溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Elasticsearch 預處理的技巧示例分析,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
es可以根據_id字符串切分,再聚合統計嗎 比如:數據1、_id=C12345 數據2、_id=C12456 數據3、_id=C31268
通過es聚合統計 C1開頭的數量有2個 C3開頭的數據有1個
這個API怎么寫,有大佬指導下嗎?
插入的時候,能不能對原數據進行一定的轉化,再進行indexing
{
"headers":{
"userInfo":[
"{ \"password\": \"test\",\n \"username\": \"zy\"}"
]
}
}
這里面的已經是字符串了,能在數據插入階段把這個 json 轉成 object 么?
我想對一個list每個值后面都加一個字符:
比如 {"tag":["a","b","c"]} 這樣一個文檔 我想變成 {"tag":["a2","b2","c2"]} 這樣的,
各位有沒有試過用 foreach 和 script 結合使用?
「問題 1」:分析環節需要聚合統計,當然用painless script 也能實現,但數據量大,勢必有性能問題。
可以把數據處理前置,把前_id兩個字符提取出來,作為一個字段處理。
「問題 2」:寫入的時候期望做字符類型的轉換,把復雜的字符串轉換為格式化后的 Object 對象數據。
「問題 3」:數組類型數據全部規則化更新,當然 painless script 腳本也可以實現。
但是,在寫入環節處理,就能極大減輕后面分析環節的負擔。
以上三個問題,寫入前用 java 或者 python 寫程序處理,然后再寫入 Elasticsearch 也是一種方案。
但,如果要死磕一把,有沒有更好的方案呢?能否在寫入前進行數據的預處理呢?
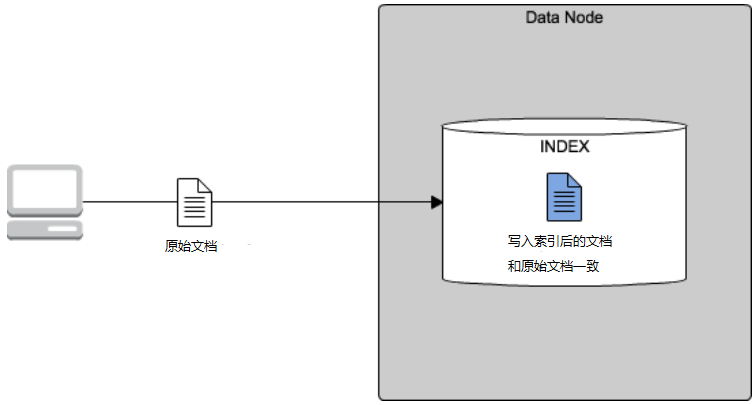
一般情況下,我們程序寫入數據或者從第三方數據源(Mysql、Oracle、HBase、Spark等)導入數據,都是原始數據張什么樣,直接批量同步 ES,寫入ES索引化的數據就是什么樣。如下圖所示:
如前所述的三個實戰問題,實際業務數據可能不見得是我們真正分析環節所需要的。
需要對這些數據進行合理的預處理后,才便于后面環節的分析和數據挖掘。
數據預處理的步驟大致拆解如下:
主要是為了去除 重復數據,去噪音(即干擾數據)以及填充缺省值。
將多個數據源的數據放在一個統一的數據存儲中。
將數據轉化成適合數據挖掘或分析的形式。
在 Elasticsearch 中,有沒有預處理的實現呢?
