溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Kubernetes日志采集與監控告警知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Kubernetes日志采集與監控告警知識點有哪些”吧!
日志采集場景
日志采集場景主要分為以下四種:
集群核心組件日志:
審計需要 kube-apiserver 日志,診斷調度需要 kube-scheduler 日志,接入層流量分析需要 Ingress 日志。
主機內核日志:
內核日志可以用于幫助開發及運維同學診斷影響節點穩定的異常,如:文件系統異常,網絡棧異常,設備驅動異常等。
應用運行時日志:
Docker 是最常見的容器運行時,可以利用 Docker 和 Kubelet 日志排查 Pod 創建和啟動失敗等問題。
業務應用日志:
通過分析業務的運行日志分析和觀察業務狀態,診斷異常。
日志采集指標
Kubernetes 對容器日志的期望處理方式為:集群級日志處理(cluster-level-logging)
即:與容器、Pod、節點生命周期完全無關。
對于一個容器,當應用將日志輸出到 stdout 和 stderr 后,docker 默認將這些日志輸出到宿主機上一個 JSON 文件中。
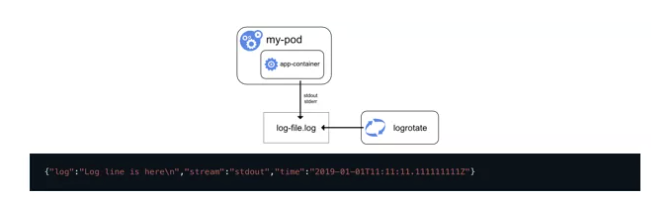

日志采集方式
Kubernetes 本身并不會對用戶進行任何的日志搜集工作。為了實現集群級日志處理,需要在集群前,提前對日志采集管理進行方案規劃。
Kubernetes 本身推薦3種日志方案。
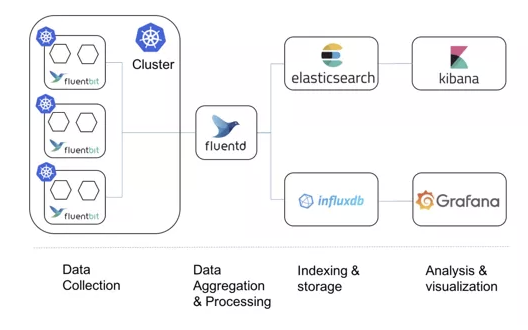
日志采集方式1:使用節點級日志代理
核心是 logging-agent (fluentd,etc );
Logging-agent 以 DaemonSet 方式運行在節點上;
掛載宿主機上的容器日志目錄;
轉發日志至后端存儲(ElasticSearch, etc);
優點:對應用和Pod完全無侵入,一個節點僅需部署一個 agent。
缺點:要求應用日志直接輸出至容器的 stdout 和 stderr。
日志采集方式2:使用 sidecar 容器和日志代理
容器全部或部分日志輸出到文件
一個或多個 sidecar 容器將應用程序日志傳送到自己的 stdout 和 stderr。

優點:能夠繼續使用日志采集方式1。
缺點:成倍增加磁盤占用,造成浪費。(應用和sidecar容器寫入兩份相同日志文件)
日志采集方式3:使用具有日志代理功能的 sidecar 容器
相當于將 logging-agent 直接集成進 Pod。
應用和輸出日志至 stdout&stderr 或文件。
Logging-agent 的輸入源為應用日志文件。
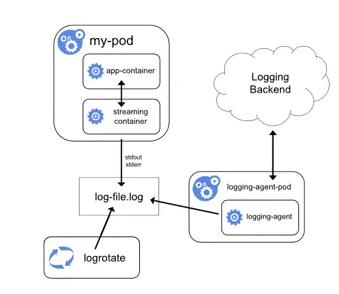
優點:部署簡單,對宿主機友好。
缺點:1. Sidecar 容器可能消耗較多資源,甚至拖掛應用容器。
2. 無法使用 kubectl logs 命令查看容器日志。
總結:
實現集群級日志采集的三種方式:
使用節點級日志代理。
使用 sidecar 容器和日志代理。
使用具有日志代理功能的 sidecar 容器。
建議:使用方案1,將應用日志輸出到 stdout&stderr,通過宿主機上直接部署logging-agent 的方式集中處理日志。
管理簡單。
可以使用 kubectl logs 命令查看日志。
宿主機本身可能已有 rstlogd 等成熟日志收集組件可使用。
選型推薦
監控場景
從監控類型劃分,可分為以下幾個場景:
資源監控:
CPU,內存,網絡等資源類指標,常以數值,百分比為單位進行統計,是最常見的資源監控方式。
性能監控:
應用的內部監控。通常是 Hock 機制在虛擬機層,字節碼執行層隱式回調,或者在應用層顯式注入,獲取更深層次的監控指標,常用來應用診斷與調優。
比如 Jvm 通過 Hock 機制,拿到類似 Jvm 里面的垃圾回收的次數,各種內存帶的分布以及網絡連接數的一些指標。通過這樣的方式來進行應用的診斷與調優。
安全監控:
針對安全進行一系列監控策略,例如越權管理,安全漏洞掃描等。
事件監控:
Kubernetes 中特有的監控方式,貼合 Kubernetes 設計理念,作為常規監控方案的補充。
為什么說事件監控貼合 Kubernetes 設計理念呢?這是因為 Kubernetes 其中一個設計理念就是基于狀態機的狀態轉換。從正常狀態轉換成另一個狀態的時候,會發生一個 Normal 級別的事件(也就是正常的事件)而從一個正常狀態轉換成異常狀態時,平臺會觸發一個 Warning 級別(也就是警告級別的事件)通常,Warning 級別的事件是我們關心的事件。
而事件監控就可以把 Normal 級別的事件或 Warning 級別的事件離線存儲到數據中心,然后通過數據中心的分析與報警,將相應的異常通過短信,郵件的方式暴露,彌補常規監控的弊端。
Prometheus 的起源及現狀
Prometheus 與 Kubernetes 一樣,來自于 Borg 體系。原型叫做 BorgMon,是與Borg同時誕生的內部監控系統。而Prometheus項目發起的原因也與Kubernetes 類似,希望通過對用戶更友好的方式,將 Google 內部系統的設計理念傳遞給開發者和用戶。
Kubernetes 監控體系曾經非常繁雜,但今天已經演變成了以 Prometheus 為核心的一套統一的方案。
Prometheus 的架構與工作方式

Prometheus 指標來源
宿主機的監控數據:需要借助 Node Exporter 向外暴露; Exporter 代替被監控對象來向 Prometheus 暴露可以被抓取的指標信息。
Kubernetes 組件如 APIServer, kubelet 等的/metrics AP:除CPU,內存外,還包括各個組件的核心監控指標。
Kubernetes 核心的監控數據:包括Pod、Node、容器、Service等主要核心概念的 metrics,其中容器相關的指標來源于 kubectl 內置的 cAdvisor 服務。
Prometheus 特點
簡潔強大的接入標準。只要實現 Promethus Client 接口,就可以直接實現數據的采集。
多種數據采集方式。包括:在線,離線,push, pull 聯邦的方式進行數據采集。
和 Kubernetes完 全兼容。
豐富的插件機制和生態。
Prometheus Operator 助力。使 Prometheus 的運維實現自動化。
感謝各位的閱讀,以上就是“Kubernetes日志采集與監控告警知識點有哪些”的內容了,經過本文的學習后,相信大家對Kubernetes日志采集與監控告警知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





