溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Hadoop的ResourceManager怎么恢復”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
當ResourceManager 掛掉重啟后,為了使之前的任務能夠繼續執行,而不是重新執行。勢必需要yarn記錄應用運行過程的狀態。
運行狀態可以存儲在
ZooKeeper
FileSystem 比如hdfs
LevelDB
使用zookeeper做為狀態存儲的典型配置為
<property> <description>Enable RM to recover state after starting. If true, then yarn.resourcemanager.store.class must be specified</description> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <description>The class to use as the persistent store.</description> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <description>Comma separated list of Host:Port pairs. Each corresponds to a ZooKeeper server (e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002") to be used by the RM for storing RM state. This must be supplied when using org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore as the value for yarn.resourcemanager.store.class</description> <name>hadoop.zk.address</name> <value>127.0.0.1:2181</value> </property>
基于zookeeper實現active 和standby 的多個ResourceManager之間的自動故障切換。 active Resource Manager只能有一個,而standby 可以有多個
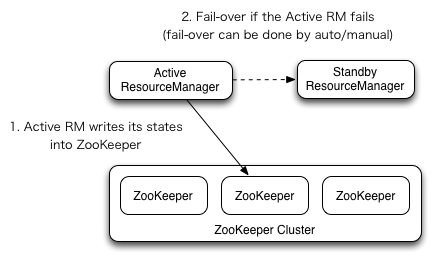
為了防止故障自動轉移時的腦裂,推薦上面的ResourceManager recovery 狀態存儲使用也使用zk。 同時關閉zk的zookeeper.DigestAuthenticationProvider.superDigest配置,避免zk的管理員訪問到YARN application/user credential information
一個demo配置如下
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>master1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>master2:8088</value> </property> <property> <name>hadoop.zk.address</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property>
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
基于Label,將一個Yarn管理的集群,劃分為多個分區。不同的queue可以使用不同的分區。
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
對Node Manager定義一組屬性值,使得應用程序能夠基于這些屬性值,來選擇Node Mananger, 并將其應用的container部署到上面
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeAttributes.html
集群中運行應用的application master 需要提供一些web ui給ResourceManager, 以便其統一管理。但集群中可能有惡意應用,提供了具有安全風險的web ui. 為了降低安全風險,yarn 使用一個名為Web Application Proxy的應用。擁有接管Application Master提供給的web ui鏈接,將請求中的cookies 進行剝離,同時將不安全的鏈接標記出來。
默認情況下Web Application Proxy 是作為Resource Manager的一部分啟動。不需要單獨配置。如果要單獨部署,需要額外配置。 文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WebApplicationProxy.html
能夠存儲和查詢當前、歷史的應用執行信息。TimeLine Server中的存儲數據結構為
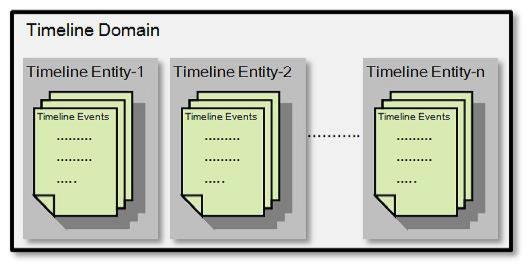
timeline Domain 對應一個用戶的應用列表
Time Entity 定義一個應用
Timeline Events定義該應用的執行事件,比如應用啟動,應用執行,應用結束等
Timeline Server分為V1和V2版本,V1版本將數據存儲在levelDb中,v2版將數據存儲在hbase中
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/TimelineServer.html
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html
yarn為了保證應用的運行安全,有一系列的機制先限制應用的權限之類的
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YarnApplicationSecurity.html
前面說了ResourceMananger 需要重啟后,能從原地繼續執行任務。Node Mananger在掛掉重啟后,也需要有相應的恢復特性。 其具體的配置,參見文檔。
文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeManager.html
Node Mananger的健康檢查服務,其提供兩種健康檢查器
Disk Checker 檢查node manager的磁盤健康狀況,并基于此上報給Resource Manager
External Health Script 管理員可以指定一些自定義的健康檢查腳本,供Node Manager的 Health Checker Service調用
yarn使用linux的CGroups實現資源隔離和控制,相關配置見文檔: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeManagerCgroups.html
將各應用container 限制在提交他的用戶權限下,不同用戶提交的應用container 不能訪問彼此的文件、文件夾。具體配置 文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/SecureContainer.html
有兩種方式:
normal 直接把要移除的節點從集群中摘除
Gracefully 等待節點上的任務執行完畢后摘除 文檔:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
yarn一般只在對應的Node manager有資源時,才會將一個任務對應的container 分配到該NM. 但開啟Opportunistic Containers后,即便對應的node manager沒有資源,也會將contaienr 分配到NM,等到NM空閑時,馬上開始執行,是為機會主義者。這在一定程度能提高集群的資源利用率。 文檔:
部署用戶。按照Hadoop官方的建議。yarn相關組件,使用yarn用來管理 
啟動RM
