溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行kafka connector 監聽sqlserver的嘗試,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
之前拿canal監聽mysql的binlog并將消息遞給kafka topic,但是canal只能監聽mysql,假如數據庫是sqlserver\orcale\mongodb那么完全無能為力.看了一下網上的資料,主流是用kafka connect來監聽sqlserver,下面分享一下我嘗試的過程.
現在簡單說說,配置過程中涉及到kafka connector,confluent,kafka. kafka connector是kafka自帶特性,用來創建和管理數據流管道,是個和其它系統交換數據的簡單模型;
confluent是一家圍繞kafka做產品的公司,不但提供數據傳輸的系統,也提供數據傳輸的工具,內部封裝了kafka.在這里我們只用它下載kafka鏈接sqlserver的connector組件.
我使用的kafka是用CDH cloudera manager安裝的,因此kafka的bin目錄\配置目錄\日志什么的都不在一起,也沒有$KAFKA_HOME.雖然這次是測試功能,但是為了以后下載更多connector組件考慮,我還是下載了confluent.建議在官網下載,沒翻&墻,網速還可以.
confluent下載地址 https://www.confluent.io/download/ 選擇下面的Download Confluent Platform,填寫郵件地址和用途下載.
5.2版本下載地址: http://packages.confluent.io/archive/5.2/
在準備下載和解壓的位置,開始下載和解壓:
wget http://packages.confluent.io/archive/5.2/confluent-5.2.3-2.11.zip tar -zxvf confluent-5.2.3-2.11.zip confluent-5.2.3-2.11
解壓出來應該是有一下幾個文件夾(usr是我自己創建的,用來存儲用戶的配置文件和語句):

將CONFLUENT_HOME配置進環境變量里:
vi /etc/profile export CONFLUENT_HOME=/usr/software/confluent-5.2.3 export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME:$CONFLUENT_HOME/bin
路徑是我自己的,大家改成自己的文件路徑.
下載connector連接器組件,每個組件連接jdbc的配置文件都可能不一樣,注意看官方文檔.我選擇的是 debezium-connector-sqlserver .先進入bin目錄,能夠看到有confluent-hub 指令,我們靠它來下載組件.
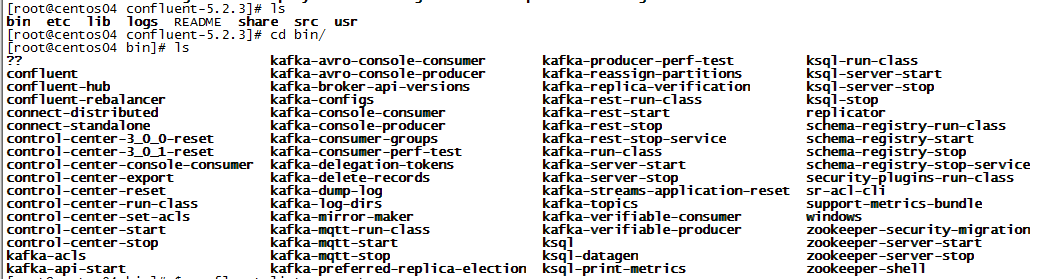
[root@centos04 bin]# confluent-hub install debezium/debezium-connector-sqlserver:latest The component can be installed in any of the following Confluent Platform installations: 1. /usr/software/confluent-5.2.3 (based on $CONFLUENT_HOME) 2. /usr/software/confluent-5.2.3 (where this tool is installed) Choose one of these to continue the installation (1-2): 2 Do you want to install this into /usr/software/confluent-5.2.3/share/confluent-hub-components? (yN) y^H Do you want to install this into /usr/software/confluent-5.2.3/share/confluent-hub-components? (yN) y Component's license: Apache 2.0 https://github.com/debezium/debezium/blob/master/LICENSE.txt I agree to the software license agreement (yN) y
輸入指令后先問你安裝組件位置,是$CONFLUENT_HOME目錄下還是confluent目錄下,再問你組件是否安裝在{$confluent}/share/confluent-hub-components這個默認位置,選擇n的話可以自己輸入文件位置,再問是否同意許可,以及是否更新組件.假如沒有特別需求的話,直接選擇y就可以了.
