溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Spark 可以讀取文本,csv和rmdb中的數據,并且帶有類型自動檢測功能
public final static String DATA_SEPARATOR_TAB = "\t";
session.read().format("csv").option("delimiter", Constants.DATA_SEPARATOR_TAB).option("inferSchema", "true").option("header", "true").option("encoding", charset).csv(path).toDF(columnNames).write().mode(mode).saveAsTable(tempTable);
紅色屬性決定spark是否自動探測數據類型,如果不開啟自動探測,默認都是string
rdbms導入到spark中默認會類型探測和對應,但是在處理sqlserver的時間類型有問題
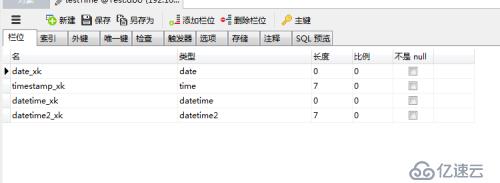
如上圖所示
只有datetime可以被spark識別并存儲為日期類型,其他的都落地成了String類型,所以在執行data_formate時因為要多做一步轉換所以性能會差很多
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





