溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“大數據數據庫HBase的集群安裝部署方法”,在日常操作中,相信很多人在大數據數據庫HBase的集群安裝部署方法問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”大數據數據庫HBase的集群安裝部署方法”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
<font color=#999AAA >Hive的學習告一段落,接下來開始了解大數據主流NoSql數據庫HBase,本文主要講解HBase集群的安裝部署,為后續Hbase學習作準備。</font>
<hr color=#000000 size=1">
漫畫學習HBase----最易懂的Hbase架構原理解析
HBase基于Google的BigTable論文,是建立的==HDFS==之上,提供高可靠性、高性能、列存儲、可伸縮、實時讀寫的分布式數據庫系統。
在需要==實時讀寫隨機訪問==超大規模數據集時,可以使用HBase。
==海量存儲==
可以存儲大批量的數據
==列式存儲==
HBase表的數據是基于列族進行存儲的,列族是在列的方向上的劃分。
==極易擴展==
底層依賴HDFS,當磁盤空間不足的時候,只需要動態增加datanode節點就可以了
可以通過增加服務器來對集群的存儲進行擴容
==高并發==
支持高并發的讀寫請求
==稀疏==
稀疏主要是針對HBase列的靈活性,在列族中,你可以指定任意多的列,在列數據為空的情況下,是不會占用存儲空間的。
==數據的多版本==
HBase表中的數據可以有多個版本值,默認情況下是根據版本號去區分,版本號就是插入數據的時間戳
==數據類型單一==
所有的數據在HBase中是以==字節數組==進行存儲
下載安裝包并上傳到node01服務器
安裝包下載地址:
http://archive.cloudera.com/cdh6/cdh/5/hbase-1.2.0-cdh6.14.2.tar.gz
將安裝包上傳到node01服務器/kkb/soft路徑下,并進行解壓
[hadoop@node01 ~]$ cd /kkb/soft/ [hadoop@node01 soft]$ tar -xzvf hbase-1.2.0-cdh6.14.2.tar.gz -C /kkb/install/
修改文件
[hadoop@node01 soft]$ cd /kkb/install/hbase-1.2.0-cdh6.14.2/conf/ [hadoop@node01 conf]$ vim hbase-env.sh
修改如下兩項內容,值如下
export JAVA_HOME=/kkb/install/jdk1.8.0_141 export HBASE_MANAGES_ZK=false


修改文件
[hadoop@node01 conf]$ vim hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://node01:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 0.98后的新變動,之前版本沒有.port,默認端口為60000 --> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node01,node02,node03</value> </property> <!-- 此屬性可省略,默認值就是2181 --> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/kkb/install/zookeeper-3.4.5-cdh6.14.2/zkdatas</value> </property> <!-- 此屬性可省略,默認值就是/hbase --> <property> <name>zookeeper.znode.parent</name> <value>/hbase</value> </property> </configuration>
修改文件
