溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“R語言可視化UpSetR包怎么使用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
今天介紹一個R包UpSetR,專門用來集合可視化,來源于UpSet,Python里面也有一個相似的包py-upset。此外還有個UpSetR shiny app以及源代碼。
安裝
兩種方式安裝:
#從CRAN安裝 install.packages("UpSetR") #從Github上安裝 devtools::install_github("hms-dbmi/UpSetR")數據導入
UpSetR提供了兩個函數fromList以及fromExpression將數據轉換為UpsetR適用的數據格式。
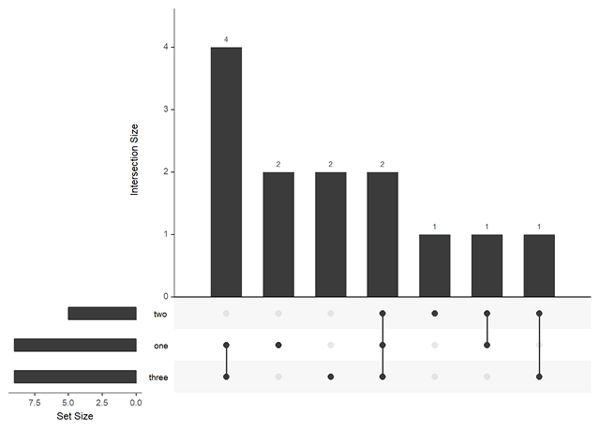
#fromList listinput <- list(one = c(1, 2, 3, 5, 7, 8, 11, 12, 13), two = c(1, 2, 4, 5, 10), three = c(1, 5, 6, 7, 8, 9, 10, 12, 13)) #fromExpression expressionInput <- c(one = 2, two = 1, three = 2, `one&two` = 1, `one&three` = 4, `two&three` = 1, `one&two&three` = 2)
接下來就可以繪制繪制圖形了
library(UpSetR) upset(fromList(listinput), order.by = "freq") #下面繪制的圖形等同于上圖 upset(fromExpression(expressionInput), order.by = "freq")
參數詳解
下面所有的例子都將使用UpSetR內置的數據集movies來繪制。
#導入數據 movies <- read.csv(system.file("extdata", "movies.csv", package = "UpSetR"), header = TRUE, sep = ";") #先大致瀏覽一下該數據集,數據集太長,就只看前幾列 knitr::kable(head(movies[,1:10])) 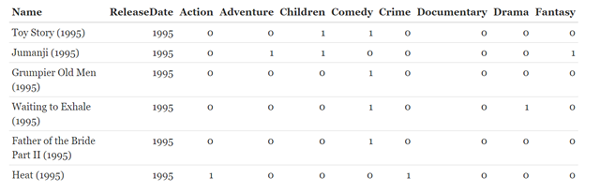
該數據集展示的是電影名(name)、發行時間(ReleaseDate)以及電影類型,多了去了就不詳講了,自個可以看去。
UpsetR繪制集合可視化圖形使用函數upset()。
upset(movies, nsets = 6, number.angles = 30, point.size = 2, line.size = 1, mainbar.y.label = "Genre Intersections", sets.x.label = "Movies Per Genre", text.scale = c(1.3, 1.3, 1, 1, 1.5, 1))
