溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Flink SQL怎么實現數據流的Join”,在日常操作中,相信很多人在Flink SQL怎么實現數據流的Join問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Flink SQL怎么實現數據流的Join”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
無論在 OLAP 還是 OLTP 領域,Join 都是業務常會涉及到且優化規則比較復雜的 SQL 語句。對于離線計算而言,經過數據庫領域多年的積累,Join 語義以及實現已經十分成熟,然而對于近年來剛興起的 Streaming SQL 來說 Join 卻處于剛起步的狀態。
其中最為關鍵的問題在于 Join 的實現依賴于緩存整個數據集,而 Streaming SQL Join 的對象卻是無限的數據流,內存壓力和計算效率在長期運行來說都是不可避免的問題。下文將結合 SQL 的發展解析 Flink SQL 是如何解決這些問題并實現兩個數據流的 Join。
傳統的離線 Batch SQL (面向有界數據集的 SQL)有三種基礎的實現方式,分別是 Nested-loop Join、Sort-Merge Join 和 Hash Join。
Nested-loop Join 最為簡單直接,將兩個數據集加載到內存,并用內嵌遍歷的方式來逐個比較兩個數據集內的元素是否符合 Join 條件。Nested-loop Join 雖然時間效率以及空間效率都是最低的,但勝在比較靈活適用范圍廣,因此其變體 BNL 常被傳統數據庫用作為 Join 的默認基礎選項。
Sort-Merge Join 顧名思義,分為兩個 Sort 和 Merge 階段。首先將兩個數據集進行分別排序,然后對兩個有序數據集分別進行遍歷和匹配,類似于歸并排序的合并。值得注意的是,Sort-Merge 只適用于 Equi-Join(Join 條件均使用等于作為比較算子)。Sort-Merge Join 要求對兩個數據集進行排序,成本很高,通常作為輸入本就是有序數據集的情況下的優化方案。
Hash Join 同樣分為兩個階段,首先將一個數據集轉換為 Hash Table,然后遍歷另外一個數據集元素并與 Hash Table 內的元素進行匹配。第一階段和第一個數據集分別稱為 build 階段和 build table,第二個階段和第二個數據集分別稱為 probe 階段和 probe table。Hash Join 效率較高但對空間要求較大,通常是作為 Join 其中一個表為適合放入內存的小表的情況下的優化方案。和 Sort-Merge Join 類似,Hash Join 也只適用于 Equi-Join。
相對于離線的 Join,實時 Streaming SQL(面向無界數據集的 SQL)無法緩存所有數據,因此 Sort-Merge Join 要求的對數據集進行排序基本是無法做到的,而 Nested-loop Join 和 Hash Join 經過一定的改良則可以滿足實時 SQL 的要求。
我們通過例子來看基本的 Nested Join 在實時 Streaming SQL 的基礎實現(案例及圖來自 Piotr Nowojski 在 Flink Forward San Francisco 的分享[2])。
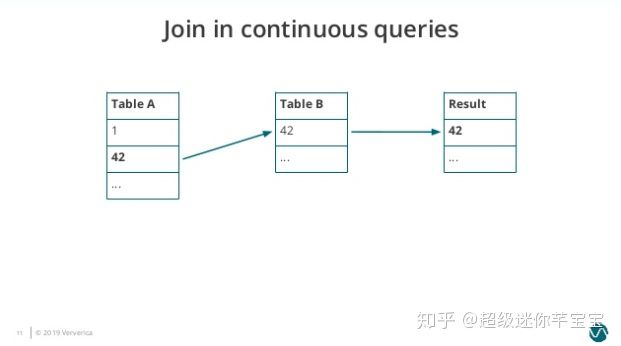
圖1. Join-in-continuous-query-1
Table A 有 1、42 兩個元素,Table B 有 42 一個元素,所以此時的 Join 結果會輸出 42。
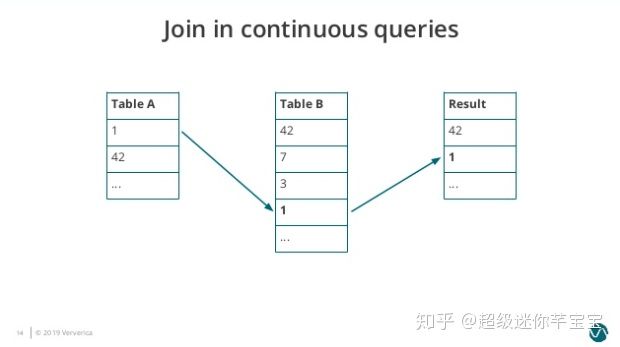
