溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Fluid下如何自定義彈性伸縮,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
隨著越來越多的大數據和AI等數據密集應用開始部署和運行在Kubernetes環境下,數據密集型應用計算框架的設計理念和云原生靈活的應用編排的分歧,導致了數據訪問和計算瓶頸。云原生數據編排引擎Fluid通過數據集的抽象,利用分布式緩存技術,結合調度器,為應用提供了數據訪問加速的能力。
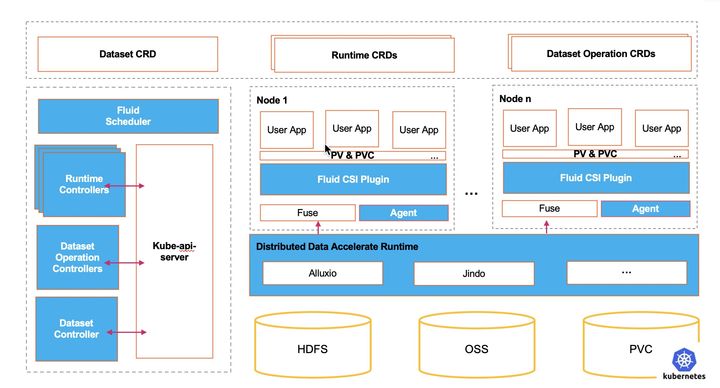
彈性伸縮作為Kubernetes的核心能力之一,但它一直是圍繞這無狀態的應用負載展開。而Fluid提供了分布式緩存的彈性伸縮能力,可以靈活擴充和收縮數據緩存。 它基于Runtime提供了緩存空間、現有緩存比例等性能指標, 結合自身對于Runtime資源的擴縮容能力,提供數據緩存按需伸縮能力。
這個能力對于互聯網場景下大數據應用非常重要,由于多數的大數據應用都是通過端到端流水線來實現的。而這個流水線包含以下幾個步驟:
數據提取,利用Spark,MapReduce等大數據技術對于原始數據進行預處理
模型訓練,利用第一階段生成特征數據進行機器學習模型訓練,并且生成相應的模型
模型評估,通過測試集或者驗證集對于第二階段生成模型進行評估和測試
模型推理,第三階段驗證后的模型最終推送到線上為業務提供推理服務
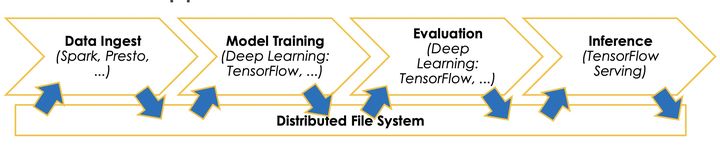
可以看到端到端的流水線會包含多種不同類型的計算任務,針對每一個計算任務,實踐中會有合適的專業系統來處理(TensorFlow,PyTorch,Spark, Presto);但是這些系統彼此獨立,通常要借助外部文件系統來實現把數據從一個階段傳遞到下一個階段。但是頻繁的使用文件系統實現數據交換,會帶來大量的 I/O 開銷,經常會成為整個工作流的瓶頸。
而Fluid對于這個場景非常適合,用戶可以創建一個Dataset對象,這個對象有能力將數據分散緩存到Kubernetes計算節點中,作為數據交換的介質,這樣避免了數據的遠程寫入和讀取,提升了數據使用的效率。但是這里的問題是臨時數據緩存的資源預估和預留。由于在數據生產消費之前,精確的數據量預估是比較難滿足,過高的預估會導致資源預留浪費,過低的預估會導致數據寫入失敗可能性增高。還是按需擴縮容對于使用者更加友好。我們希望能夠達成類似page cache的使用效果,對于最終用戶來說這一層是透明的但是它帶來的緩存加速效果是實實在在的。
我們通過自定義HPA機制,通過Fluid引入了緩存彈性伸縮能力。彈性伸縮的條件是當已有緩存數據量達到一定比例時,就會觸發彈性擴容,擴容緩存空間。例如將觸發條件設置為緩存空間占比超過75%,此時總的緩存空間為10G,當數據已經占滿到8G緩存空間的時候,就會觸發擴容機制。
下面我們通過一個例子幫助您體驗Fluid的自動擴縮容能力。
推薦使用Kubernetes 1.18以上,因為在1.18之前,HPA是無法自定義擴縮容策略的,都是通過硬編碼實現的。而在1.18后,用戶可以自定義擴縮容策略的,比如可以定義一次擴容后的冷卻時間。
1.安裝jq工具方便解析json,在本例子中我們使用操作系統是centos,可以通過yum安裝jq
yum install -y jq
2.下載、安裝Fluid最新版
git clone https://github.com/fluid-cloudnative/fluid.git cd fluid/charts kubectl create ns fluid-system helm install fluid fluid
3.部署或配置 Prometheus
這里通過Prometheus對于AlluxioRuntime的緩存引擎暴露的 Metrics 進行收集,如果集群內無 prometheus:
$ cd fluid $ kubectl apply -f integration/prometheus/prometheus.yaml
如集群內有 prometheus,可將以下配置寫到 prometheus 配置文件中:
scrape_configs: - job_name: 'alluxio runtime' metrics_path: /metrics/prometheus kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_label_monitor] regex: alluxio_runtime_metrics action: keep - source_labels: [__meta_kubernetes_endpoint_port_name] regex: web action: keep - source_labels: [__meta_kubernetes_namespace] target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_label_release] target_label: fluid_runtime replacement: $1 action: replace - source_labels: [__meta_kubernetes_endpoint_address_target_name] target_label: pod replacement: $1 action: replace
4.驗證 Prometheus 安裝成功
$ kubectl get ep -n kube-system prometheus-svc NAME ENDPOINTS AGE prometheus-svc 10.76.0.2:9090 6m49s $ kubectl get svc -n kube-system prometheus-svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus-svc NodePort 172.16.135.24 <none> 9090:32114/TCP 2m7s
如果希望可視化監控指標,您可以安裝Grafana驗證監控數據,具體操作可以參考文檔
5.部署 metrics server
檢查該集群是否包括metrics-server, 執行kubectl top node有正確輸出可以顯示內存和CPU,則該集群metrics server配置正確
kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% 192.168.1.204 93m 2% 1455Mi 10% 192.168.1.205 125m 3% 1925Mi 13% 192.168.1.206 96m 2% 1689Mi 11%
否則手動執行以下命令
kubectl create -f integration/metrics-server
6.部署 custom-metrics-api 組件
為了基于自定義指標進行擴展,你需要擁有兩個組件。第一個組件是從應用程序收集指標并將其存儲到Prometheus時間序列數據庫。第二個組件使用收集的度量指標來擴展Kubernetes自定義metrics API,即 k8s-prometheus-adapter。第一個組件在第三步部署完成,下面部署第二個組件:
如果已經配置了custom-metrics-api,在adapter的configmap配置中增加與dataset相關的配置
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitoring
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"Cluster_(CapacityTotal|CapacityUsed)",fluid_runtime!="",instance!="",job="alluxio runtime",namespace!="",pod!=""}'
seriesFilters:
- is: ^Cluster_(CapacityTotal|CapacityUsed)$
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pods
fluid_runtime:
resource: datasets
name:
matches: "^(.*)"
as: "capacity_used_rate"
metricsQuery: ceil(Cluster_CapacityUsed{<<.LabelMatchers>>}*100/(Cluster_CapacityTotal{<<.LabelMatchers>>}))否則手動執行以下命令
kubectl create -f integration/custom-metrics-api/namespace.yaml kubectl create -f integration/custom-metrics-api
注意:因為custom-metrics-api對接集群中的Prometheous的訪問地址,請替換prometheous url為你真正使用的Prometheous地址。
檢查自定義指標
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "pods/capacity_used_rate",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "datasets.data.fluid.io/capacity_used_rate",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "namespaces/capacity_used_rate",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}7.提交測試使用的Dataset
$ cat<<EOF >dataset.yaml apiVersion: data.fluid.io/v1alpha1 kind: Dataset metadata: name: spark spec: mounts: - mountPoint: https://mirrors.bit.edu.cn/apache/spark/ name: spark --- apiVersion: data.fluid.io/v1alpha1 kind: AlluxioRuntime metadata: name: spark spec: replicas: 1 tieredstore: levels: - mediumtype: MEM path: /dev/shm quota: 1Gi high: "0.99" low: "0.7" properties: alluxio.user.streaming.data.timeout: 300sec EOF $ kubectl create -f dataset.yaml dataset.data.fluid.io/spark created alluxioruntime.data.fluid.io/spark created
8.查看這個Dataset是否處于可用狀態, 可以看到該數據集的數據總量為2.71GiB, 目前Fluid提供的緩存節點數為1,可以提供的最大緩存能力為1GiB。此時數據量是無法滿足全量數據緩存的需求。
$ kubectl get dataset NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE spark 2.71GiB 0.00B 1.00GiB 0.0% Bound 7m38s
9.當該Dataset處于可用狀態后,查看是否已經可以從custom-metrics-api獲得監控指標
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/datasets.data.fluid.io/*/capacity_used_rate" | jq
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/datasets.data.fluid.io/%2A/capacity_used_rate"
},
"items": [
{
"describedObject": {
"kind": "Dataset",
"namespace": "default",
"name": "spark",
"apiVersion": "data.fluid.io/v1alpha1"
},
"metricName": "capacity_used_rate",
"timestamp": "2021-04-04T07:24:52Z",
"value": "0"
}
]
}10.創建 HPA任務
$ cat<<EOF > hpa.yaml apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: spark spec: scaleTargetRef: apiVersion: data.fluid.io/v1alpha1 kind: AlluxioRuntime name: spark minReplicas: 1 maxReplicas: 4 metrics: - type: Object object: metric: name: capacity_used_rate describedObject: apiVersion: data.fluid.io/v1alpha1 kind: Dataset name: spark target: type: Value value: "90" behavior: scaleUp: policies: - type: Pods value: 2 periodSeconds: 600 scaleDown: selectPolicy: Disabled EOF
首先,我們解讀一下從樣例配置,這里主要有兩部分一個是擴縮容的規則,另一個是擴縮容的靈敏度:
規則:觸發擴容行為的條件為Dataset對象的緩存數據量占總緩存能力的90%; 擴容對象為AlluxioRuntime, 最小副本數為1,最大副本數為4; 而Dataset和AlluxioRuntime的對象需要在同一個namespace