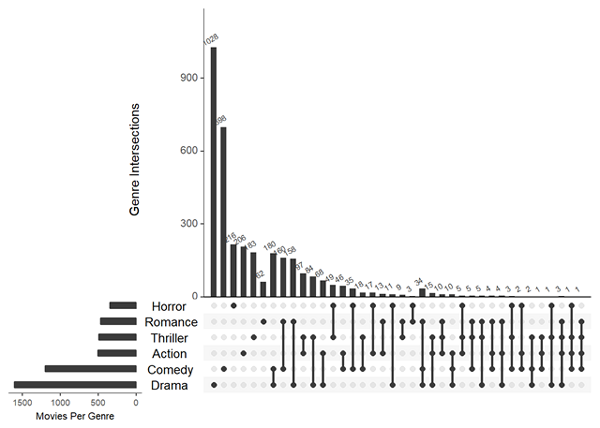
解釋一下上面部分參數:
nsets: 顧名思義,就是展示幾個集合,movies數據集由20幾個集合,不可能全部展示,另外從圖中可以看出,這6個集合應該不是按順序選擇的。
numble.angle: 柱子上的數字看到了吧,這個參數就是調整數字角度的,可有可無的
mainbar.y.label/sets.x.label:坐標軸名稱
text.scale(): 有六個數字,分別控制c(intersection size title, intersection size tick labels, set size title, set size tick labels, set names, numbers above bars)。
很多時候我們想要看特定的幾個集合,UpSetR滿足我們的需求。
upset(movies, sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery", "Thriller", "Romance", "War", "Western"), mb.ratio = c(0.55, 0.45), order.by = "freq") 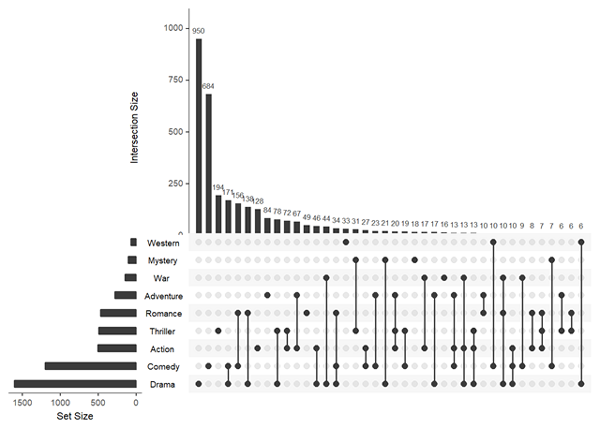
文中的參數:
mb.ratio: 控制上方條形圖以及下方點圖的比例
order.by: 如何排序,這里freq表示從大到小排序展示,其他選項有degree以及先按freq再按degree排序。
各個變量也可以通過參數keep.order來排序
upset(movies, sets = c("Action", "Adventure", "Comedy", "Drama", "Mystery", "Thriller", "Romance", "War", "Western"), mb.ratio = c(0.55, 0.45), order.by = "freq", keep.order = TRUE) 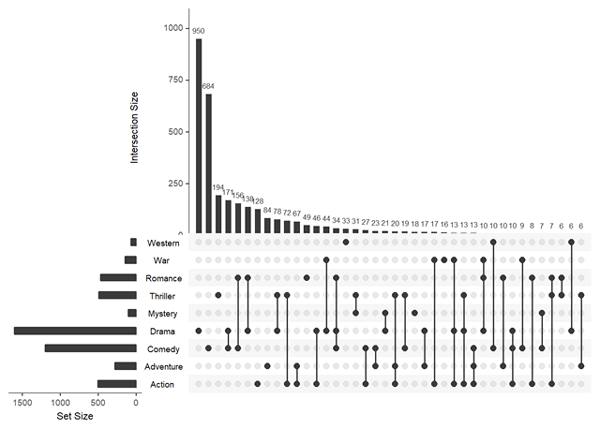
也可以按group進行展示,這圖展示的就是按各個變量自身、兩個交集、三個交集…依次展示。參數cutoff控制每個group顯示幾個交集。
參數intersects控制總共顯示幾個交集。
upset(movies, nintersects = 70, group.by = "sets", cutoff = 7)
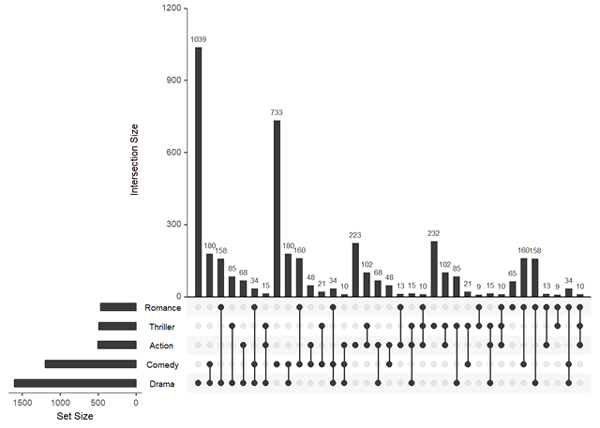
還有很多參數比如控制顏色的參數,點、線大小等,具體可查看?upset
queries參數
queries參數分為四個部分:query, param, color, active.