[hadoop@node01 conf]$ vim regionservers
指定HBase集群的從節點;原內容清空,添加如下三行
node01 node02 node03
創建back-masters配置文件,里邊包含備份HMaster節點的主機名,每個機器獨占一行,實現HMaster的高可用
[hadoop@node01 conf]$ vim backup-masters
將node01上的HBase安裝包,拷貝到其他機器上
[hadoop@node01 conf]$ cd /kkb/install [hadoop@node01 install]$ scp -r hbase-1.2.0-cdh6.14.2/ node02:$PWD [hadoop@node01 install]$ scp -r hbase-1.2.0-cdh6.14.2/ node03:$PWD
**<font color='red'>注意:三臺機器</font>**均做如下操作
因為HBase集群需要讀取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我們==三臺機器==都要執行以下命令,在相應的目錄創建這兩個配置文件的軟連接
ln -s /kkb/install/hadoop-2.6.0-cdh6.14.2/etc/hadoop/core-site.xml /kkb/install/hbase-1.2.0-cdh6.14.2/conf/core-site.xml ln -s /kkb/install/hadoop-2.6.0-cdh6.14.2/etc/hadoop/hdfs-site.xml /kkb/install/hbase-1.2.0-cdh6.14.2/conf/hdfs-site.xml
執行完后,出現如下效果,以node01為例 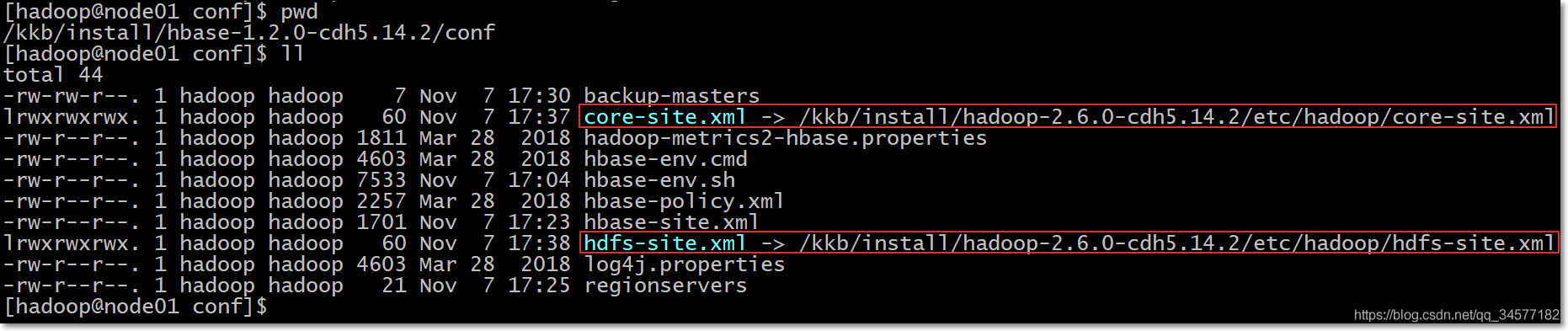
**<font color='red'>注意:三臺機器</font>**均執行以下命令,添加環境變量
sudo vim /etc/profile
文件末尾添加如下內容
export HBASE_HOME=/kkb/install/hbase-1.2.0-cdh6.14.2 export PATH=$PATH:$HBASE_HOME/bin
重新編譯/etc/profile,讓環境變量生效
source /etc/profile
<font color='red'>需要提前啟動HDFS及ZooKeeper集群</font>
第一臺機器==node01==(HBase主節點)執行以下命令,啟動HBase集群
[hadoop@node01 ~]$ start-hbase.sh
啟動完后,jps查看HBase相關進程
node01、node02上有進程HMaster、HRegionServer
node03上有進程HRegionServer
警告提示:HBase啟動的時候會產生一個警告,這是因為jdk7與jdk8的問題導致的,如果linux服務器安裝jdk8就會產生這樣的一個警告

可以注釋掉所有機器的hbase-env.sh當中的
“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 來解決這個問題。
不過警告不影響我們正常運行,可以不用解決
我們也可以執行以下命令,單節點啟動相關進程
#HMaster節點上啟動HMaster命令 hbase-daemon.sh start master #啟動HRegionServer命令 hbase-daemon.sh start regionserver
瀏覽器頁面訪問
http://node01:60010
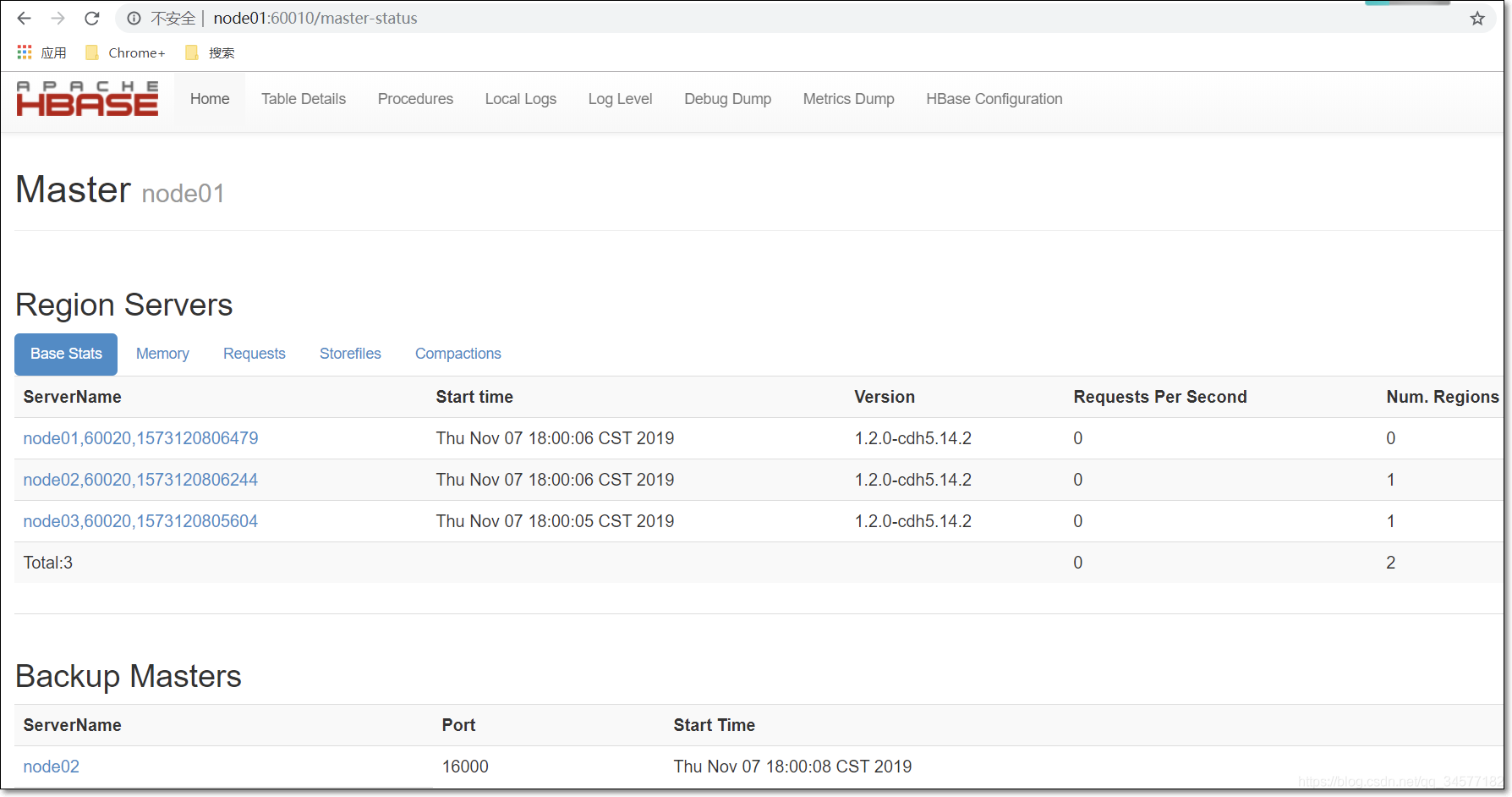
停止HBase集群的正確順序
node01上運行
[hadoop@node01 ~]$ stop-hbase.sh
若需要關閉虛擬機,則還需要關閉ZooKeeper、Hadoop集群
到此,關于“大數據數據庫HBase的集群安裝部署方法”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