Elasticsearch的ETL利器——Ingest節點,已經將節點角色劃分、Ingest 節點作用,Ingest 實踐、Ingest 和 logstash 預處理優缺點對比都做了解讀。有相關盲點的同學,可以移步過去過一遍知識點。
Ingest 節點的本質——在實際文檔建立索引之前,使用 Ingest 節點對文檔進行預處理。Ingest 節點攔截批量索引和單個索引請求,應用轉換,然后將文檔傳遞回單個索引或批量索引API 寫入數據。
下面這張圖,比較形象的說明的 Elasticsearch 數據預處理的流程。
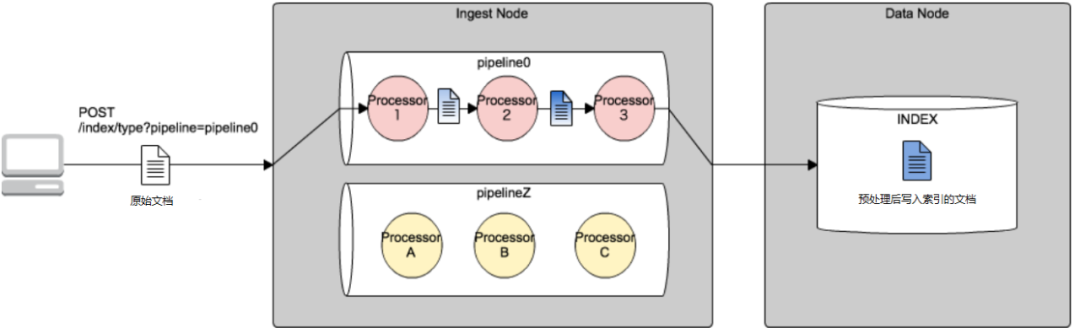
實際業務場景中,預處理步驟如下:
根據實際要處理的復雜數據的特點,有針對性的設置1個或者多個 pipeline (管道),上圖的粉紅和黃色部分。
寫入數據、更新數據或者 reindex 索引環節,指定要處理索引的 pipeline , 實際就是寫入索引與上面的 pipeline0 和 pipelineZ 關聯起來。
劃重點:Ingest 實現在實際文檔編制索引(索引化)之前對文檔進行預處理。
PUT _ingest/pipeline/split_id
{
"processors": [
{
"script": {
"lang": "painless",
"source": "ctx.myid_prefix = ctx.myid.substring(0,2)"
}
}
]
}
借助 script 處理器中的 substring 提取子串,構造新的前綴串字段,用于分析環節的聚合操作。
PUT _ingest/pipeline/json_builder
{
"processors": [
{
"json": {
"field": "headers.userInfo",
"target_field": "headers.userInfo.target"
}
}
]
}
借助 json 處理器做字段類型轉換,字符串轉成了 json。
PUT _ingest/pipeline/add_builder
{
"processors": [
{
"script": {
"lang": "painless",
"source": """
for (int i=0; i < ctx.tag.length;i++) {
ctx.tag[i]=ctx.tag[i]+"2";
}
"""
}
}
]
}
借助 script 處理器,循環遍歷數組,實現了每個數組字段內容的再填充。
篇幅原因,更詳細解讀參見:
https://github.com/mingyitianxia/deep_elasticsearch/blob/master/es_dsl_study/1.ingest_dsl.md
「方案 1」:數據原樣導入Elasticsearch,分析階段再做 painless 腳本處理。簡單粗暴。
導入一時爽,處理費大勁!
如前所述,script 處理能力有限,且由于 script 徒增性能問題煩惱。
不推薦使用。
「方案 2」:提前借助 Ingest 節點實現數據預處理,做好必要的數據的清洗(ETL) 操作,哪怕增大空間存儲(如新增字段),也要以空間換時間,為后續分析環節掃清障礙。
看似寫入變得復雜,實則必須。「以空間為分析贏取了時間」。
推薦使用。
默認情況下,所有節點都默認啟用 Ingest,因此任何節點都可以完成數據的預處理任務。
但是,當集群數據量級夠大,集群規模夠大后,建議拆分節點角色,和獨立主節點、獨立協調節點一樣,設置獨立專用的 Ingest 節點。
創建索引、創建模板、更新索引、reindex 以及 update_by_query 環節 都可以指定 pipeline。
PUT ms-test
{
"settings": {
"index.default_pipeline": "init_pipeline"
}
}
PUT _template/template_1
{
"index_patterns": ["te*", "bar*"],
"settings": {
"number_of_shards": 1,
"index.default_pipeline":"add_builder"
}
}
PUT /my_index/_settings
{
"index" : {
"default_pipeline" : "my_pipeline"
}
}
POST _reindex
{
"source": {
"index": "source"
},
"dest": {
"index": "dest",
"pipeline": "some_ingest_pipeline"
}
}
POST twitter/_update_by_query?pipeline=set-foo
上述內容就是Elasticsearch 預處理的技巧示例分析,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





