溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹如何用Spark機器學習數據流水線進行廣告檢測,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
我們Spark的其它機器學習API,名為Spark ML,如果要用數據流水線來開發大數據應用程序的話,這個是推薦的解決方案。
Spark ML(spark.ml)包提供了構建在DataFrame之上的機器學習API,它已經成了Spark SQL庫的核心部分。這個包可以用于開發和管理機器學習流水線。它也可以提供特征抽取器、轉換器、選擇器,并支持分類、匯聚和分簇等機器學習技術。這些全都對開發機器學習解決方案至關重要。
在這里我們看看如何使用Apache Spark來做探索式數據分析(Exploratory Data Analysis)、開發機器學習流水線,并使用Spark ML包中提供的API和算法。
因為支持構建機器學習數據流水線,Apache Spark框架現在已經成了一個非常不錯的選擇,可以用于構建一個全面的用例,包括ETL、指量分析、實時流分析、機器學習、圖處理和可視化等。
機器學習數據流水線
機器學習流水線可以用于創建、調節和檢驗機器學習工作流程序等。機器學習流水線可以幫助我們更加專注于項目中的大數據需求和機器學習任務等,而不是把時間和精力花在基礎設施和分布式計算領域上。它也可以在處理機器學習問題時幫助我們,在探索階段我們要開發迭代式功能和組合模型。
機器學習工作流通常需要包括一系列的處理和學習階段。機器學習數據流水線常被描述為一種階段的序列,每個階段或者是一個轉換器模塊,或者是個估計器模塊。這些階段會按順序執行,輸入數據在流水線中流經每個階段時會被處理和轉換。
機器學習開發框架要支持分布式計算,并作為組裝流水線模塊的工具。還有一些其它的構建數據流水線的需求,包括容錯、資源管理、可擴展性和可維護性等。
在真實項目中,機器學習工作流解決方案也包括模型導入導出工具、交叉驗證來選擇參數、為多個數據源積累數據等。它們也提供了一些像功能抽取、選擇和統計等的數據工具。這些框架支持機器學習流水線持久化來保存和導入機器學習模型和流水線,以備將來使用。
機器學習工作流的概念和工作流處理器的組合已經在多種不同系統中越來越受歡迎。象scikit-learn和GraphLab等大數據處理框架也使用流水線的概念來構建系統。
一個典型的數據價值鏈流程包括如下步驟:
發現
注入
處理
保存
整合
分析
展示
機器學習數據流水線所用的方法都是類似的。下圖展示了在機器學習流水線處理中涉及到的不同步驟。

表一:機器學習流水線處理步驟
這些步驟也可以用下面的圖一表示。
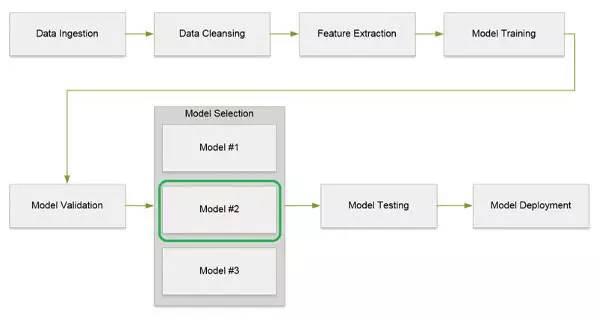
圖一:機器學習數據流水線處理流圖
接下來讓我們一起看看每個步驟的細節。
數據注入:我們收集起來供給機器學習流水線應用程序的數據可以來自于多種數據源,數據規模也是從幾百GB到幾TB都可以。而且,大數據應用程序還有一個特征,就是注入不同格式的數據。
數據清洗:數據清洗這一步在整個數據分析流水線中是***步,也是至關重要的一步,也可以叫做數據清理或數據轉換,這一步主要是要把輸入數據變成結構化的,以方便后續的數據處理和預測性分析。依進入到系統中的數據質量不同,總處理時間的60%-70%會被花在數據清洗上,把數據轉成合適的格式,這樣才能把機器學習模型應用到數據上。
數據總會有各種各樣的質量問題,比如數據不完整,或者數據項不正確或不合法等。數據清洗過程通常會使用各種不同的方法,包括定制轉換器等,用流水線中的定制的轉換器去執行數據清洗動作。
稀疏或粗粒數據是數據分析中的另一個挑戰。在這方面總會發生許多極端案例,所以我們要用上面講到的數據清洗技術來保證輸入到數據流水線中的數據必須是高質量的。
伴隨著我們對問題的深入理解,每一次的連續嘗試和不斷地更新模型,數據清洗也通常是個迭代的過程。象Trifacta、OpenRefine或ActiveClean等數據轉換工具都可以用來完成數據清洗任務。
特征抽取:在特征抽取(有時候也叫特征工程)這一步,我們會用特征哈希(Hashing Term Frequency)和Word2Vec等技術來從原始數據中抽取具體的功能。這一步的輸出結果常常也包括一個匯編模塊,會一起傳入下一個步驟進行處理。
