并,就得到了刷新數據流。
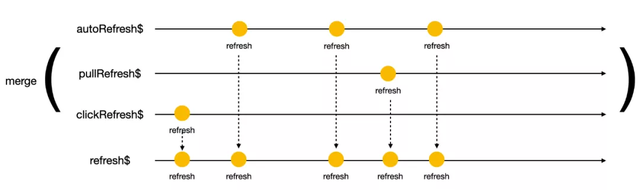
refresh$ = merge(clickRefresh$, autoRefresh$, pullRefresh$));
消費數據流并更新視圖
將刷新數據流直接通過 switchMap 打平到在第一步到定義好的 fetch$,我們就獲得了視圖數據流。
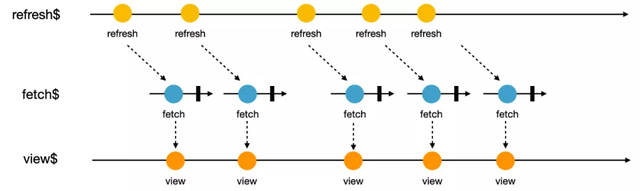
可以通過在 Angular 框架中可以直接 async pipe 將視圖流直接映射為視圖:
<div *ngFor="let user of view$ | async"> </div>
在其他框架中可以通過 subscribe 獲得數據流中的真實數據,再更新視圖。
至此,我們就使用響應式編程完整的開發完成了當前新聞應用,示例代碼[1]由 Angular 開發,行數不超過 160 行。
我們總結一下,使用響應式編程思想開發前端應用時經歷的三個過程與第一節中公式的對應關系:
View = reactionFn(UserEvent | Timer | Remote API)
1)描述源數據流
與事件UserEvent | Timer | Remote API 對應,在 RxJS 中對應函數分別是:
UserEvent: fromEvent
Timer: interval, timer
Remote API: fromFetch, webSocket
2)組合轉換數據流
與響應函數(reactionFn)對應,在 RxJS 中對應的部分方法是:
COMBINING: merge, combineLatest, zip
MAPPING: map
FILTERING: filter
REDUCING: reduce, max, count, scan
TAKING: take, takeWhile
SKIPPING: skip, skipWhile, takeLast, last
TIME: delay, debounceTime, throttleTime
3)消費數據流更新視圖
與 View 對應,在 RxJS 及 Angular 中可以使用:
subscribe
async pipe
響應式編程相對于 MVVM 或者 Redux 有什么優點呢?
描述事件發生的本身,而非計算過程或者中間狀態。
提供了組合和轉換數據流的方法,這也意味著我們獲得了復用持續變化數據的方法。
由于所有數據流均由層層組合與轉換獲得,這也就意味著我們可以精確追蹤事件及數據變化的來源。
如果我們將 RxJS 的 Marbles 圖的時間軸模糊,并在每次視圖更新時增加縱切面,我們就會發現這樣兩件有趣的事情:
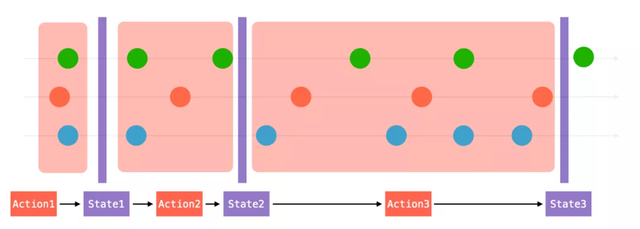
Action 是 EventStream 的簡化。
State 是 Stream 在某個時刻的對應。
難怪我們可以在 Redux 官網中有這樣一句話:如果你已經使用了 RxJS,很可能你不再需要 Redux 了。
The question is: do you really need Redux if you already use Rx? Maybe not. It's not hard to re-implement Redux in Rx. Some say it's a two-liner using Rx.scan() method. It may very well be!