圖2. Join-in-continuous-query-2
接著 Table B 依次接受到三個新的元素,分別是 7、3、1。因為 1 匹配到 Table A 的元素,因此結果表再輸出一個元素 1。
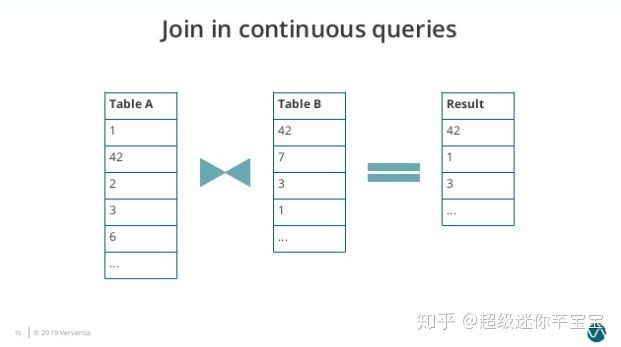
圖3. Join-in-continuous-query-3
隨后 Table A 出現新的輸入 2、3、6,3 匹配到 Table B 的元素,因此再輸出 3 到結果表。
可以看到在 Nested-Loop Join 中我們需要保存兩個輸入表的內容,而隨著時間的增長 Table A 和 Table B 需要保存的歷史數據無止境地增長,導致很不合理的內存磁盤資源占用,而且單個元素的匹配效率也會越來越低。類似的問題也存在于 Hash Join 中。
那么有沒有可能設置一個緩存剔除策略,將不必要的歷史數據及時清理呢?答案是肯定的,關鍵在于緩存剔除策略如何實現,這也是 Flink SQL 提供的三種 Join 的主要區別。
Regular Join
Regular Join 是最為基礎的沒有緩存剔除策略的 Join。Regular Join 中兩個表的輸入和更新都會對全局可見,影響之后所有的 Join 結果。舉例,在一個如下的 Join 查詢里,Orders 表的新紀錄會和 Product 表所有歷史紀錄以及未來的紀錄進行匹配。
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
因為歷史數據不會被清理,所以 Regular Join 允許對輸入表進行任意種類的更新操作(insert、update、delete)。然而因為資源問題 Regular Join 通常是不可持續的,一般只用做有界數據流的 Join。
Time-Windowed Join
Time-Windowed Join 利用窗口給兩個輸入表設定一個 Join 的時間界限,超出時間范圍的數據則對 JOIN 不可見并可以被清理掉。值得注意的是,這里涉及到的一個問題是時間的語義,時間可以指計算發生的系統時間(即 Processing Time),也可以指從數據本身的時間字段提取的 Event Time。如果是 Processing Time,Flink 根據系統時間自動劃分 Join 的時間窗口并定時清理數據;如果是 Event Time,Flink 分配 Event Time 窗口并依據 Watermark 來清理數據。
以更常用的 Event Time Windowed Join 為例,一個將 Orders 訂單表和 Shipments 運輸單表依據訂單時間和運輸時間 Join 的查詢如下:
SELECT * FROM Orders o, Shipments s WHERE o.id = s.orderId AND s.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
這個查詢會為 Orders 表設置了 o.ordertime > s.shiptime- INTERVAL ‘4’ HOUR 的時間下界(圖4)。
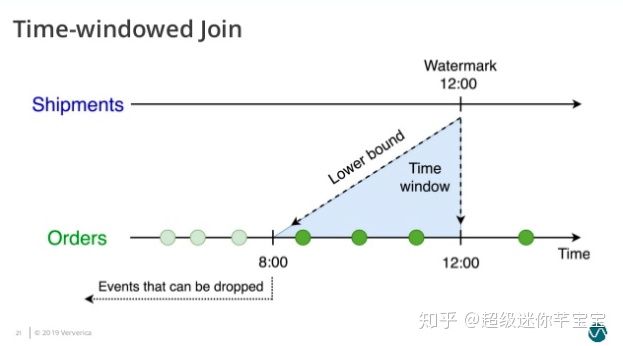
圖4. Time-Windowed Join 的時間下界 - Orders 表
并為 Shipmenets 表設置了 s.shiptime >= o.ordertime 的時間下界(圖5)。
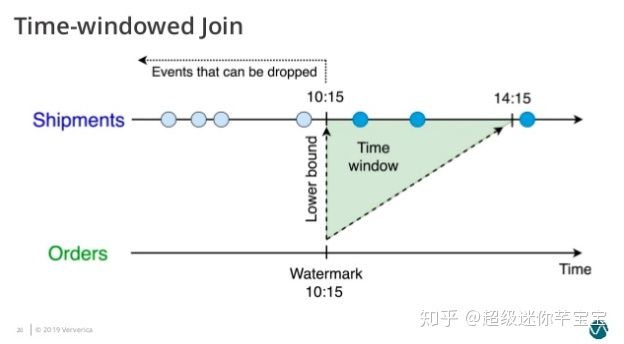
圖5. Time-Windowed Join 的時間下界 - Shipment 表
因此兩個輸入表都只需要緩存在時間下界以上的數據,將空間占用維持在合理的范圍。