query: 指定哪個query,UpSetR有內置的,也可以自定義,說到底就是一個查詢函數
param: list, query作用于哪個交集
color:每個query都是一個list,里面可以設置顏色,沒設置的話將調用包里默認的調色板
active:被指定的條形圖是否需要顏色覆蓋,TRUE的話顯示顏色,FALSE的話則在條形圖頂端顯示三角形
內置的intersects query
upset(movies, queries = list(list(query=intersects, params=list("Drama", "Comedy", "Action"), color="orange", active=T), list(query=intersects, params=list("Drama"), color="red", active=F), list(query=intersects, params=list("Action", "Drama"), active=T))) 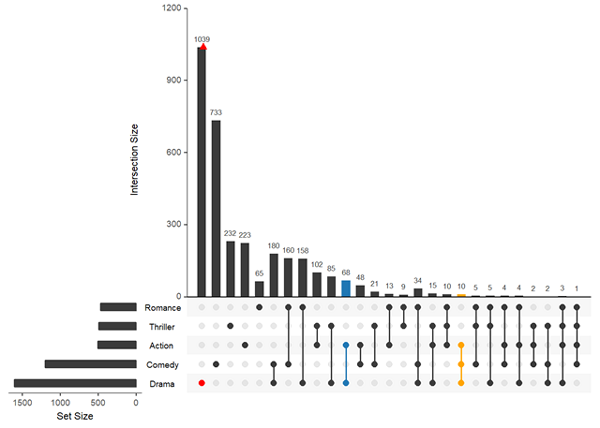
內置的elements query
此query可以可視化特定交集在不同條件下的情況
upset(movies, queries = list(list(query=elements, params=list("AvgRating", 3.5, 4.1), color="blue", active=T), list(query=elements, params=list("ReleaseDate", 1980, 1990, 2000), color="red", active=F))) 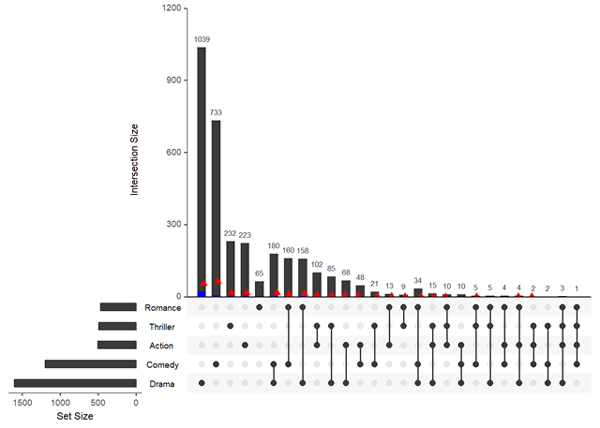
自定義一個query
myfunc <- function(row, release, rating){ newdata <- (row["ReleaseDate"]%in%release)&(row["AvgRating"]>rating) } upset(movies, queries = list(list(query=myfunc, params=list(c(1950,1960,1990,2000), 3.0), color="red", active=T))) 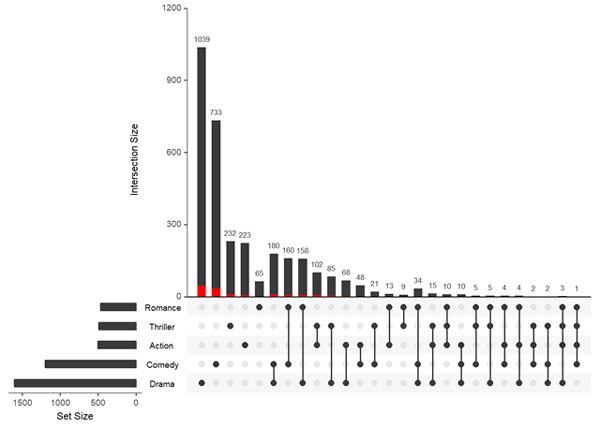
添加query圖例
upset(movies, query.legend = "top", queries = list(list(query = intersects, params = list("Drama", "Comedy", "Action"), color = "orange", active = T, query.name = "Funny action"), list(query = intersects, params = list("Drama"), color = "red", active = F), list(query = intersects, params = list("Action", "Drama"), active = T, query.name = "Emotional action"))) 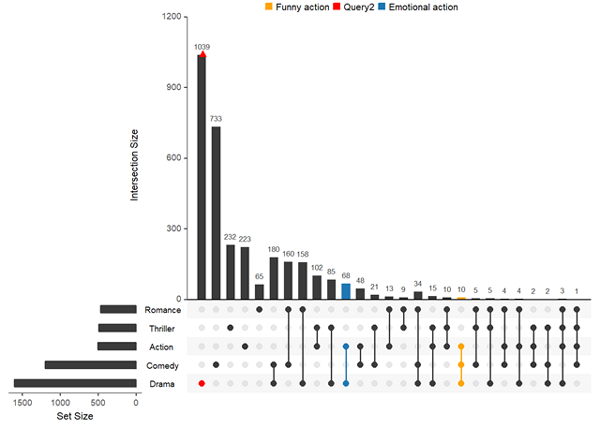
參數attribute.plots
主要是用于添加屬性圖,內置有柱形圖、散點圖、熱圖等
柱形圖
upset(movies, main.bar.color = "black", queries = list(list(query = intersects, params = list("Drama"), active = T)), attribute.plots = list(gridrows = 50, plots = list(list(plot = histogram, x = "ReleaseDate", queries = F), list(plot = histogram, x = "AvgRating", queries = T)), ncols = 2)) 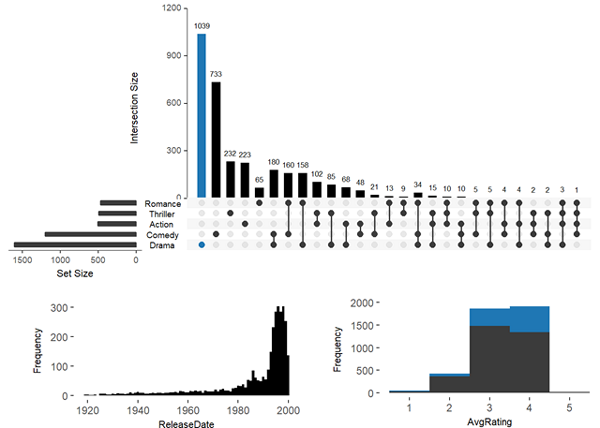
散點圖