寫到這里,我們對網頁視圖能夠正確地響應相關事件這句話是否可以進行進一步的抽象呢?
所有事件 -- 找到 --> 相關事件 -- 做出 --> 響應
而按時間順序發生的事件,本質上就是數據流,進一步拓展就可變成:
源數據流 -- 轉換 --> 中間數據流 -- 訂閱 --> 消費數據流
這正是響應式編程在前端能夠完美工作的基礎思想。但是該思想是否只在前端開發中有所應用呢?
答案是否定的,該思想不僅可以應用于前端開發,在后端開發乃至實時計算中都有著廣泛的應用。
在前后端開發者之間,通常由一面叫 REST API 的信息之墻隔開,REST API 隔離了前后端開發者的職責,提升了開發效率。但它同樣讓前后端開發者的眼界被這面墻隔開,讓我們試著來推倒這面信息之墻,一窺同樣的思想在實時計算中的應用。
1 實時計算 與 Apache Flink
在開始下一部分之前,讓我們先介紹一下 Flink。Apache Flink 是由 Apache 軟件基金會開發的開源流處理框架,用于在無邊界和有邊界數據流上進行有狀態的計算。它的數據流編程模型在有限和無限數據集上提供單次事件(event-at-a-time)處理能力。

在實際的應用中,Flink 通常用于開發以下三種應用:
事件驅動型應用 事件驅動型應用從一個或多個事件流提取數據,并根據到來的事件觸發計算、狀態更新或其他外部動作。場景包括基于規則的報警,異常檢測,反欺詐等等。
數據分析應用 數據分析任務需要從原始數據中提取有價值的信息和指標。例如雙十一成交額計算,網絡質量監測等等。
數據管道(ETL)應用 提取-轉換-加載(ETL)是一種在存儲系統之間進行數據轉換和遷移的常用方法。ETL 作業通常會周期性地觸發,將數據從事務型數據庫拷貝到分析型數據庫或數據倉庫。
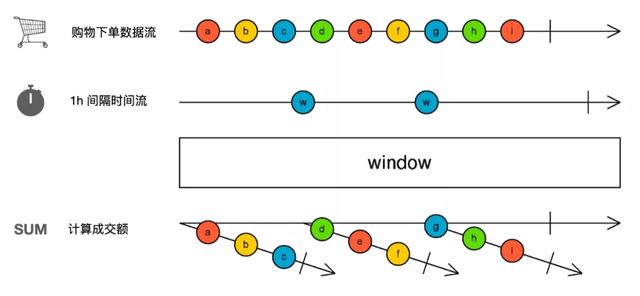
我們這里以計算電商平臺雙十一每小時成交額為例,看下我們在之前章節得到方案是否仍然可以繼續使用。
在這個場景中我們首先要獲取用戶購物下單數據,隨后計算每小時成交數據,然后將每小時的成交數據轉存到數據庫并被 Redis 緩存,最終通過接口獲取后展示在頁面中。
在這個鏈路中的數據流處理邏輯為:
用戶下單數據流 -- 轉換 --> 每小時成交數據流 -- 訂閱 --> 寫入數據庫
與之前章節中介紹的:
源數據流 -- 轉換 --> 中間數據流 -- 訂閱 --> 消費數據流
思想完全一致。
如果我們用 Marbles 描述這個過程,就會得到這樣的結果,看起來很簡單,似乎使用 RxJS 的 window operator 也可以完成同樣的功能,但是事實真的如此嗎?