其它組件可以在https://www.confluent.io/hub/里面挑選,還有官方文檔教你如何配置,很重要.光看網上教程怎么做沒有理解為什么這么做很容易走彎路,根本不知道哪里做錯了.我看了很多篇都是一模一樣,用的組件是 Confluent MSSQL Connector .但是這個組件已經沒有了,換其它組件的話配置需要更改.我就在這里花費了很長時間.注意看官方文檔.
Debezium SQL Server的說明文檔地址:https://docs.confluent.io/current/connect/debezium-connect-sqlserver/index.html#sqlserver-source-connector
下載完成后就可以在{$confluent}/share/confluent-hub-components目錄下面看見下載好的組件了.接下來配置kafka.
進入kafka的配置目錄,kafka單獨安裝的話位置是$KAFKA_HOME/config,CDH版本的配置文件在/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist下面.不知道安裝位置的話直接搜文件名connect-distributed.properties.假如這都沒有那說明你的kafka可能版本太低,沒有這個特性.
修改其中的connect-distributed.properties文件.
## # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ## # This file contains some of the configurations for the Kafka Connect distributed worker. This file is intended # to be used with the examples, and some settings may differ from those used in a production system, especially # the `bootstrap.servers` and those specifying replication factors. # A list of host/port pairs to use for establishing the initial connection to the Kafka cluster. #kafka集群位置,需要配置 bootstrap.servers=centos04:9092,centos05:9092,centos06:9092 # unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs #group.id,默認都是connect-cluster,保持一致就行 group.id=connect-cluster # The converters specify the format of data in Kafka and how to translate it into Connect data. Every Connect user will # need to configure these based on the format they want their data in when loaded from or stored into Kafka key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter # Converter-specific settings can be passed in by prefixing the Converter's setting with the converter we want to apply # it to key.converter.schemas.enable=true value.converter.schemas.enable=true # Topic to use for storing offsets. This topic should have many partitions and be replicated and compacted. # Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. offset.storage.topic=connect-offsets offset.storage.replication.factor=3 offset.storage.partitions=1 # Topic to use for storing connector and task configurations; note that this should be a single partition, highly replicated, # and compacted topic. Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. config.storage.topic=connect-configs config.storage.replication.factor=3 # Topic to use for storing statuses. This topic can have multiple partitions and should be replicated and compacted. # Kafka Connect will attempt to create the topic automatically when needed, but you can always manually create # the topic before starting Kafka Connect if a specific topic configuration is needed. # Most users will want to use the built-in default replication factor of 3 or in some cases even specify a larger value. # Since this means there must be at least as many brokers as the maximum replication factor used, we'd like to be able # to run this example on a single-broker cluster and so here we instead set the replication factor to 1. status.storage.topic=connect-status status.storage.replication.factor=3 #status.storage.partitions=1 offset.storage.file.filename=/var/log/confluent/offset-storage-file # Flush much faster than normal, which is useful for testing/debugging offset.flush.interval.ms=10000 # These are provided to inform the user about the presence of the REST host and port configs # Hostname & Port for the REST API to listen on. If this is set, it will bind to the interface used to listen to requests. #rest.host.name= #kafka connector端口號,可以修改 rest.port=8083 # The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers. #rest.advertised.host.name= #rest.advertised.port= # Set to a list of filesystem paths separated by commas (,) to enable class loading isolation for plugins # (connectors, converters, transformations). The list should consist of top level directories that include # any combination of: # a) directories immediately containing jars with plugins and their dependencies # b) uber-jars with plugins and their dependencies # c) directories immediately containing the package directory structure of classes of plugins and their dependencies # Examples: # plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors, # Replace the relative path below with an absolute path if you are planning to start Kafka Connect from within a # directory other than the home directory of Confluent Platform. #組件位置,把confluent組件下載位置加上去 plugin.path=/usr/software/confluent-5.2.3/share/java/confluent-hub-client,,/usr/software/confluent-5.2.3/share/confluent-hub-client,/usr/software/confluent-5.2.3/share/confluent-hub-components
先創建使用connector要用到的特殊topic,避免在啟動kafka connector的時候創建失敗導致kafka connector啟動失敗.特殊topic有三個:
kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-offsets --replication-factor 3 --partitions 1 kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-configs --replication-factor 3 --partitions 1 kafka-topics --create --zookeeper 192.168.49.104:2181 --topic connect-status --replication-factor 3 --partitions 1
再進入kafka的bin目錄,CDH版本的是/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/lib/kafka/bin.