模型訓練:機器學習模型訓練包括提供一個算法,并提供一些訓練數據讓模型可以學習。學習算法會從訓練數據中發現模式,并生成輸出模型。
模型驗證:這一步包評估和調整機器學習模型,以衡量用它來做預測的有效性。如這篇文章所說,對于二進制分類模型評估指標可以用接收者操作特征(Receiver Operating Characteristic,ROC)曲線。ROC曲線可以表現一個二進制分類器系統的性能。創建它的方法是在不同的閾值設置下描繪真陽性率(True Positive Rate,TPR)和假陽性率(False Positive Rate,FPR)之間的對應關系。
模型選擇:模型選擇指讓轉換器和估計器用數據去選擇參數。這在機器學習流水線處理過程中也是關鍵的一步。ParamGridBuilder和CrossValidator等類都提供了API來選擇機器學習模型。
模型部署:一旦選好了正確的模型,我們就可以開始部署,輸入新數據并得到預測性的分析結果。我們也可以把機器學習模型部署成網頁服務。
Spark機器學習
機器學習流水線API是在Apache Spark框架1.2版中引入的。它給開發者們提供了API來創建并執行復雜的機器學習工作流。流水線API的目標是通過為不同機器學習概念提供標準化的API,來讓用戶可以快速并輕松地組建并配置可行的分布式機器學習流水線。流水線API包含在org.apache.spark.ml包中。
Spark ML也有助于把多種機器學習算法組合到一條流水線中。
Spark機器學習API被分成了兩個包,分別是spark.mllib和spark.ml。其中spark.ml包包括了基于RDD構建的原始API。而spark.ml包則提供了構建于DataFrame之上的高級API,用于構建機器學習流水線。
基于RDD的MLlib庫API現在處于維護模式。
如下面圖二所示,Spark ML是Apache Spark生態系統中的一個非常重要的大數據分析庫。
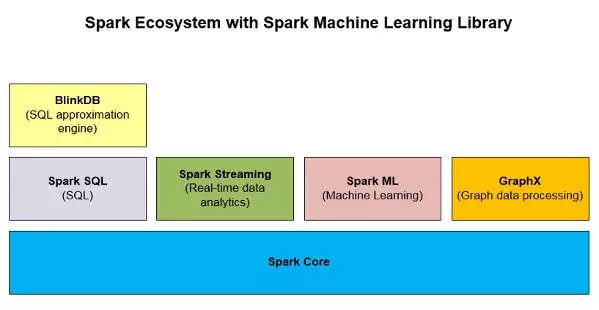
圖二:包括了Spark ML的Spark生態系統
機器學習流水線模塊
機器學習數據流水線包括了完成數據分析任務所需要的多個模塊。數據流水線的關鍵模塊被列在了下面:
數據集
流水線
流水線的階段
轉換器
估計器
評估器
參數(和參數地圖)
接下來我們簡單看看這些模塊可以怎么對應到整體的步驟中。
數據集:在機器學習流水線中是使用DataFrame來表現數據集的。它也允許按有名字的字段保存結構化數據。這些字段可以用于保存文字、功能向量、真實標簽和預測。
流水線:機器學習工作流被建模為流水線,這包括了一系列的階段。每個階段都對輸入數據進行處理,為下一個階段產生輸出數據。一個流水線把多個轉換器和估計器串連起來,描述一個機器學習工作流。
流水線的階段:我們定義兩種階段,轉換器和估計器。
轉換器:算法可以把一個DataFrame轉換成另一個DataFrame。比如,機器學習模型就是一個轉換器,用于把一個有特征的DataFrame轉換成一個有預測信息的DataFrame。
轉換器會把一個DataFrame轉成另一個DataFrame,同時為它加入新的特征。比如在Spark ML包中,OneHotEncoder就會把一個有標簽索引的字段轉換成一個有向量特征的字段。每個轉換器都有一個transform()函數,被調用時就會把一個DataFrame轉換成另一個。
估計器:估計器就是一種機器學習算法,會從你提供的數據中進行學習。估計器的輸入是一個DataFrame,輸出就是一個轉換器。估計器用于訓練模型,它生成轉換器。比如,邏輯回歸估計器就會產生邏輯回歸轉換器。另一個例子是把K-Means做為估計器,它接受訓練數據,生成K-Means模型,就是一個轉換器。
參數:機器學習模塊會使用通用的API來描述參數。參數的例子之一就是模型要使用的***迭代次數。
下圖展示的是一個用作文字分類的數據流水線的各個模塊。
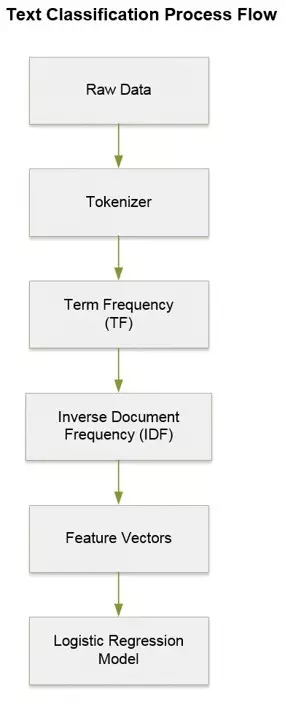
圖三:使用Spark ML的數據流水線
用例