不過雖然底層實現上沒有問題,但如何通過 SQL 語法定義時間仍是難點。盡管在實時計算領域 Event Time、Processing Time、Watermark 這些概念已經成為業界共識,但在 SQL 領域對時間數據類型的支持仍比較弱[4]。因此,定義 Watermark 和時間語義都需要通過編程 API 的方式完成,比如從 DataStream 轉換至 Table ,不能單純靠 SQL 完成。這方面的支持 Flink 社區計劃通過拓展 SQL 方言來完成,感興趣的讀者可以通過 FLIP-66[7] 來追蹤進度。
Temporal Table Join
雖然 Timed-Windowed Join 解決了資源問題,但也限制了使用場景: Join 兩個輸入流都必須有時間下界,超過之后則不可訪問。這對于很多 Join 維表的業務來說是不適用的,因為很多情況下維表并沒有時間界限。針對這個問題,Flink 提供了 Temporal Table Join 來滿足用戶需求。
Temporal Table Join 類似于 Hash Join,將輸入分為 Build Table 和 Probe Table。前者一般是緯度表的 changelog,后者一般是業務數據流,典型情況下后者的數據量應該遠大于前者。在 Temporal Table Join 中,Build Table 是一個基于 append-only 數據流的帶時間版本的視圖,所以又稱為 Temporal Table。Temporal Table 要求定義一個主鍵和用于版本化的字段(通常就是 Event Time 時間字段),以反映記錄在不同時間的內容。
比如典型的一個例子是對商業訂單金額進行匯率轉換。假設有一個 Orders 流記錄訂單金額,需要和 RatesHistory 匯率流進行 Join。RatesHistory 代表不同貨幣轉為日元的匯率,每當匯率有變化時就會有一條更新記錄。兩個表在某一時間節點內容如下:
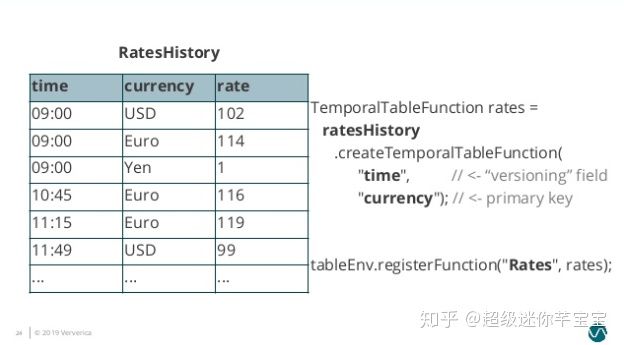
圖6. Temporal Table Join Example]
我們將 RatesHistory 注冊為一個名為 Rates 的 Temporal Table,設定主鍵為 currency,版本字段為 time。
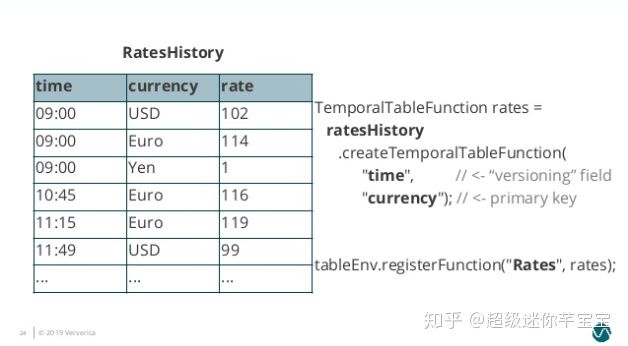
圖7. Temporal Table Registration]
此后給 Rates 指定時間版本,Rates 則會基于 RatesHistory 來計算符合時間版本的匯率轉換內容。
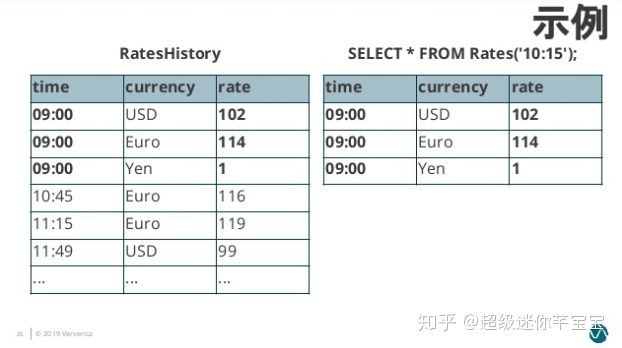
圖8. Temporal Table Content]
在 Rates 的幫助下,我們可以將業務邏輯用以下的查詢來表達:
SELECT o.amount * r.rate FROM Orders o, LATERAL Table(Rates(o.time)) r WHERE o.currency = r.currency
值得注意的是,不同于在 Regular Join 和 Time-Windowed Join 中兩個表是平等的,任意一個表的新記錄都可以與另一表的歷史記錄進行匹配,在 Temporal Table Join 中,Temoparal Table 的更新對另一表在該時間節點以前的記錄是不可見的。這意味著我們只需要保存 Build Side 的記錄直到 Watermark 超過記錄的版本字段。因為 Probe Side 的輸入理論上不會再有早于 Watermark 的記錄,這些版本的數據可以安全地被清理掉。
到此,關于“Flink SQL怎么實現數據流的Join”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





