溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹MySQL索引有哪些法則,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一、最佳左前綴法則
1. 定義
在創建了多列索引的情況下,查詢從索引的最左前列開始且不能跳過索引中的列。
最佳左前綴法則就是說如果創建了多個索引,在使用索引時要按照創建索引的順序來使用,不能缺少或跳過,當然如果只使用最左邊的索引列,也就是第一個索引是可以的。
2. 環境準備
DROP TABLE IF EXISTS `tb_emp`; CREATE TABLE `tb_emp` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) NOT NULL, `age` int(11) NOT NULL, gender varchar(10) NOT NULL, email varchar(20), PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; INSERT INTO `tb_emp` (name,age,gender,email) VALUES ('Tom', '22','male','1@qq.com'); INSERT INTO `tb_emp` (name,age,gender,email) VALUES ('Mary', '21','female','2@qq.com'); INSERT INTO `tb_emp` (name,age,gender,email) VALUES ('Jack', '27','male','3@qq.com'); INSERT INTO `tb_emp` (name,age,gender,email) VALUES ('Rose', '23','female','4@qq.com');3. 創建組合索引
create index idx_all on tb_emp(name,age,gender); show index from tb_emp;

這里用火車頭代表name,車廂代表age,車尾代表gender。
4. 只有火車頭
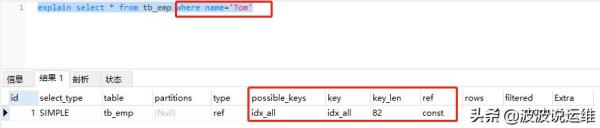
說明:
索引的創建順序為name,age,gender;
直接使用name(火車頭)作為條件,可以看到type=ref,key_len=82,ref=const,效果還行。
5. 只有車廂
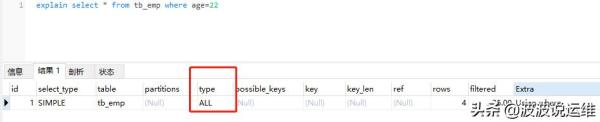
說明:沒使用火車頭(name),直接用車廂,導致走全表掃描(type=ALL)
6. 火車頭加車廂、火車頭加車尾
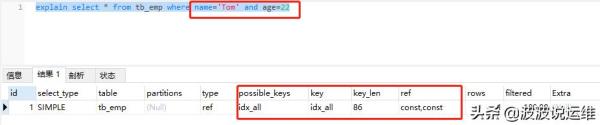

說明:
火車頭加車廂、火車頭加車尾,雖然都是type=ref,但是觀察key_len和ref兩項,并對比只有火車頭中的結果,可得出在使用火車頭(name)和車尾(gender)時,只使用了部分索引也就是火車頭(name)的索引。
通俗理解:火車頭單獨跑沒問題,火車頭與直接相連的車廂一起跑也沒問題,但是火車頭與車尾,如果中間沒有車廂,只能火車頭自己跑。
7. 火車頭加車廂加車尾

說明:火車頭加車廂加車尾,三者串聯,就變成了奔跑的小火車。type=ref,key_len=128,ref=const,const,const。
二、索引列不做計算
在索引列上做任何操作(計算、函數、(自動or手動)類型轉換),會導致索引失效從而轉向全表掃描。
1. 函數計算

說明:這里使用了函數計算,type=ALL,導致索引失效。
2. 隱式類型轉換

說明:這里'123'是字符串,而123是數字,發生了隱式類型轉換,導致全表掃描(type=ALL)
三、范圍右邊索引列全失效
存儲引擎不能使用索引中范圍右邊的列,也就是說范圍右邊的索引列會失效。
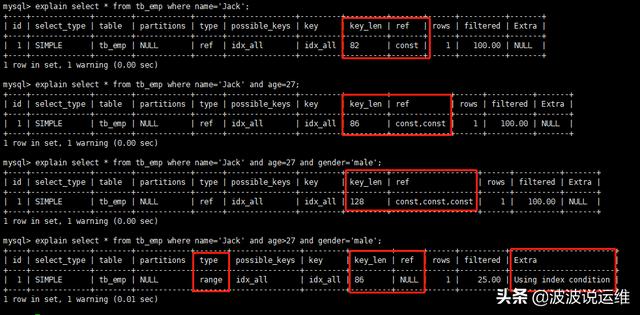
對以上4個SQL進行分析:
條件單獨使用name時,type=ref,key_len=82,ref=const。
條件加上age時(使用常量等值),type=ref,key_len=86,ref=const,const。
當全值匹配時,type=ref,key_len=128,ref=const,const,const。說明索引全部用上,從key_len與ref可以看出。
當使用范圍時(age>27),type=range,key_len=86,ref=Null,可以看到只使用了部分索引,但gender索引沒用上。
結論:范圍右邊的索引列失效。
四、盡量使用覆蓋索引
1. 覆蓋索引定義
如果一個索引包含(或覆蓋)所有需要查詢的字段的值,稱為‘覆蓋索引’。即只需掃描索引而無須回表。
只掃描索引而無需回表的優點:
索引條目通常遠小于數據行大小,只需要讀取索引,則mysql會極大地減少數據訪問量。
因為索引是按照列值順序存儲的,所以對于IO密集的范圍查找會比隨機從磁盤讀取每一行數據的IO少很多。
一些存儲引擎如myisam在內存中只緩存索引,數據則依賴于操作系統來緩存,因此要訪問數據需要一次系統調用
innodb的聚簇索引,覆蓋索引對innodb表特別有用。(innodb的二級索引在葉子節點中保存了行的主鍵值,所以如果二級主鍵能夠覆蓋查詢,則可以避免對主鍵索引的二次查詢)
覆蓋索引必須要存儲索引列的值,而哈希索引、空間索引和全文索引不存儲索引列的值,所以mysql只能用B-tree索引做覆蓋索引。
當發起一個索引覆蓋查詢時,在explain的extra列可以看到using index的信息
2. 對比是否使用覆蓋索引好處
盡量使用覆蓋索引(查詢列和索引列盡量一致,通俗說就是對A、B列創建了索引,然后查詢中也使用A、B列),減少select *的使用。
mysql> explain select * from tb_emp where name='Jack' and age=27 and gender='male'; mysql> explain select name,age,gender from tb_emp where name='Jack' and age=27 and gender='male';
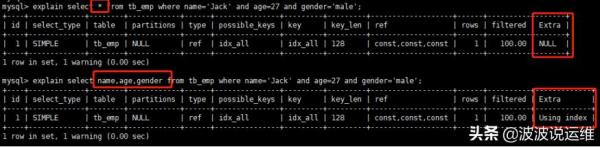
說明:對比兩個sql,第一個使用select *,第二個使用覆蓋索引(查詢列與條件列對應),可看到Extra從Null變成了Using index,提高檢索效率。
關于MySQL索引有哪些法則就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