執行connect-distributed.sh指令:
sh connect-distributed.sh /opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-distributed.properties
說一點,CDH安裝的kafka在執行指令的時候會報錯找不到日志文件,原因是CDH安裝的kafka各個部分都不在一起.直接修改connect-distributed.sh ,把里面的地址寫死就好了.
vi connect-distributed.sh #修改的地方 base_dir=$(dirname $0) if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:/opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-log4j.properties" fi
這樣執行起來就沒有問題了.
以上執行的時候是在前臺執行,前臺停止退出的話kafka connector也就停止了,這種情況適合調試.在后臺運行需要加上 -daemon 參數.
sh connect-distributed.sh -daemon /opt/cloudera/parcels/CDH-6.3.0-1.cdh7.3.0.p0.1279813/etc/kafka/conf.dist/connect-distributed.properties
使用Debezium SQL Server來監聽的話需要開啟sqlserver的CDC功能.CDC功能要先開啟庫的捕獲,再開啟表的捕獲,才能監聽到表的變化.
我使用的是navicat來連接數據庫,大家用自己合適的工具來就可以了.
開啟庫的捕獲:
use database; EXEC sys.sp_cdc_enable_db
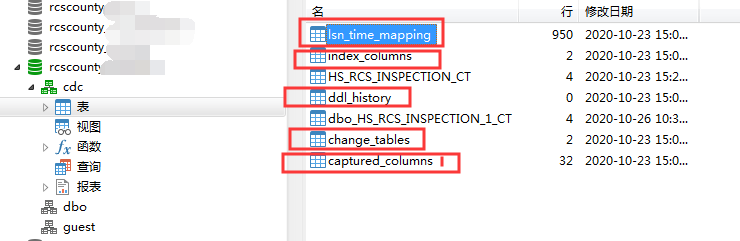
這一步后數據庫會多出一個叫cdc的模式,下面有5張表.
查詢哪些數據庫開啟了CDC功能:
select * from sys.databases where is_cdc_enabled = 1
啟用表的CDC功能:
use database; EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'table_name', @role_name = null;
查看哪些表啟用了CDC功能:
use database; select name, is_tracked_by_cdc from sys.tables where is_tracked_by_cdc = 1
以上就開啟了對表監聽的CDC功能.
當我們啟動KafkaConnector后,就能夠通過接口的形式來訪問和提交信息.
查看kafka connector信息:
[root@centos04 huishui]# curl -s centos04:8083 | jq
{
"version": "2.2.1-cdh7.3.0",
"commit": "unknown",
"kafka_cluster_id": "GwdoyDpbT5uP4k2CN6zbrw"
}8083是上面配置的端口號,同樣也可以通過web頁面來訪問.

查看安裝了哪些connector連接器:
[root@centos04 huishui]# curl -s centos04:8083 | jq
{
"version": "2.2.1-cdh7.3.0",
"commit": "unknown",
"kafka_cluster_id": "GwdoyDpbT5uP4k2CN6zbrw"
}
[root@centos04 huishui]# curl -s centos04:8083/connector-plugins | jq
[
{
"class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type": "sink",
"version": "10.0.2"
},
{
"class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"type": "sink",
"version": "5.5.1"
},
{
"class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"type": "source",
"version": "5.5.1"
},
{
"class": "io.debezium.connector.sqlserver.SqlServerConnector",
"type": "source",
"version": "1.2.2.Final"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "2.2.1-cdh7.3.0"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "2.2.1-cdh7.3.0"
}
]我安裝了很多,有io.debezium.connector.sqlserver.SqlServerConnector就說明沒問題.
查看當前運行的任務/Task:
[root@centos04 huishui]# curl -s centos04:8083/connectors | jq []
由于我們還沒有提交任何用戶配置,所以也就沒有任務,返回就是一個空的json.到這里說明kafka connector啟動成功,能夠正常進行用戶配置.接下來才是有關業務的操作,編寫一個用戶配置的json,通過接口進行提交:
#我選擇把用戶配置保存下來.由于我的kafka都不在一個文件夾下面,所以我把配置文件都存在confluent/usr中.其實存不存都無所謂的.按照官方文檔,我選擇存下來.