2 被隱藏的復雜度
真實的實時計算比前端中響應式編程的復雜度要高很多,我們在這里舉幾個例子:
事件亂序
在前端開發過程中,我們也會碰到事件亂序的情況,最經典的情況先發起的請求后收到響應,可以用如下的 Marbles 圖表示。這種情況在前端有很多種辦法進行處理,我們在這里就略過不講。
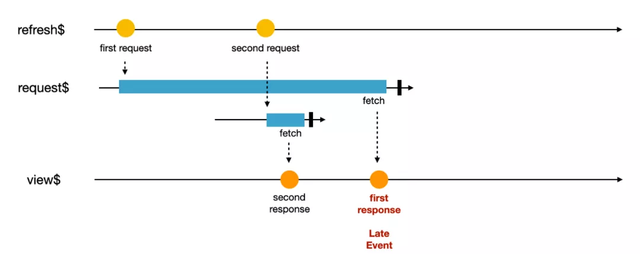
我們今天想介紹的是數據處理時面臨的時間亂序情況。在前端開發中,我們有一個很重要的前提,這個前提大幅度降低了開發前端應用的復雜度,那就是:前端事件的發生時間和處理時間相同。
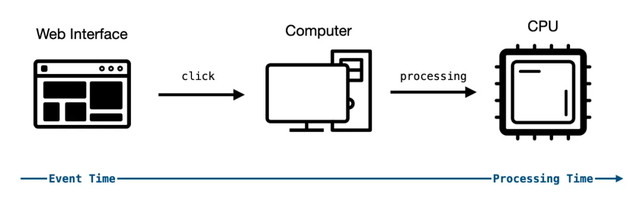
想象一下,如果用戶執行頁面動作,例如 click, mousemove 等事件都變成了異步事件,并且響應時間未知,那整個前端的開發復雜度會如何。
但是事件的發生時間與處理時間不同,在實時計算領域是一個重要的前提。我們仍以每小時成交額計算為例,當原始數據流經過層層傳輸之后,在計算節點的數據的先后順很可能已經亂序了。
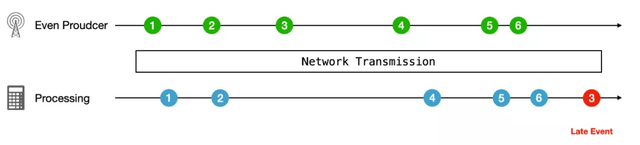
如果我們仍然以數據的到來時間來進行窗口劃分,最后的計算結果就會產生錯誤:
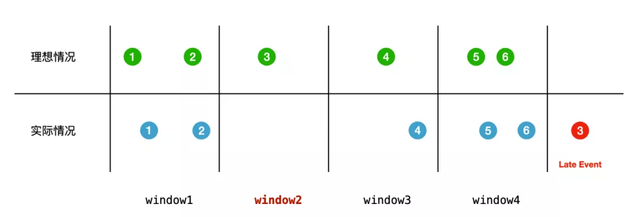
為了讓 window2 的窗口的計算結果正確,我們需要等待 late event 到來之后進行計算,但是這樣我們就面臨了一個兩難問題:
無限等下去:late event 可能在傳輸過程中丟失,window2 窗口永遠沒有數據產出。
等待時間太短:late event 還沒有到來,計算結果錯誤。
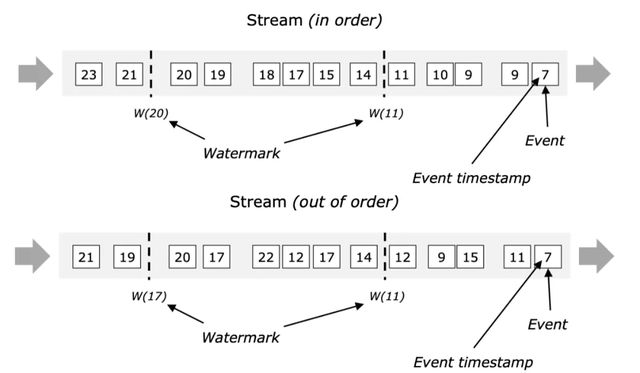
Flink 引入了 Watermark 機制來解決這個問題,Watermark 定義了什么時候不再等待 late event,本質上提供了實時計算的準確性和實時性的折中方案。
關于 Watermark 有個形象的比喻:上學的時候,老師會將班級的門關上,然后說:“從這個點之后來的同學都算遲到了,統統罰站“。在 Flink 中,Watermark 充當了老師關門的這個動作。
數據反壓
在瀏覽器中使用 RxJS 時,不知道大家有沒有考慮這樣一種情況:observable 產生的速度快于 operator 或者 observer 消費的速度時,會產生大量的未消費的數據被緩存在內存中。這種情況被稱為反壓,幸運的是,在前端產生數據反壓只會導致瀏覽器內存被大量占用,除此之外不會有更嚴重的后果。
但是在實時計算中,當數據產生的速度高于中間節點處理能力,或者超過了下游數據的消費能力時,應當如何處理?
