溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
??在hadoop2.x之前,在HDFS 集群中NameNode 存在單點故障 (SPOF:A Single Point of Failure)。對于只有一個 NameNode 的集群,如果 NameNode 機器出現故障(比如宕機或是軟件、硬件升級),那么整個集群將無法使用,必須等到 NameNode 重新啟動,之后才能對外提供服務,這個方式在生成環境中是絕對不允許出現的。
??HDFS 的 HA:通過配置 Active/Standby 兩個 NameNodes 實現在集群中對 NameNode 的熱備來解決上述問題。如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將 NameNode 很快的切換到另外一臺機器。
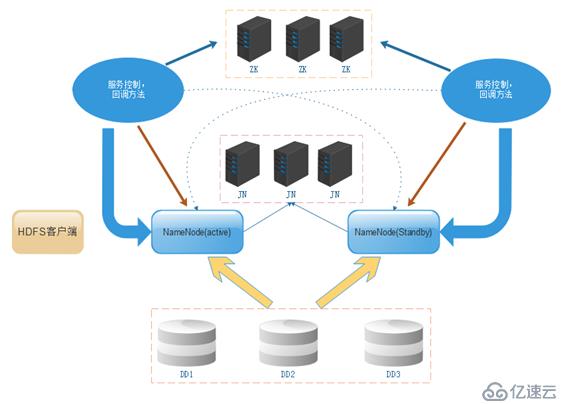
解釋(數據一致以及持久化問題):
搭建集群前的準備:https://blog.51cto.com/14048416/2341450
zookeeper集群的搭建:https://blog.51cto.com/14048416/2336178
[hadoop@hadoop01 ~]$tar -zxvf hadoop-2.6.5-centos-6.7.tar.gz -C /home/hadoop/apps/
hadoo-env.sh:加入:export JAVA_HOME= /usr/local/jdk1.8.0_73
core-site.xml:
<configuration>
<!-- 指定 hdfs 的 nameservice 為 myha01 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://myha01/</value>
</property>
<!-- 指定 hadoop 工作目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
</property>
<!-- 指定 zookeeper 集群訪問地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>hdfs-site.xml:
<configuration>
<!-- 指定副本數 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定 hdfs 的 nameservice 為 myha01,需要和 core-site.xml 中保持一致-->
<property>
<name>dfs.nameservices</name>
<value>myha01</value>
</property>
<!-- myha01 下面有兩個 NameNode,分別是 nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.myha01</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.myha01.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.myha01.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定 NameNode 的 edits 元數據在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/myha01</value>
</property>
<!-- 指定 JournalNode 在本地磁盤存放數據的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata</value>
</property>
<!-- 開啟 NameNode 失敗自動切換 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失敗自動切換實現方式 -->
<!-- 此處配置在安裝的時候切記檢查不要換行-->
<property>
<name>dfs.client.failover.proxy.provider.myha01</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverPr
oxyProvider</value>
</property>
<!-- 配置隔離機制方法,多個機制用換行分割,即每個機制暫用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔離機制時需要 ssh 免登陸 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔離機制超時時間 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>mapred-site.xml:
<configuration>
<!-- 指定 mr 框架為 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 設置 mapreduce 的歷史服務器地址和端口號 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property>
<!-- mapreduce 歷史服務器的 web 訪問地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>
</configuration>yarn-site.xml:
<configuration>
<!-- 開啟 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定 RM 的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分別指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!-- 要運行 MapReduce 程序必須配置的附屬服務 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 開啟 YARN 集群的日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- YARN 集群的聚合日志最長保留時長 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 啟用自動恢復 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的狀態信息存儲在 zookeeper 集群上-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
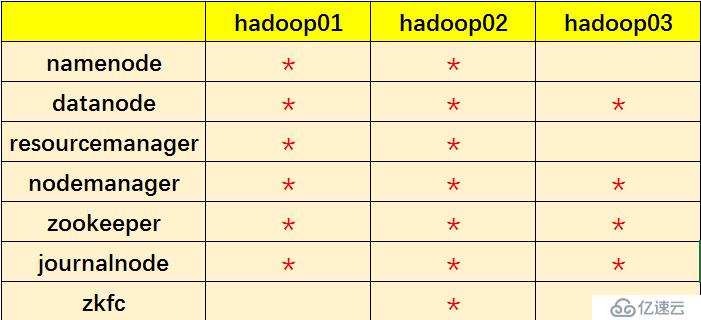
</configuration>slaves:
hadoop01
hadoop02
hadoop03[hadoop@hadoop01 apps]$scp -r hadoop-2.6.5 hadoop@hadoop02:$PWD
[hadoop@hadoop01 apps]$scp -r hadoop-2.6.5 hadoop@hadoop03:$PWD
[hadoop@hadoop01 apps]$ vi ~/.bashrc
添加兩行:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[hadoop@hadoop01 apps]$ source ~/.bashrc
先啟動 zookeeper 集群:
啟動:zkServer.sh start
檢查啟動是否正常:zkServer.sh status
啟動 journalnode 進程:
[hadoop@hadoop01 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop02 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop03 ~]$ hadoop-daemon.sh start journalnode
然后用 jps 命令查看是否各個 datanode 節點上都啟動了 journalnode 進程
在第一個 namenode 上執行格式化操作:
[hadoop@hadoop01 ~]$ hadoop namenode -format
然后會在 core-site.xml 中配置的臨時目錄中生成一些集群的信息把他拷貝的第二個 namenode 的相同目錄下
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata/</value>
兩個 namenode 節點該目錄中的數據結構是一致的
[hadoop@hadoop01 ~]$ scp -r ~/data/hadoopdata/ hadoop03:~/data
或者在另一個namenode節點上使用:hadoop namenode -bootstrapStandby
格式化 ZKFC(在一臺集群上格式化即可):
[hadoop@hadoop01 ~]$ hdfs zkfc -formatZK
啟動 HDFS:
[hadoop@hadoop01 ~]$ start-dfs.sh
啟動 YARN:
[hadoop@hadoop01 ~]$ start-yarn.sh
若備用節點的 resourcemanager 沒有啟動起來,則手動啟動起來:
[hadoop@hadoop02 ~]$ yarn-daemon.sh start resourcemanager
查看各主節點的狀態
HDFS:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
YARN:
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
1.手動殺死active的namenode,看看集群的狀況
2.手動殺死active的resourcemanager,看看集群的狀況
3.在上傳文件時,殺死namenode,查看集群狀況
4.在執行任務時,殺死resourcemanager,查看集群狀態
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





