溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python中怎么利用正則表達式從網頁摘取信息,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
練習從網頁爬取數據時,為了不觸發網站的反爬機制,建議打開網頁另存為html文件。我從某網站保存了一頁關于房產信息的網頁,嘗試從中爬取信息。
然后用notepad++打開該文件,看看文件內容。

是不是感覺有點無從下手?別慌,慢慢來。通過對比網頁和網頁代碼我們確認信息特征。
房產名稱:
急降60萬 急賣全款客戶來 寶山二村好位置
復制該信息,到html文件中通過ctrl+F查找該信息,然后認真查看“房產名稱”前后的字符特征:
前面的字符特征:
;</span>" >
后面的字符特征:
&nbsp;
現在對照房產名稱前后的字符特征編寫正則表達式,同時給“房產名稱”進行分組命名(?P.*?):
;</span>" >(?P<name>.*?)&nbsp;
注意: .*?在爬取網頁時經常會用到,表示匹配任意內容任意數量直到遇到后面的字符特征結束。
房型:
現在再觀察下一項“房型”信息前后的字符特征:
前面的字符特征:
span></span>
后面的字符特征:
<span class="html-tag">
如法炮制,提取“房型”信息并進行分組命名(?P.*?):
span></span>(?P<type>.*?)<span class="html-tag">
注意: 在房產名稱和房型之間有大段網頁代碼,我們可以寫.*?對應該段代碼表示跳過。
面積:
現在再觀察下一項“面積”信息前后的字符特征:
前面的字符特征:
<span class="html-tag"><span></span>
后面的字符特征:
<span
如法炮制,提取“面積”信息并進行分組命名(?P.*?):
<span class="html-tag"><span></span>(?P<area>.*?) <span
總價:
現在就剩最后一項“總價”信息,繼續查找該信息前后的字符特征:
前面的字符特征:
</span><span class="html-tag"><b></span>
后面的字符特征:
<span class="html-tag"><
如法炮制,提取“總價”信息并進行分組命名(?P.*?):
</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><
現在提取網頁數據四項信息的正則表達式均已寫好,注意每一項信息之間間隔了很多的網頁代碼,我們可以用.*?對應該段代碼表示跳過。讓我們現在把4段信息連起來,寫出完整的正則表達式:
rex = ';</span>" >(?P<name>.*?)&nbsp;.*?span></span>(?P<type>.*?)<span class="html-tag">.*?<span class="html-tag"><span></span>(?P<area>.*?) <span.*?</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><'
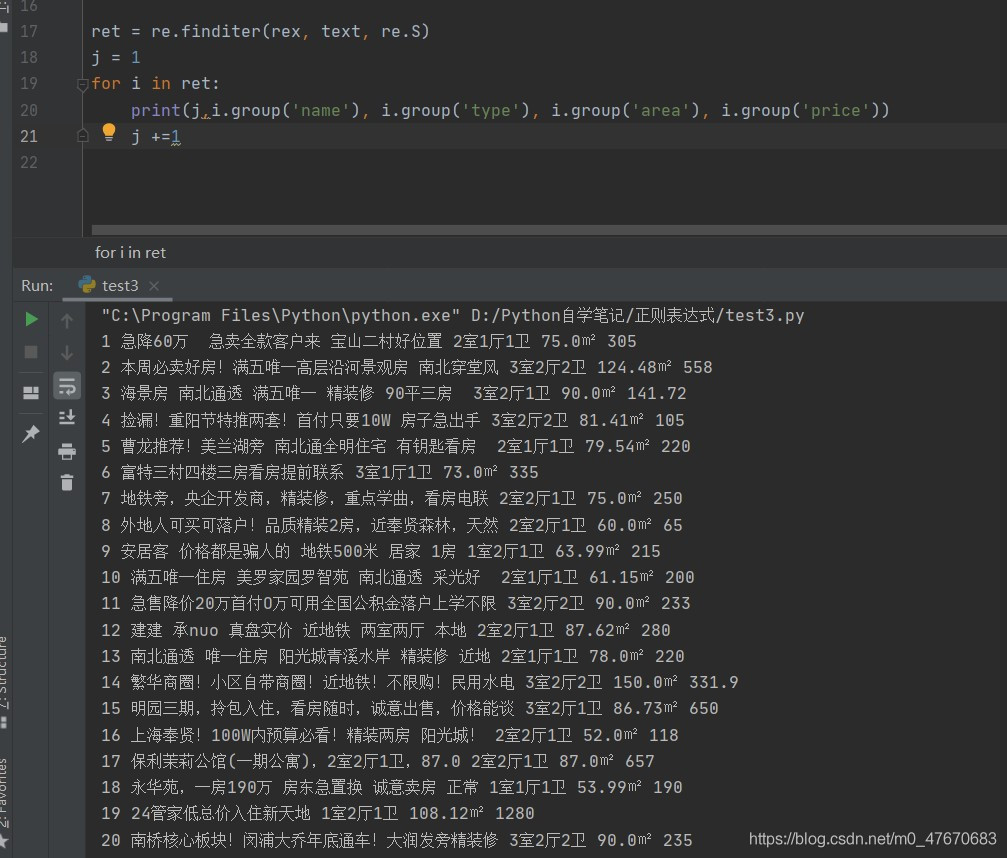
import rewith open('房屋信息.html',encoding='utf8') as f:text = f.read()rex = ';</span>" >(?P<name>.*?)&nbsp;.*?span></span>(?P<type>.*?)<span class="html-tag">.*?<span class="html-tag"><span></span>(?P<area>.*?) <span.*?</span><span class="html-tag"><b></span>(?P<price>.*?)<span class="html-tag"><'ret = re.finditer(rex, text, re.S)j = 1for i in ret:print(j,i.group('name'), i.group('type'), i.group('area'), i.group('price'))j +=1最終輸出內容有120項,信息式樣如下:
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





