溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何正確更換MySQL數據庫字符集,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
作為資深的DBA程序員,在工作中是否會遇到更這樣的情況呢?
原有數據庫的字符集由于前期規劃不足,隨著業務的發展不能滿足業務的需求。如原來業務系統用的是utf8字符集,后期有存儲表情符號的需求,uft8字符集就不能滿足此時的業務需求了。需要用utf8mb4字符集。
數據庫遷移,源和目標數據庫的字符集不一致,需要在遷移之前進行轉換。
更換數據庫字符集的時候明明很認(jian)真(dan),總是會出現各種各樣的問題,導致更換之后數據庫的數據出現亂碼!

今天小編就同大家一起梳理下如何正確更換數據庫的字符集,下文將簡單講解數據庫不同字符集的轉換過程。步驟轉化,杜絕亂碼!
常用字符集
GBK是國家標準GB2312基礎上擴容后兼容GB2312的標準。GBK的文字編碼是用雙字節來表示的,即不論中、英文字符均使用雙字節來表示,為了區分中文,將其***位都設定成1。GBK包含全部中文字符,是國家編碼,通用性比UTF8差,不過UTF8占用的數據庫比GBK大。支持簡體中文及繁體中文。
utf8字符集:是一種UTF-8編碼的Unicode字符集,每個字符占用1到3個字節。UTF-8包含全世界所有國家需要用到的字符,是國際編碼,通用性強。
utf8mb4字符集:是一種UTF-8編碼的Unicode字符集,每個字符占用1到4個字節。可以覆蓋BMP范圍內的字符和增補字符。BMP范圍內的字符編碼和utf8字符集中的編碼是完全相同的,長度也是完全一樣的,所以utf8mb4字符集可以兼容utf8字符集。
GB2312是GBK的子集,GBK是GB18030的子集。
big5支持繁體中文
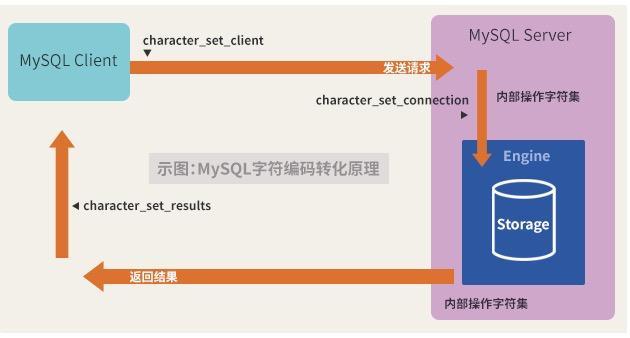
轉化過程
以下模擬的是將latin1字符集的數據庫修改成GBK的過程 。其他字符集的轉換過程類似。需要注意的是要轉換的目標字符集一定是源字符集的超級或者目標字符集的范圍包含源字符集的范圍。
1. 導表結構
mysqldump -uroot -p --default-character-set=gbk -d databasename >createtb.sql
其中--default-character-set=gbk表示設置以什么字符集連接,-d表示只導出表結構,不導出數據。
2. 手工修改createtb.sql中表結構定義中的字符集為新的字符集。
3. 確保記錄不再更新,導出所有記錄
mysqldump -root -p --quick --no-create-info --extended-insert --default-character-set=latin1 databasename>data.sql
quick:該選項用于轉儲大的表。它強制mysqldump從服務器一次一行地檢索表中的行而不是所有的行,并在輸出前將它緩沖到內存中。
extended-insert:使用包括幾個values列表的多行insert語法。這樣使轉儲文件更小,重載文件時可以加速插入。
no-create-info:不導出每個轉儲表的create table語句。
default-character-set=latin1:按照原有的字符集導出所有數據。這樣導出的文件中,所有中文都是可見的,不會保存成亂碼。
4. 打開data.sql,將set names latin1修改成set names bgk.
5. 使用新的字符集創建新的數據庫。
create database databasename default charset bgk;
6. 創建表,執行createtab.sql
mysql -root -p databasename <createtb.sql
7. 導入數據,執行data.sql
mysql -root -p databasename <data.sql
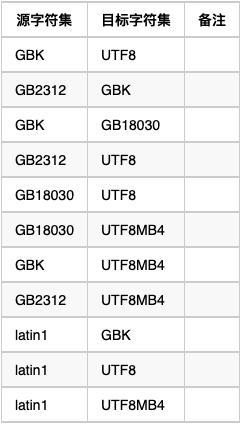
總結
新的字符集一定要是原字符集的超集,不然轉化之后,數據會出現亂碼。常見字符集轉換如下:
關于如何正確更換MySQL數據庫字符集就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