策略: 可以K8s 1.18以上的版本,可以分別針對擴容和縮容場景設置穩定時間和一次擴縮容步長比例。比如在本例子, 一次擴容周期為10分鐘(periodSeconds),擴容時新增2個副本數,當然這也不可以超過 maxReplicas 的限制;而完成一次擴容后, 冷卻時間(stabilizationWindowSeconds)為20分鐘; 而縮容策略可以選擇直接關閉。
11.查看HPA配置, 當前緩存空間的數據占比為0。遠遠低于觸發擴容的條件
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE spark AlluxioRuntime/spark 0/90 1 4 1 33s $ kubectl describe hpa Name: spark Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Wed, 07 Apr 2021 17:36:39 +0800 Reference: AlluxioRuntime/spark Metrics: ( current / target ) "capacity_used_rate" on Dataset/spark (target value): 0 / 90 Min replicas: 1 Max replicas: 4 Behavior: Scale Up: Stabilization Window: 0 seconds Select Policy: Max Policies: - Type: Pods Value: 2 Period: 600 seconds Scale Down: Select Policy: Disabled Policies: - Type: Percent Value: 100 Period: 15 seconds AlluxioRuntime pods: 1 current / 1 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from Dataset metric capacity_used_rate ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: <none>
12.創建數據預熱任務
$ cat<<EOF > dataload.yaml apiVersion: data.fluid.io/v1alpha1 kind: DataLoad metadata: name: spark spec: dataset: name: spark namespace: default EOF $ kubectl create -f dataload.yaml $ kubectl get dataload NAME DATASET PHASE AGE DURATION spark spark Executing 15s Unfinished
13.此時可以發現緩存的數據量接近了Fluid可以提供的緩存能力(1GiB)同時觸發了彈性伸縮的條件
$ kubectl get dataset NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE spark 2.71GiB 1020.92MiB 1.00GiB 36.8% Bound 5m15s
從HPA的監控,可以看到Alluxio Runtime的擴容已經開始, 可以發現擴容的步長為2
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE spark AlluxioRuntime/spark 100/90 1 4 2 4m20s $ kubectl describe hpa Name: spark Namespace: default Labels: <none> Annotations: <none> CreationTimestamp: Wed, 07 Apr 2021 17:56:31 +0800 Reference: AlluxioRuntime/spark Metrics: ( current / target ) "capacity_used_rate" on Dataset/spark (target value): 100 / 90 Min replicas: 1 Max replicas: 4 Behavior: Scale Up: Stabilization Window: 0 seconds Select Policy: Max Policies: - Type: Pods Value: 2 Period: 600 seconds Scale Down: Select Policy: Disabled Policies: - Type: Percent Value: 100 Period: 15 seconds AlluxioRuntime pods: 2 current / 3 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 3 ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from Dataset metric capacity_used_rate ScalingLimited False DesiredWithinRange the desired count is within the acceptable range Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: Dataset metric capacity_used_rate above target Normal SuccessfulRescale 6s horizontal-pod-autoscaler New size: 3; reason: Dataset metric capacity_used_rate above target
14.在等待一段時間之后發現數據集的緩存空間由1GiB提升到了3GiB,數據緩存已經接近完成
$ kubectl get dataset NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE spark 2.71GiB 2.59GiB 3.00GiB 95.6% Bound 12m
同時觀察HPA的狀態,可以發現此時Dataset對應的runtime的replicas數量為3, 已經使用的緩存空間比例capacity_used_rate為85%,已經不會觸發緩存擴容。
$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE spark AlluxioRuntime/spark 85/90 1 4 3 11m
16.清理環境
kubectl delete hpa spark kubectl delete dataset spark
以上是“Fluid下如何自定義彈性伸縮”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