機器學習流水線的用例之一就是文字分類。這種用例通常包括如下步驟:
清洗文字數據
將數據轉化成特征向量,并且
訓練分類模型
在文字分類中,在進行分類模型(類似SVM)的訓練之前,會進行n-gram抽象和TF-IDF特征權重等數據預處理。
另一個機器學習流水線用例就是在這篇文章中描述的圖像分類。
還有很多種其它機器學習用例,包括欺詐檢測(使用分類模型,這也是監督式學習的一部分),用戶分區(聚簇模型,這也是非監督式學習的一部分)。
TF-IDF
詞頻-逆向文檔頻率(Term Frequency - Inverse Document Frequency,TF-IDF)是一種在給定樣本集合內評估一個詞的重要程度的靜態評估方法。這是一種信息獲取算法,用于在一個文檔集合內給一個詞的重要性打分。
TF:如果一個詞在一份文檔中反復出現,那這個詞就比較重要。具體計算方法為:
TF = (# of times word X appears in a document) / (Total # of
words in the document)
IDF:但如果一個詞在多份文檔中都頻繁出現(比如the,and,of等),那就說明這個詞沒有什么實際意義,因此就要降低它的評分。
示例程序
下面我們看個示例程序,了解一下Spark ML包可以怎樣用在大數據處理系統中。我們會開發一個文檔分類程序,用于區別程序輸入數據中的廣告內容。測試用的輸入數據集包括文檔、電子郵件或其它任何從外部系統中收到的可能包含廣告的內容。
我們將使用在Strata Hadoop World Conference研討會上討論的“用Spark構建機器學習應用”的廣告檢測示例來構建我們的示例程序。
用例
這個用例會對發送到我們的系統中的各種不同消息進行分析。有些消息里面是含有廣告信息的,但有些消息里面沒有。我們的目標就是要用Spark ML API找出那些包含了廣告的消息。
算法
我們將使用機器學習中的邏輯回歸算法。邏輯回歸是一種回歸分析模型,可以基于一個或多個獨立變量來預測得到是或非的可能結果。
詳細的解決方案
接下來咱們看看這個Spark ML示例程序的細節,以及運行步驟。
數據注入:我們會把包含廣告的數據(文本文件)和不包含廣告的數據都導入。
數據清洗:在示例程序中,我們不做任何特別的數據清洗操作。我們只是把所有的數據都匯聚到一個DataFrame對象中。
我們隨機地從訓練數據和測試數據中選擇一些數據,創建一個數組對象。在這個例子中我們的選擇是70%的訓練數據,和30%的測試數據。
在后續的流水線操作中我們分別用這兩個數據對象來訓練模型和做預測。
我們的機器學習數據流水線包括四步:
Tokenizer
HashingTF
IDF
LR
創建一個流水線對象,并且在流水線中設置上面的各個階段。然后我們就可以按照例子,基于訓練數據來創建一個邏輯回歸模型。
現在,我們再使用測試數據(新數據集)來用模型做預測。
下面圖四中展示了例子程序的架構圖。
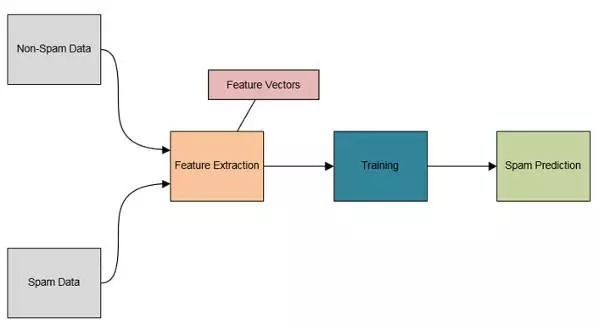
圖4:數據分類程序架構圖
技術
在實現機器學習流水線解決方案時我們用到了下面的技術。
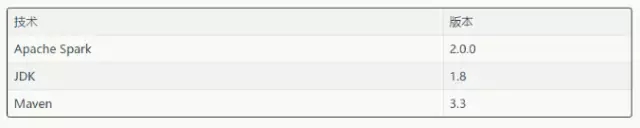
表二:在機器學習例子中用到的技術和工具
Spark ML程序
根據研討會上的例子而寫成的機器學習代碼是用Scala編程語言寫的,我們可以直接使用Spark Shell控制臺來運行這個程序。
廣告檢測Scala代碼片段:
***步:創建一個定制的類,用來存儲廣告內容的細節。
case class SpamDocument(file: String, text: String, label: Double)
第二步:初始化SQLContext,并通過隱式轉換方法來把Scala對象轉換成DataFrame。然后從存放著輸入文件的指定目錄導入數據集,結果會返回RDD對象。然后由這兩個數據集的RDD對象創建DataFrame對象。