$HADOOP_HOME/bin/yarn --daemon start resourcemanager
啟動NM
$HADOOP_HOME/bin/yarn --daemon start nodemanager
啟動proxyServer
$HADOOP_HOME/bin/yarn --daemon start proxyserver
切換到mapred用戶下,啟動historyserver
$HADOOP_HOME/bin/mapred --daemon start historyserver
yarn本身由多個組件組成,且有些組件還有多個節點,比如nodemanager,一次啟動去到多個機器上執行是件很繁瑣的事情。hadoop發型包,提供了sbin/start-yarn.sh 和 sbin/stop-yarn.sh兩個腳本去啟停yarn相關的所有組件:比如nodemanager、resourcemanager、proxyserver 。
他實現的原理是,基于hadoop安裝包中的/opt/hadoop-3.2.1/etc/hadoop/workers文件,去登錄到相應的機器,完成組件的執行。workers中定義了所有datanode的機器host。 登錄方式是基于SSH的免密登錄方式,具體配置參見:https://www.cnblogs.com/niceshot/p/13019823.html
如果發起腳本執行的機器,本身也需要部署一個nodemanager。那么他需要配置自己對自己的SSH免密登錄
通yarn-site.xml , 腳本已經可以知道resource manager的組件機器。所以workers文件中,只需要設置所有的node manager的機器host
一般yarn的node manager會跟hdfs的 datanode部署在一起,所以hdfs的批量啟停,也是用的這個workers文件。
但上面說的$HADOOP_HOME/bin/mapred --daemon start historyserver不屬于,只屬于mapreduce,所以還是要單獨啟停,通過yarn的相關腳本是不能管理它的。之所以將這個historyserver放到yarn的文檔中來寫,是為了偷懶,沒單獨搞一個mr的wend
在yarn的管理界面,發現提交的sql,執行有以下錯誤
yarn錯誤 錯誤: 找不到或無法加載主類 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
問題原因是,yarn的類路徑有問題。通過hadoop官方的yarn-default.xml文件得知,yarn加載的類路徑配置yarn.application.classpath的默認值為
$HADOOP_CONF_DIR, $HADOOP_COMMON_HOME/share/hadoop/common/*, $HADOOP_COMMON_HOME/share/hadoop/common/lib/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/*, $HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*, $HADOOP_YARN_HOME/share/hadoop/yarn/*, $HADOOP_YARN_HOME/share/hadoop/yarn/lib/* For Windows: %HADOOP_CONF_DIR%, %HADOOP_COMMON_HOME%/share/hadoop/common/*, %HADOOP_COMMON_HOME%/share/hadoop/common/lib/*, %HADOOP_HDFS_HOME%/share/hadoop/hdfs/*, %HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*, %HADOOP_YARN_HOME%/share/hadoop/yarn/*, %HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*
路徑中的許多環境變量都沒有配置。解決辦法有2
將對應的環境變量配置上,以使yarn的默認配置能夠正常加載上。推薦這種
使用hadoop classpath命令,看下hadoop使用的類路徑都有哪些,將其拷貝出來,在yarn-site.xml中配置,舉例
<property> <name>yarn.application.classpath</name> <value>/opt/hadoop-3.2.1/etc/hadoop:/opt/hadoop-3.2.1/share/hadoop/common/lib/*:/opt/hadoop-3.2.1/share/hadoop/common/*:/opt/hadoop-3.2.1/share/hadoop/hdfs:/opt/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.1/share/hadoop/hdfs/*:/opt/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.1/share/hadoop/mapreduce/*:/opt/hadoop-3.2.1/share/hadoop/yarn:/opt/hadoop-3.2.1/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.1/share/hadoop/yarn/*</value> </property> ``` ### 錯誤2 通過historyserver, 在Mapreduce階段,看到異常
org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at
原因,這是因為mr使用了mapreduce_shuffle輔助服務,但yarn沒有配置。 解決辦法,同樣是修改yarn-site.xml,在其中加入以下配置
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
ontainer [pid=26153,containerID=container_e42_1594730232763_0121_02_000006] is running 598260224B beyond the 'VIRTUAL' memory limit. Current usage: 297.5 MB of 1 GB physical memory used; 2.7 GB of 2.1 GB virtual memory used. Killing container. Dump of the process-tree for container_e42_1594730232763_0121_02_000006 : |- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
錯誤的意思是,yarn分配給container的虛擬內存,超過了限制。原因是,一個container使用的內存,除了物理內存,還可以使用操作系統的虛擬內存,也即硬盤。
container分為兩種類型,map 和reduce。 決定map的container的物理內存大小為mapreduce.map.memory.mb 決定reduce的物理內存為mapreduce.reduce.memory.mb 決定map container所能申請的虛擬內存大小的公式是:mapreduce.map.memory.mb * yarn.nodemanager.vmem-pmem-ratio 決定reduce container所能申請的虛擬內存帶下是公式是:mapreduce.reduce.memory.mb * yarn.nodemanager.vmem-pmem-ratio。
所以要解決虛擬內存超限有兩個辦法:
增大container的物理內存大小。即增大mapreduce.map.memory.mb 或 mapreduce.reduce.memory.mb
增大虛擬內存申請的比率yarn.nodemanager.vmem-pmem-ratio
“Hadoop的ResourceManager怎么恢復”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