upset(movies, main.bar.color = "black", queries = list(list(query = intersects, params = list("Drama"), color = "red", active = F), list(query = intersects, params = list("Action", "Drama"), active = T), list(query = intersects, params = list("Drama", "Comedy", "Action"), color = "orange", active = T)), attribute.plots = list(gridrows = 45, plots = list(list(plot = scatter_plot, x = "ReleaseDate", y = "AvgRating", queries = T), list(plot = scatter_plot, x = "AvgRating", y = "Watches", queries = F)), ncols = 2), query.legend = "bottom") 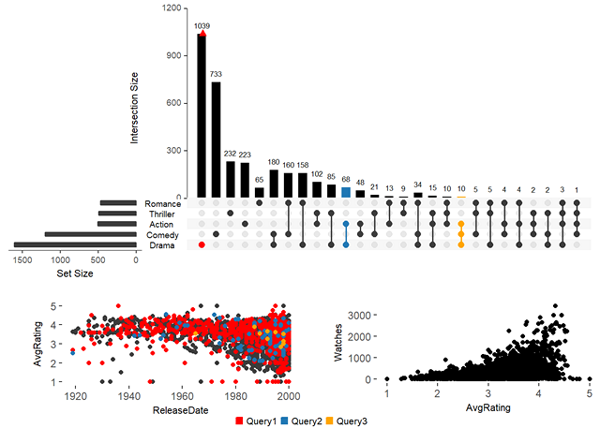
箱線圖
箱線圖可以展示數據的分布,通過參數boxplot.summary控制,最多可以一次性顯示兩個箱線圖
upset(movies, boxplot.summary = c("AvgRating", "ReleaseDate")) 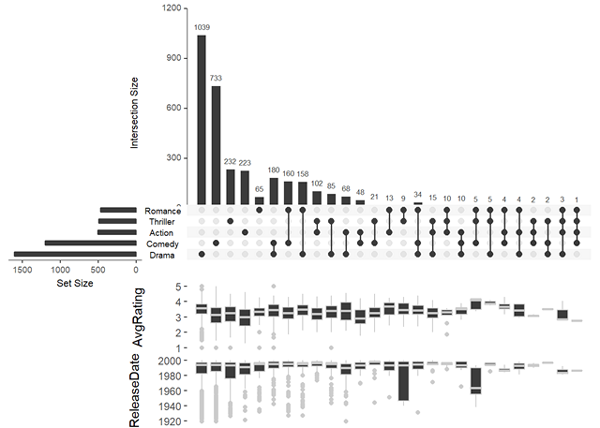
還有一個十分重要的功能Incorporating Set Metadata這里就不講了。
SessionInfo
sessionInfo() ## R version 3.4.2 (2017-09-28) ## Platform: x86_64-w64-mingw32/x64 (64-bit) ## Running under: Windows 10 x64 (build 15063) ## ## Matrix products: default ## ## locale: ## [1] LC_COLLATE=Chinese (Simplified)_China.936 ## [2] LC_CTYPE=Chinese (Simplified)_China.936 ## [3] LC_MONETARY=Chinese (Simplified)_China.936 ## [4] LC_NUMERIC=C ## [5] LC_TIME=Chinese (Simplified)_China.936 ## ## attached base packages: ## [1] stats graphics grDevices utils datasets methods base ## ## other attached packages: ## [1] UpSetR_1.3.3 ## ## loaded via a namespace (and not attached): ## [1] Rcpp_0.12.13 knitr_1.17 magrittr_1.5 munsell_0.4.3 ## [5] colorspace_1.3-2 rlang_0.1.2 stringr_1.2.0 highr_0.6 ## [9] plyr_1.8.4 tools_3.4.2 grid_3.4.2 gtable_0.2.0 ## [13] htmltools_0.3.6 yaml_2.1.14 lazyeval_0.2.0 rprojroot_1.2 ## [17] digest_0.6.12 tibble_1.3.4 gridExtra_2.3 ggplot2_2.2.1 ## [21] evaluate_0.10.1 rmarkdown_1.6 labeling_0.3 stringi_1.1.5 ## [25] compiler_3.4.2 scales_0.5.0 backports_1.1.1
“R語言可視化UpSetR包怎么使用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