對于許多流應用程序來說,數據丟失是不可接受的,為了保證這一點,Flink 設計了這樣一種機制:
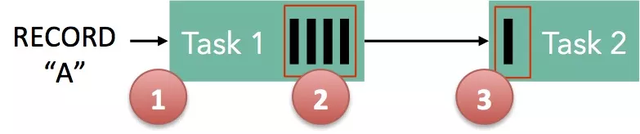
在理想情況,在一個持久通道中緩沖數據。
當數據產生的速度高于中間節點處理能力,或者超過了下游數據的消費能力時,速度較慢的接收器會在隊列的緩沖作用耗盡后立即降低發送器的速度。更形象的比喻是,在數據流流速變慢時,將整個管道從水槽“回壓”到水源,并對水源進行節流,以便將速度調整到最慢的部分,從而達到穩定狀態。
Checkpoint
實時計算領域,每秒鐘處理的數據可能有數十億條,這些數據的處理不可能由單臺機器獨立完成。事實上,在 Flink 中,operator 運算邏輯會由不同的 subtask 在 不同的 taskmanager 上執行,這時我們就面臨了另外一個問題,當某臺機器發生問題時,整體的運算邏輯與狀態該如何處理才能保證最后運算結果的正確性?
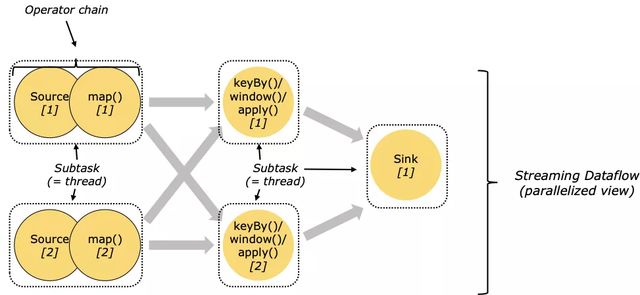
Flink 中引入了 checkpoint 機制用于保證可以對作業的狀態和計算位置進行恢復,checkpoint 使 Flink 的狀態具有良好的容錯性。Flink 使用了 Chandy-Lamport algorithm 算法的一種變體,稱為異步 barrier 快照(asynchronous barrier snapshotting)。
當開始 checkpoint 時,它會讓所有 sources 記錄它們的偏移量,并將編號的 checkpoint barriers 插入到它們的流中。這些 barriers 會經過每個 operator 時標注每個 checkpoint 前后的流部分。
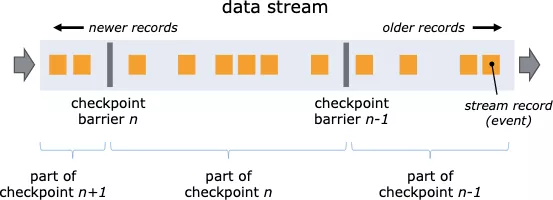
當發生錯誤時,Flink 可以根據 checkpoint 存儲的 state 進行狀態恢復,保證最終結果的正確性。
的模型無論在響應式編程還是實時計算都是通用的,希望這篇文章能夠讓大家對數據流的思想有更多的思考。
關于從RxJS到Flink該如何處理數據流問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