val sqlContext = new SQLContext(sc) import sqlContext.implicits._ // // Load the data files with spam // val rddSData = sc.wholeTextFiles("SPAM_DATA_FILE_DIR", 1) val dfSData = rddSData.map(d => SpamDocument(d._1, d._2,1)).toDF() dfSData.show() // // Load the data files with no spam // val rddNSData = sc.wholeTextFiles("NO_SPAM_DATA_FILE_DIR", 1) val dfNSData = rddNSData.map(d => SpamDocument(d._1,d._2, 0)).toDF() dfNSData.show()第三步:現在,把數據集匯聚起來,然后根據70%和30%的比例來把整份數據拆分成訓練數據和測試數據。
// // Aggregate both data frames // val dfAllData = dfSData.unionAll(dfNSData) dfAllData.show() // // Split the data into 70% training data and 30% test data // val Array(trainingData, testData) = dfAllData.randomSplit(Array(0.7, 0.3))
第四步:現在可以配置機器學習數據流水線了,要創建我們在文章前面部分討論到的幾個部分:Tokenizer、HashingTF和IDF。然后再用訓練數據創建回歸模型,在這個例子中是邏輯回歸。
// // Configure the ML data pipeline // // // Create the Tokenizer step // val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") // // Create the TF and IDF steps // val hashingTF = new HashingTF() .setInputCol(tokenizer.getOutputCol) .setOutputCol("rawFeatures") val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features") // // Create the Logistic Regression step // val lr = new LogisticRegression() .setMaxIter(5) lr.setLabelCol("label") lr.setFeaturesCol("features") // // Create the pipeline // val pipeline = new Pipeline() .setStages(Array(tokenizer, hashingTF, idf, lr)) val lrModel = pipeline.fit(trainingData) println(lrModel.toString())第五步:***,我們調用邏輯回歸模型中的轉換方法來用測試數據做預測。
// // Make predictions. // val predictions = lrModel.transform(testData) // // Display prediction results // predictions.select("file", "text", "label", "features", "prediction").show(300)Spark機器學習庫是Apache Spark框架中最重要的庫之一。它用于實現數據流水線。在這篇文章中,我們了解了如何使用Spark ML包的API以及用它來實現一個文本分類用例。
圖數據模型是關于在數據模型中不同的實體之間的連接和關系的。圖數據處理技術最近受到了很多關注,因為可以用它來解決許多問題,包括欺詐檢測和開發推薦引擎等。
關于如何用Spark機器學習數據流水線進行廣告檢測就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