#當創建好kafka connector之后,會自動創建kafka topic.名稱為 ${server.name}.$tableName.debezium不能監聽單獨一張表,所有表都會有對應的topic.
cd $CONFLUENT
mkdir usr
cd usr
vi register-sqlserver.json
{
"name": "inventory-connector",
"config": {
"connector.class" : "io.debezium.connector.sqlserver.SqlServerConnector",
"tasks.max" : "1",
"database.server.name" : "server.name",
"database.hostname" : "localhost",
"database.port" : "1433",
"database.user" : "sa",
"database.password" : "password!",
"database.dbname" : "rcscounty_quannan",
"database.history.kafka.bootstrap.servers" : "centos04:9092",
"database.history.kafka.topic": "schema-changes.inventory"
}
}
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://centos04:8083/connectors/ -d @register-sqlserver.json提交失敗會有錯誤信息.看看錯誤信息是什么然后跟著改就可以了.當提交成功后,再查看當前運行的Task,就會出現有一個connector:
[root@centos04 huishui]# curl -s centos04:8083/connectors | jq [ "inventory-connector" ]
查看kafka topic:
kafka-topics --list --zookeeper centos04:2181
會看見kafka創建好了topic,假如沒有對應的topic,那么可能是connector在運行時出現了問題.查看當時創建的connector狀態:
[root@centos04 usr]# curl -s centos04:8083/connectors/inventory-connector/status | jq
{
"name": "inventory-connector",
"connector": {
"state": "RUNNING",
"worker_id": "192.168.49.104:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "192.168.49.104:8083"
}
],
"type": "source"
}我這個是運行良好的狀態.運行沒有問題,就開始監聽開啟了CDC功能的表對應的topic,看看是否能夠成功監聽表的改動:
kafka-console-consumer --bootstrap-server centos04:9092 --topic server.name.tableName
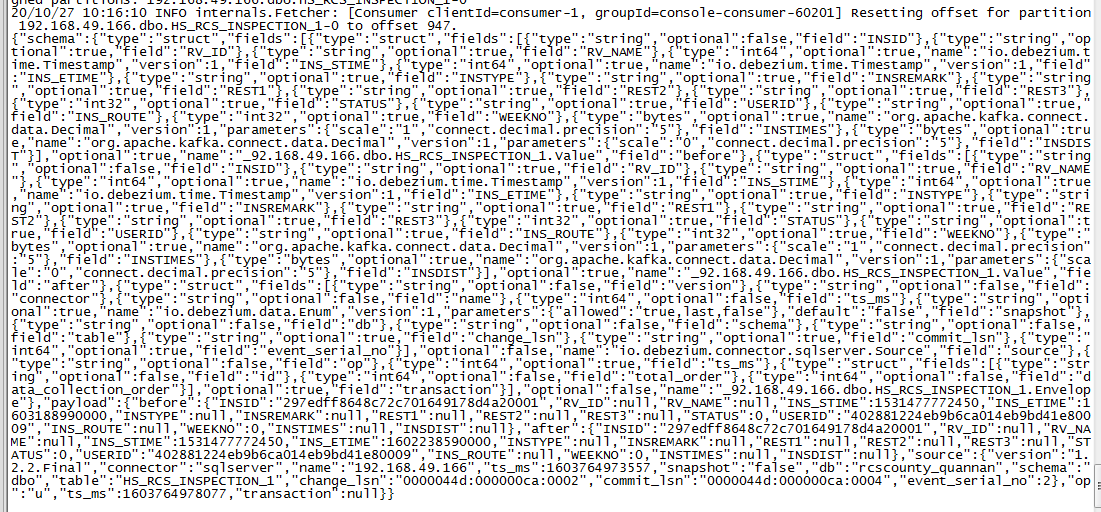
可以看到一次Debezium connector 創建的topic傳遞的消息非常多,可能需要修改kafka最大消息體.我之前設置的是9M,所以這里沒遇到問題.
Debezium 傳遞的數據庫變動,新增\修改\刪除\模式更改的json都有所不同,具體詳情請看用于SQL Server的Debezium連接器.
總之能看到變動就說明調試成功。
關于如何進行kafka connector 監聽sqlserver的嘗試問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





