溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
MySQL中如何實現聚集索引,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
在MySQL里,聚集索引和非聚集索引分別是什么意思,有什么區別?
在MySQL中,InnoDB引擎表是(聚集)索引組織表(clustered index organize table),而MyISAM引擎表則是堆組織表(heap organize table)。
也有人把聚集索引稱為聚簇索引。
當然了,聚集索引的概念不是MySQL里特有的,其他數據庫系統也同樣有。
簡言之,聚集索引是一種索引組織形式,索引的鍵值邏輯順序決定了表數據行的物理存儲順序,而非聚集索引則就是普通索引了,僅僅只是對數據列創建相應的索引,不影響整個表的物理存儲順序。
我們先來看看兩種存儲形式的不同之處:
簡單說,IOT表里數據物理存儲順序和主鍵索引的順序一致,所以如果新增數據是離散的,會導致數據塊趨于離散,而不是趨于順序。而HOT表數據寫入的順序是按寫入時間順序存儲的。
IOT表相比HOT表的優勢是:
范圍查詢效率更高;
數據頻繁更新(聚集索引本身不更新)時,更不容易產生碎片;
特別適合有一小部分熱點數據頻繁讀寫的場景;
通過主鍵訪問數據時快速可達;
IOT表的不足則有:
數據變化如果是離散為主的話,那么效率會比HOT表差;
HOT表的不足有:
索引回表讀開銷很大;
大部分數據讀取時隨機的,無法保證被順序讀取,開銷大;
每張InnoDB表只能創建一個聚集索引,聚集索引可以由一列或多列組成。
上面說過,InnoDB是聚集索引組織表,它的聚集索引選擇規則是這樣的:
首先選擇顯式定義的主鍵索引做為聚集索引;
如果沒有,則選擇***個不允許NULL的***索引;
還是沒有的話,就采用InnoDB引擎內置的ROWID作為聚集索引;
我們來看看InnoDB主鍵索引的示意圖:
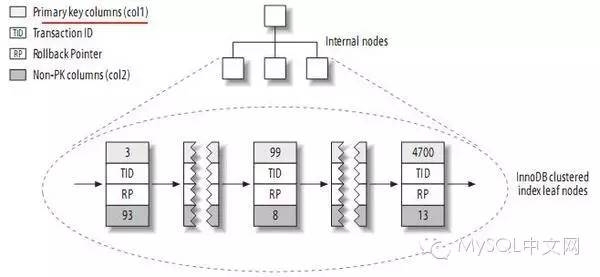
圖片來自高性能MySQL
可以看到,在這個索引結構的葉子節點中,節點key值是主鍵的值,而節點的value則存儲其余列數據,以及額外的ROWID、rollback pointer、trx id等信息。
關于MySQL中如何實現聚集索引問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





